
Paperspace Gradient consists of three major parts: Notebooks, Workflows, and (soon) Deployments. While Notebooks are designed primarily for exploratory work, Workflows are designed for more a more rigorous approach that leads directly to production.
Here we demonstrate an example of using Workflows in production by using them to update our Gradient Public Datasets.
In other words, we trust our Workflows enough to use them in real production on our own product, and you can too!
Note: This blog entry is about using Workflows to update our datasets. For more details on the datasets themselves, and Workflows, see here and here.
What are Gradient Public Datasets?
Gradient is designed to get people up and running quickly and easily with AI and machine learning, including deep learning and GPUs. While we want to remove the obstacles to enabling a hardware and software environment for AI, we want to make it easier to access your data too.
We achieve this by providing integrated connectivity to online data sources such as Amazon S3, the ability to run arbitrary code such as curl or wget for other data locations, and by our public datasets. Deep learning and GPUs often need large amounts of data to perform at their best, and so by making examples of this data conveniently available we lessen the barrier to users who want to get going without having to find their data, or perform a huge download.
Public datasets are accessed in the same way as your other Gradient Datasets, by pointing to their location in your code and including the Gradient namespace, so, for example, our dataset openslr is at gradient/openslr.
The datasets available in our curated public datasets collection are described in our documentation, and will be showcased here in a future blog entry.
The collection of data is constantly evolving, but at the time of writing they include StyleGAN, LSUN, Open SLR, Self Driving Demo, COCO, fast.ai, and some smaller ones such as Tiny-imagenet-200, Sentiment140, and MNIST.
See details about our public datasets and more in our docs.
What are Workflows?
As an end-to-end machine learning and MLOps platform, Workflows are Gradient's pathway for moving from exploratory data science into production.
Workflows are contained within Projects, a workspace for you or your team to run Notebooks and Workflows, store Models, and manage Deployments. Each Workflow consists of a set of jobs that are run in sequence. Jobs can be related to each other in a graph-like fashion, and can in turn call other scripts such as a Python .py. This lets you create a pipeline of processing steps that is 100% specified, portable, and reproducible.
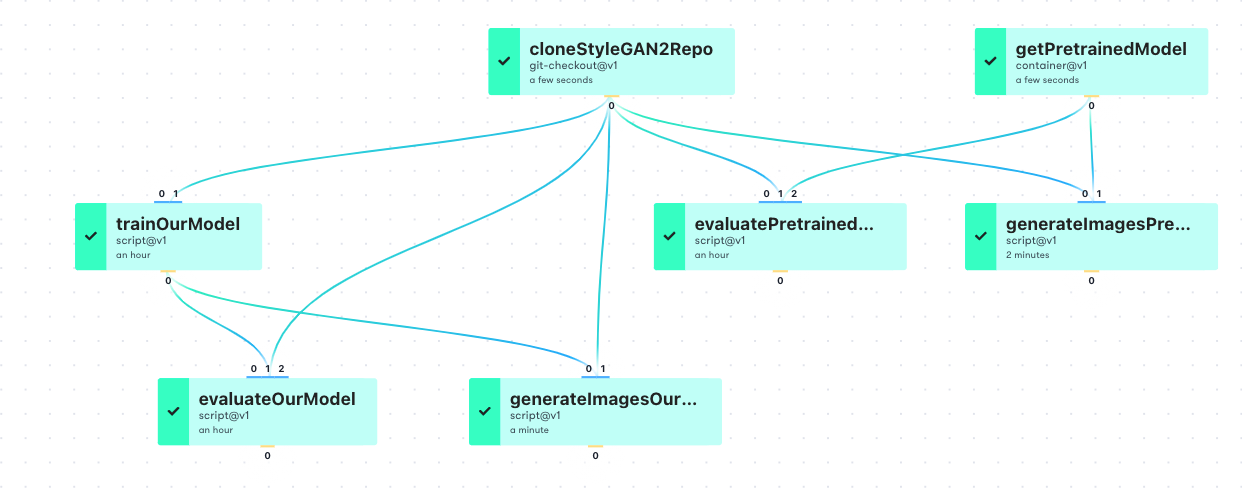
In the example, from a different project to this one, the cloneStyleGAN2Repo and getPretrainedModel jobs feed into the train, evaluate, and generate jobs. Each job that feeds into another is required to finish before the subsequent jobs can start, but jobs such as, e.g., trainOurModel and evaluatePretrainedModel can run in parallel, provided (in this case) cloneStyleGAN2Repo succeeds.
We can also view the same Workflow with Datasets included:
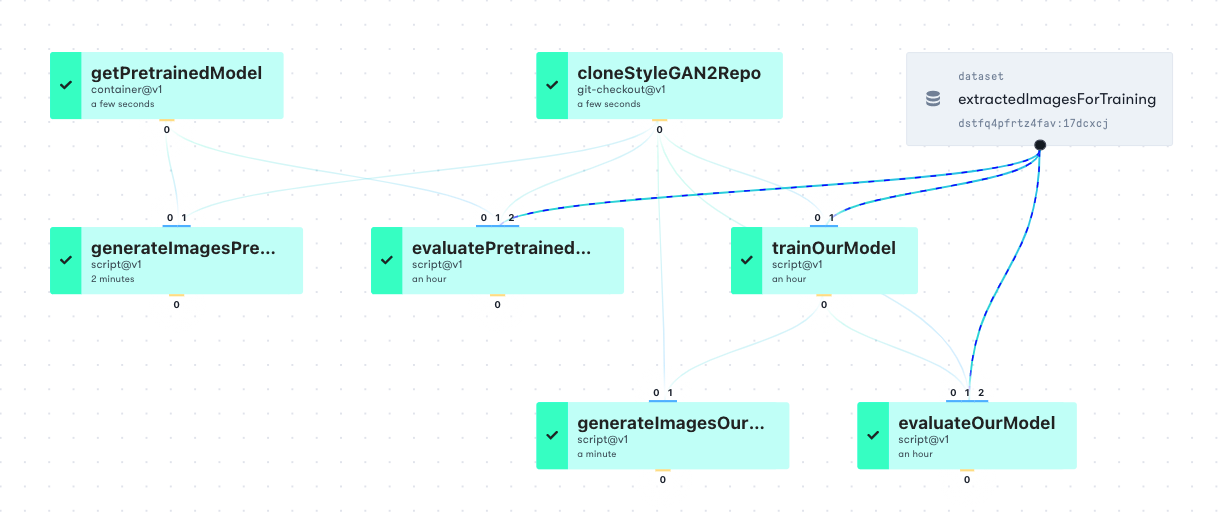
The Workflow itself is specified using YAML, which gives the required level of rigor for a production system. Some users may be less familiar with YAML, and so we provide some help with it to get you where you need to be.
To run a Workflow, you can run the YAML with the Gradient CLI, and it will show up in the GUI as above. The YAML itself is in a file, and consists of information to specify what compute resources to run the Workflow on, the jobs and their interrelationship, and the sort of operation that each job is performing.
This latter step is achieved by using Gradient Actions. These are similar to GitHub Actions, but Gradient Actions support running jobs in parallel and using large data. There are several actions, but for our purposes here the most important is script@v1, which allows us to execute a set of commands within a job, as in a script.
For more details on Gradient Actions in a Workflow, go to the Workflows section of the docs.
Bring this project to life
Using Workflows to update our Public Datasets
So why do we need to update our public datasets? Previously, rather than Workflows, Gradient supported Notebooks and Experiments. The latter were designed for model training, are now deprecated, and have been superseded by Workflows. This previous setup, however, accessed datasets by pointing to the common /datasets directory that is on Gradient's managed storage. So now we need to be able to access them in the Gradient dataset namespace that Workflows can see, as in the gradient/openslr example above.
Why not just copy them over? Well, in principle we could by connecting the right filesystems, but using Workflows to update them provides several advantages:
- Using Workflows establishes provenance and reproducibility for where our public datasets came from
- It's easy to rerun and update them in future
- New public datasets can be added by adding new Workflows
- Workflows are in Projects, and Projects can be linked to GitHub repositories, so we can easily maintain versioning, and ancillary information such as dataset licensing
- Since the resulting created datasets are part of our product, it shows an example of our Workflows being used for an enterprise production purpose
Therefore, to update a public dataset, we run Workflows that look like this:
defaults:
resources:
instance-type: C7
jobs:
downloadData:
outputs:
openslr:
type: dataset
with:
ref: gradient/openslr
uses: script@v1
with:
script: |-
...
curl -o /outputs/openslr/original-mp3.tar.gz \
'https://www.openslr.org/resources/12/original-mp3.tar.gz'
...
cd /outputs/openslr
...
md5sum original-mp3.tar.gz
...
tar -zxf original-mp3.tar.gz
...
image: ubuntu:18.04
The Workflow is downloading the data from the original source, and placing it in the Gradient Public Dataset, in this case, gradient/openslr. Each Workflow run produces an explicit version of the dataset, whose ID is available, but the overall Datasets can be referred to by name.
Several details about our Workflows are visible in the code shown:
- The compute resource to use is specified by
resources, here being a C7 CPU instance on the Gradient Cloud. GPU instances, e.g. P4000 or V100, can be accessed in the same way. - There is one job,
downloadData, which is listed under the main part of the Workflow,jobs. Specifications such asresourcescan be job-specific as well as the global example we use here, meaning that you can specify, say, a GPU only for the jobs that need it. A Workflow can contain several jobs. - The job output, referred to as
openslrin this case, is of typedataset, and its location (ref) isgradient/openslr. Gradient has several types of inputs and outputs that can be specified by types or actions, including mounted volumes, Git repositories, machine learning models, and Amazon S3 buckets. - The Gradient Action
script@v1allows us to issue arbitrary commands as would be done at the terminal, in the form of a script. They are given after thescript: |-line. - The data here is hosted online at a website under openslr.org, so we download them using curl. If the connection were unreliable, a loop plus the -C option can be used to resume a partially completed download. This can come in handy for large files (the one in the example is 82 gigabytes, and our largest so far is 206 gigabytes).
- The downloaded data are placed in the
/outputs/openslrdirectory. When the directory under/outputshas the same name as the name given underoutputs:, the contents of the directory are placed in the job output, in this case the public dataset. - Since any code is allowed, we can perform other useful steps related to obtaining large datasets, such as
md5sum, and file extraction, in this casetar -zxf. - The
image: ubuntu:18.04line tells us that we are running the Workflow in a Docker container, in this case, the Ubuntu 18.04 image. In general, like Notebooks, Workflows are run on a given Docker image, orchestrated by Kubernetes, giving an environment that is convenient (many installs and setups not needed), secure, and reproducible.
Once the Workflow run is completed, because the Dataset gradient/openslr is public, it becomes available to our users.
The example shown has been for the openslr dataset. In general, we have a single Workflow for each public dataset, each one containing the exact steps needed for the data at hand. This means that each dataset can be maintained independently, and the maintenance and provenance of the data seen.
Real data have many locations that require various connection methods. Some examples encountered when updating our public datasets here included Amazon S3 (use Gradient s3-download@v1 action), Google Drive (use gdown utility), and Academic Torrents (use at-get tool). Similarly, there are many data formats and compression methods that were seen, including CSV flat files, LMDB image databases, TFRecords binary files, and .zip and tar.gz compression.
The combination of containers with installed software, ability to handle large data plus many files, and Gradient's flexible support for tools and interfaces, make it easy to build up an appropriate set of tools for what you need to do.
Our public datasets are now updated and available. We have therefore used Workflows in production to improve our enterprise business product!
Summary
We have shown Gradient Workflows being used to update our Gradient Public Datasets, showing an example of Workflows being used in production in the enterprise.
Using Workflows establishes provenance and reproducibility for where our public datasets came from, and enables the collection to be easily maintained and added to in the future.
Users can run Workflows similarly for their needs, from use of jobs for a more rigorous approach to end-to-end data science, through to a full enterprise production system.
Next steps
For more detailed information, see the documentation on Workflows and Gradient Public Datasets.
To get started with Gradient, including Notebooks, Workflows, Models, and more, see our tutorials, ML Showcase, or GitHub repository.
Thanks to Tom, Ben, Erika, and everyone else at Paperspace for making this project possible.
And thanks for reading!










