One of the common ways that humans express their emotions or feelings is through speech in the form of numerous languages that exist currently. Since birth, we slowly start to adapt and learn a language as time passes by. For humans, learning, conversing, and writing in any language that they are comfortable with might not seem like a very complex task. However, when we are dealing with machines for complicated language translations or training them to understand the semantic meaning of particular sentences, things could get quite tricky due to their inability to comprehend details like characters or subtext.
The large field of study that deals with handling these tasks related to learning languages for machines is natural language processing (NLP). The popularity of this area of research has increased immensely over the past few years, thanks to the upgraded technologies of machine translations, text classification, speech-to-text conversions, and so much more. In this article, we will explore the critical deep learning concept of transformers and their strong capabilities in handling tasks related to natural language processing. Our primary focus will be on text classification.
We will construct a transformer project that will try to learn the meaning of the input sentences, in the form of reviews, and classify them accordingly as positive or negative reviews. We will look at two methods to construct such a project. In the first method, we will construct the entire architecture from scratch, and in the second method, we will develop the same project with TensorFlow-Hub. The Gradient Platform on Paperspace is a great choice for the implementation of the following project. Check out the table of contents to explore the topics that you are interested in.
Introduction to Text Classification:
One of the intuitive things that buyers or customers often do before they purchase a product is to check out the reviews and analyze how poorly or well a particular product is being received. For humans, it is easy to read over certain reviews and gain a semantic understanding of the sentence written. Since humans are cognizant of the knowledge they have adapted to a specific language, they are able to mostly understand the hidden intent, sarcasm, or other critical aspects of speech notions to perceive the true meaning of the sentence or reviews. Humans can use their intuition to aid interpretation, but the notion of intuition is not present in machines. Machine intelligences find it hard to decipher the true intent and meaning of a particular sentence due to the inherent inherent complexity in trying to understand something that is not in binary form.
Here is where machine learning and deep learning algorithms come into the picture. Text classification can be described as a machine learning technique to classify the type of text into a particular category. These categories depend on the type of task they perform. Some examples include sentiment analysis, topic labeling, spam detection, and intent detection.
Most of the data that is available in the natural world is unstructured. Hence, it becomes crucial to find a way to reliably manage these datasets while formulating a desirable structure to analyze these problems. In this article, we will explore the concept of transformers to solve the task of text classification. Let us get started by understanding the transformer architecture.
Understanding The Transformer Architecture:
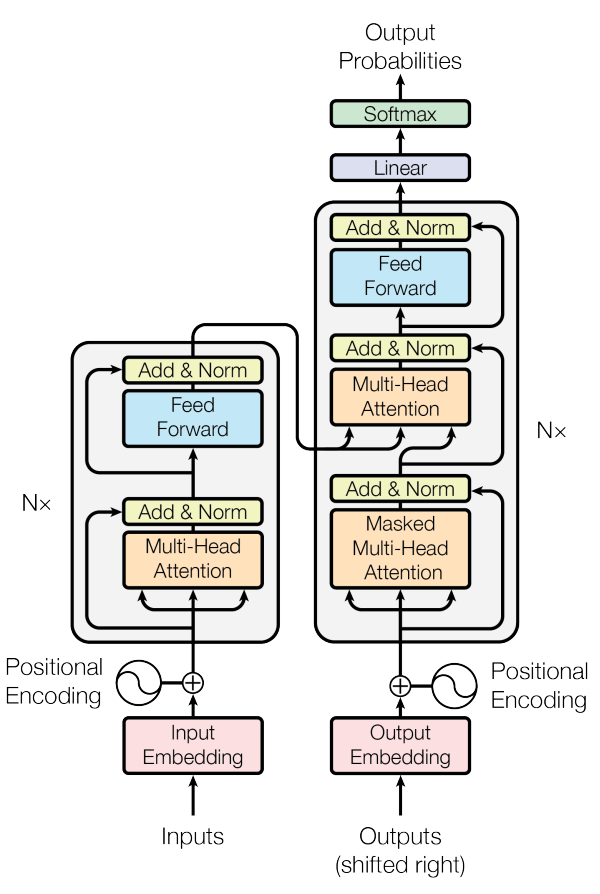
The transformers architecture published in the research paper titled "Attention Is All You Need" is one of the most influential papers in deep learning and natural language processing. The above image representation might seem quite complex to understand with a lot of elemental structures in the design. The code is, however, much simpler to parse. And by breaking down each component into individual entities, it becomes quite easy to understand all the core entities involved in the transformer design. For a more detailed explanation of the theoretical concepts of attention, I would recommend checking out one of my previous articles covering the machine translation process using sequence to sequence models from the following link.
Firstly, let us discuss about the left-hand side of the transformer architecture shown in the above figure. It consists of the encoder architecture with the positional encodings, inputs, input embeddings, and a block containing some neural network components. We will refer to this block as the transformer block, and it will be an integral aspect of understanding the working procedure of transformers.
The arrows represent the direct and skip connections that are to be made in the transformer architecture. The multi-head attention module will receive three inputs, namely values, keys and queries. The next three blocks are quite simple as we perform an addition and normalization operation, pass it through a feed-forward network, and reform the addition and normalization operation.
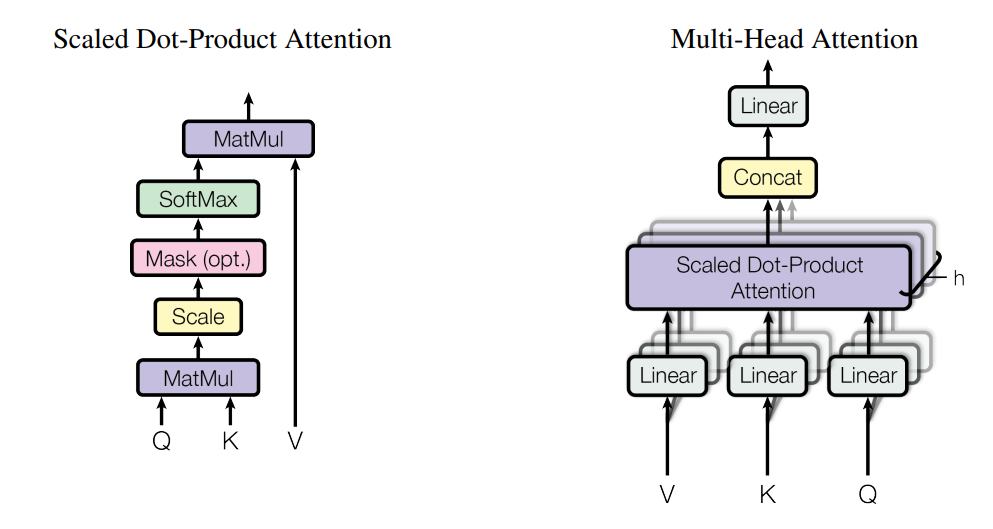
We will discuss the concept of multi-head attention in slightly more detail as the other components of the transformer network are quite straightforward to understand. The embedding input in the form of vectors, keys, and queries is passed through a linear layer. Let us say the embedding has a dimensionality of 64, and we are making use of four splits for each layer. Then, each of the layers passed through will have four blocks of 16-Dimensional data embedded in them.
This data is passed through the scaled dot-product attention, which utilizes a model similar to the one mentioned in the above figure. Also, the formula below represents the clear performance of the model, where the dot attention is equal to the product of the Softmax of the product of queries, Transpose of keys, divided by the scaling factor (which in this case is the square root of embedding size), and the vectors. Finally, the results are concatenated to retrieve the same size as the embedding, and then it is passed through a linear layer.
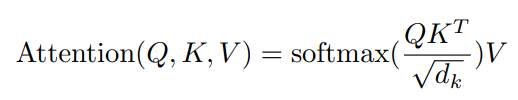
Finally, the right-hand side of the transformer network consists of the decoder architecture, which contains some similarities to the previously discussed encoder. They have a couple of transformer blocks, one with masked multi-head attention to ensure that each consecutive output only has knowledge of the previous input and not any other excessive information. The Nx in the figure represents the notion that there can be several stacks of encoder or decoder blocks to compute a particular task. For our project, we will utilize a simpler variation of the transformer block to accomplish the desired results for text classification.
Developing Transformer Model From Scratch With TensorFlow and Keras:
In this section, we will construct the transformer architecture to solve the problem of text classification and achieve a desirable result. The two primary requirements are knowledge of the deep learning frameworks TensorFlow and Keras. If you aren't familiar with these, I would recommend checking them out from the following link for TensorFlow and the following link for Keras.
We will be utilizing the IMDB dataset available in TensorFlow for performing the text classification project, where we will need to classify the positive or negative reviews accordingly. One of the primary sources of reference for the code utilized for this structure is referred to from the official Keras documentation website. The Gradient platform on Paperspace is a great way to get started with such projects. Let's start working on this project!
Bring this project to life
Importing the essential libraries:
In the first step, we will import all the essential libraries that are required for the text classification project with Transformers. As discussed previously, TensorFlow and Keras are essential requirements for this project as they will be our primary choice of deep learning frameworks. We will also import all the layers that are required for constructing the transformer architecture. Refer to the previous section to learn about all the required layers for this transformer project. I have also imported numpy and the warnings library to ignore any deprecation warnings that the user might encounter while loading the IMDB dataset.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import MultiHeadAttention, LayerNormalization, Dropout, Layer
from tensorflow.keras.layers import Embedding, Input, GlobalAveragePooling1D, Dense
from tensorflow.keras.datasets import imdb
from tensorflow.keras.models import Sequential, Model
import numpy as np
import warnings
warnings.filterwarnings("ignore", category=np.VisibleDeprecationWarning)Creating Transformer blocks and positional embedding:
We will now proceed to construct the transformer block, which follows a similar build as discussed in the previous section of the article. While I am going to utilize the multi-head attention layer that is available in the TensorFlow/Keras deep learning frameworks, you can modify the code and build your own custom multi-head layer to grant further control and access to the numerous parameters involved.
In the first function of the transformer block, we will initialize the required parameters, namely the attention layer, the batch normalization and dropout layers, and the feed-forward network. In the call function of the transformer block, we will define the layers accordingly, as discussed in the architecture overview section of the transformer block.
class TransformerBlock(Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = Sequential(
[Dense(ff_dim, activation="relu"),
Dense(embed_dim),]
)
self.layernorm1 = LayerNormalization(epsilon=1e-6)
self.layernorm2 = LayerNormalization(epsilon=1e-6)
self.dropout1 = Dropout(rate)
self.dropout2 = Dropout(rate)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)In the next code block, we will define another function that will be useful for managing the positional embeddings that are specified in the research paper. We are creating two embedding layers, namely for the tokens and the token index positions. The below code block describes how to create a class with two functions. In the first function, we initialize the token and positional embeddings, and in the second function, we will call them and encode the respective embeddings accordingly. With this step completed, we can proceed to prepare the dataset and develop the transformer model for text classification.
class TokenAndPositionEmbedding(Layer):
def __init__(self, maxlen, vocab_size, embed_dim):
super(TokenAndPositionEmbedding, self).__init__()
self.token_emb = Embedding(input_dim=vocab_size, output_dim=embed_dim)
self.pos_emb = Embedding(input_dim=maxlen, output_dim=embed_dim)
def call(self, x):
maxlen = tf.shape(x)[-1]
positions = tf.range(start=0, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
x = self.token_emb(x)
return x + positionsPreparing the data:
For this particular task, we will be referring to the IMDB dataset available with TensorFlow and Keras. The dataset contains a total of 50,000 reviews, out of which we will split the data into 25000 training sequences and 25000 testing sequences. It also contains an even split total of 50% positive reviews and 50% negative reviews segregated accordingly. In the pre-processing step, our objective is to manipulate each of these words into a set of integers, so they can be used when we proceed to construct the transformers architecture to validate the results as desired.
vocab_size = 20000 # Only consider the top 20k words
maxlen = 200 # Only consider the first 200 words of each movie review
(x_train, y_train), (x_val, y_val) = imdb.load_data(num_words=vocab_size)
print(len(x_train), "Training sequences")
print(len(x_val), "Validation sequences")In the next code snippet, we will look at the labels assigned to the first five testing sequences. These labels give us an intuition on what to expect from the data we are looking at. In a later part of this section, we will make predictions on the first five data elements to check how accurate our model is performing on these datasets.
y_val[:5]Output:
array([0, 1, 1, 0, 1], dtype=int64)
After viewing the labels for the first five elements, we will proceed to pad the sequences for both the training and validation data, as shown in the below code block. Once this procedure is completed, we will start developing our transformer model.
x_train = tf.keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_val = tf.keras.preprocessing.sequence.pad_sequences(x_val, maxlen=maxlen)Developing the model:
There are several ways in which the developers can implement the transformer model for the text classification task. It is usually common practice to use a separate encoder and decoder class to perform these actions separately. In this section, we will leverage a fairly simple method to develop our model, and utilize it accordingly for the task of text classification. We will declare our embedding dimensions for each token, the number of attention heads to use, and the size of the layers of the feed-forward network in the transformer. Then, with the help of the utility that we created by the previous transformer blocks and the positional embedding class, we will develop the model.
It is notable that we are using both the Sequential and Functional API models, allowing us to have more significant control over the model architecture. We will give an input containing the vectors of the sentence, for which we create an embedding and pass it through a transformer block. Finally, we have a global average pooling layer, a dropout, and a dense layer to return the probabilities of the possibilities of the sentence. We can use the Argmax function in numpy to obtain the correct result. Below is the code block to develop the model.
embed_dim = 32 # Embedding size for each token
num_heads = 2 # Number of attention heads
ff_dim = 32 # Hidden layer size in feed forward network inside transformer
inputs = Input(shape=(maxlen,))
embedding_layer = TokenAndPositionEmbedding(maxlen, vocab_size, embed_dim)
x = embedding_layer(inputs)
transformer_block = TransformerBlock(embed_dim, num_heads, ff_dim)
x = transformer_block(x)
x = GlobalAveragePooling1D()(x)
x = Dropout(0.1)(x)
x = Dense(20, activation="relu")(x)
x = Dropout(0.1)(x)
outputs = Dense(2, activation="softmax")(x)
model = Model(inputs=inputs, outputs=outputs)Compiling and fitting the model:
In the next steps, we will proceed to compile the transformer model that we have constructed. For the compilation procedure, we will make use of the Adam optimizer, sparse categorical cross-entropy loss function, and also assign the accuracy metrics to be computed accordingly. We will then proceed to fit the model and train it for a couple of epochs. The code snippet shows how these operations are performed.
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
history = model.fit(x_train, y_train,
batch_size=64, epochs=2,
validation_data=(x_val, y_val)
)Once the training procedure is performed, we can proceed to save the weights that we computed during the fitting process. The process to do so is as mentioned below.
model.save_weights("predict_class.h5")Evaluating the model:
While we have a snapshot idea of how well the model trained during the fitting process, it is still essential to evaluate the model and analyze the performance of this model on the testing data. Hence, we will evaluate the testing values alongside their labels to obtain the results. The model will make certain predictions on the testing data to predict the respective label, which is compared to the original labels. We will then receive a final value corresponding to the accuracy of the model.
results = model.evaluate(x_val, y_val, verbose=2)
for name, value in zip(model.metrics_names, results):
print("%s: %.3f" % (name, value))If we recollect that in one of the previous parts of this section, we had printed the values of the first five testing labels. We can proceed to make the respective predictions by using our trained model with the help of the predict function. Below is a screenshot representing the results that I was able to predict from my trained model.
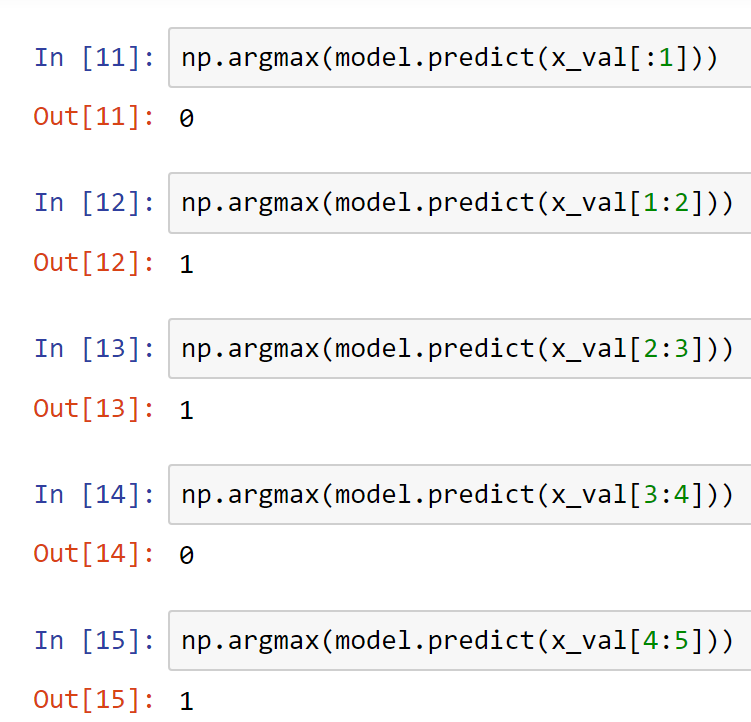
As we can notice from the above screenshot, the model is able to perform decently, predicting the respective classes that the appropriate sequence of sentences represents. The transformer model is able to perform quite well in the task of text classification as we are able to achieve the desired results on most of our predictions. However, there is still room for improvement, and the viewers can try out multiple variations of the transformer architecture to obtain the best possible results. It is recommended that you try to experiment with numerous variations to obtain the most suitable outcomes.
Bring this project to life
Transformer Model with TensorFlow Hub:
I would recommend working with the transformers from scratch build before moving on to this section of the article, where we will perform the same task with TensorFlow-Hub. With the TensorFlow-Hub, most of the complexities behind constructing our own architecture are removed as we can utilize a pre-trained model for achieving the desired results. We can use this as a preface for improving our results with the custom-trained models. Let us get started with the TensorFlow-Hub implementation of transformers for text classification.
Importing the essential libraries:
For the TensorFlow-Hub implementation of the text classification project with transformers, our primary library requirements are the TensorFlow deep learning framework alongside the hub platform containing our pre-trained models. Another method of utilizing the IMDB dataset is to make use of the TensorFlow datasets module to load the data. We will then utilize Sequential type modeling to add a few layers on top of the imported model. Check out the code snippet below for all the required imports.
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
import osPreparing the data:
In the next step, we will prepare the dataset using the previously imported libraries by loading the IMDB reviews. We can look at the dataset to understand the type of data that is utilized for the particular task. We will split the data accordingly into the train, validation, and test sets, and look at an example of the data by printing one of the sentences that it contains to view the critical reviews provided.
train_data, validation_data, test_data = tfds.load(
name="imdb_reviews",
split=('train[:60%]', 'train[60%:]', 'test'),
as_supervised=True)
train_examples_batch, train_labels_batch = next(iter(train_data.batch(10)))
train_examples_batch[:1]<tf.Tensor: shape=(1,), dtype=string, numpy=
array([b"This was an absolutely terrible movie. Don't be lured in by Christopher Walken or Michael Ironside. Both are great actors, but this must simply be their worst role in history. Even their great acting could not redeem this movie's ridiculous storyline. This movie is an early nineties US propaganda piece. The most pathetic scenes were those when the Columbian rebels were making their cases for revolutions. Maria Conchita Alonso appeared phony, and her pseudo-love affair with Walken was nothing but a pathetic emotional plug in a movie that was devoid of any real meaning. I am disappointed that there are movies like this, ruining actor's like Christopher Walken's good name. I could barely sit through it."],
dtype=object)>
Building the model:
We will load the embedding, which is a pre-trained model stored in the TensorFlow-Hub location specified in the code block below. We will then add the additional layer, and set the parameters to trainable.
We will then instantiate our sequential model and add our custom layers on top with a couple of fully connected layers. The final dense layer should have only one node as the prediction made is a text classification, where we have only two outcomes, namely positive or negative reviews, where either one of them must be selected. We can also view the model summary to understand the overall model build, which contains the pre-built model along with the couple of dense layers that we added.
embedding = "https://tfhub.dev/google/nnlm-en-dim50/2"
hub_layer = hub.KerasLayer(embedding, input_shape=[],
dtype=tf.string, trainable=True)
print(hub_layer(train_examples_batch[:3]))
model = Sequential()
model.add(hub_layer)
model.add(Dense(16, activation='relu'))
model.add(Dense(1))
model.summary()Output:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer (KerasLayer) (None, 50) 48190600
_________________________________________________________________
dense (Dense) (None, 16) 816
_________________________________________________________________
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 48,191,433
Trainable params: 48,191,433
Non-trainable params: 0
_________________________________________________________________
Compiling and training the model:
Once we have constructed our desired model, we can proceed to compile it and train it accordingly. For the compilation, we can make use of the binary cross-entropy loss for the 0 or 1 results to be obtained. We will use the Adam optimizer, and assign the metrics to accuracy. Finally, we will start training the model for a total of five epochs. The viewers can choose to change some of these parameters and monitor the training process for more epochs to achieve better results.
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_data.shuffle(10000).batch(512),
epochs=5,
validation_data=validation_data.batch(512),
verbose=1)Epoch 5/5
30/30 [==============================] - 9s 310ms/step - loss: 0.1990 - accuracy: 0.9357 - val_loss: 0.3150 - val_accuracy: 0.8627
The result that I obtained after running the Transformer model is as shown above. Let us now perform an evaluation to understand the performance of the TensorFlow-Hub pre-trained model for five epochs.
Evaluating the model:
Now that we have finished training the transformer model for text classification using the pre-trained weights available in TensorFlow-Hub for a total of five epochs, we can proceed to evaluate its performance on the test data to see how well our model performed. We can do so with the code snippet provided below.
results = model.evaluate(test_data.batch(512), verbose=2)
for name, value in zip(model.metrics_names, results):
print("%s: %.3f" % (name, value))49/49 - 7s - loss: 0.3277 - accuracy: 0.8464
loss: 0.328
accuracy: 0.846
For obtaining better results, we can choose to run the model for a higher number of epochs, among trying numerous other modifications, to see if we can create a training run that will give the best results. The transformer architecture built from scratch will allow the users with more flexibility and control to develop the desired model with various parameter changes to obtain the best results. Experimenting and testing is the best way to find out which changes make the most sense for the improvement of the constructed model.
Conclusion:

Natural language processing is one of those crucial, bleeding edge fields of development, alongside computer vision and image processing, where there is tons of research taking place. Deep learning and neural network models have shown an increased rate of success in tackling problems related to natural language processing in numerous tasks like machine translations, text classification, speech-to-text conversions, and so much more. With the continuous advancement in the field of deep learning, it has become fairly more reasonable to tackle such a project yielding effectively good progress with fairly decent results.
In this article, we explored one of the many applications of natural language processing in text classification. We understood the meaning of text classification and the significance of such operations. We then proceeded to gain an intuitive understanding of the transformer neural networks and the immense productivity that it has bestowed in the area of NLP due to its versatility in accomplishing a large set of projects. Finally, in the next sections, we constructed transformer architectures to perform the task of text classification. In the first project, we discussed the construction of transformers from scratch, while in the second project, we learned how to build these transformers to solve the same task utilizing TensorFlow-Hub.
In future articles, we will explore multiple other projects related to natural language processing and the capabilities of deep neural networks to solve them, including an extension of the Transformers architecture in BERT. We will also look into other fun projects on neural networks from scratch and conditional GANs. Until then, have fun working on your own projects!











