
Introduction
YOLO (You Only Look Once) is a popular object detection algorithm that has revolutionized the field of computer vision. It's fast and efficient, making it an excellent choice for real-time object detection tasks. YOLO NAS (Neural Architecture Search) is a recent implementation of the YOLO algorithm that uses NAS to search for the optimal architecture for object detection.
In this article, we will provide a comprehensive overview of the architecture of YOLO NAS, highlighting its unique features, advantages, and potential use cases. We will cover details on its neural network design, optimization techniques, and any specific improvements it offers over traditional YOLO models. Also, we'll explain how YOLO NAS can be integrated into existing computer vision pipelines.
AutoNAC: Revolutionizing Neural Architecture Search in YOLO-NAS
Deep learning has witnessed a revolutionary approach known as Neural Architecture Search (NAS) that automates the process of designing optimal neural network architectures. AutoNAC (Automated Neural Architecture Construction), one of the various NAS methodologies, is remarkable for its pioneering contributions in developing YOLO-NAS.
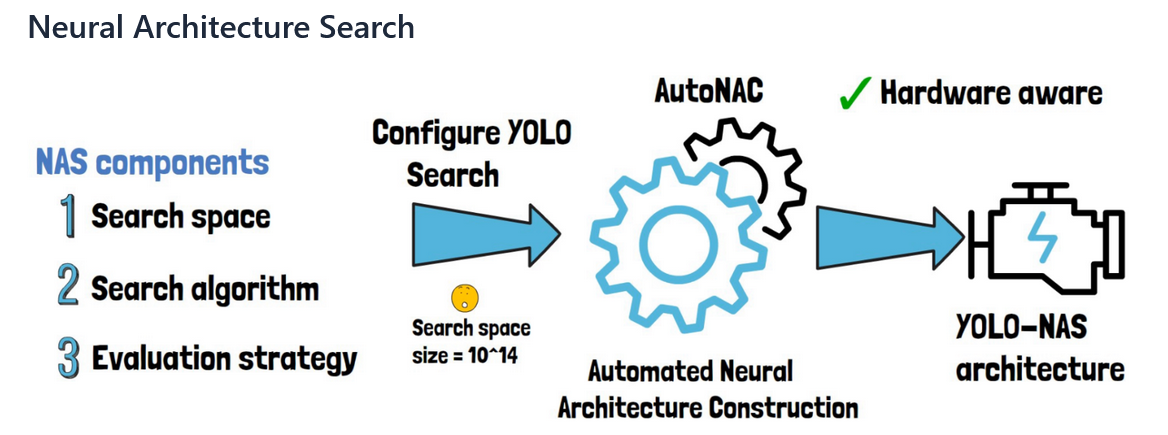
Key Components of NAS
- Search Space: Defines the set of all possible architectures that can be generated.
- Search Strategy: The algorithm used to explore the search space, such as reinforcement learning, evolutionary algorithms, or gradient-based methods.
- Performance Estimation: Techniques to evaluate the performance of candidate architectures efficiently.
The operational mechanism of AutoNAC
AutoNAC refers to Deci AI's exclusive implementation of NAS technology, which was meticulously developed to enhance YOLO-NAS architecture. This advanced mechanism automates searches in pursuit of optimal neural network configuration.
AutoNAC functions via a multi-faceted process, thoughtfully formulated to maneuver the intricacies of neural architecture design:
- Defining the Search Space: The initial step of AutoNAC involves establishing a comprehensive search space, which spans diverse potential architectures. This inclusive domain comprises several configurations of convolutional layers, activation functions, and other architectural constituents.
- Search strategy: AutoNAC utilizes sophisticated search methodologies to explore designated search areas. These methodologies may incorporate reinforcement learning techniques, in which an agent learns to select optimal architectural components that optimize efficiency and productivity. They can also incorporate evolutionary algorithms, through which architectures are iteratively evolved based on their performance metrics.
- Performance Estimation: AutoNAC employs a blend of proxy tasks and early stopping methods to expedite the evaluation of potential architectures. This approach enables swift assessment without requiring full training, thereby considerably expediting the pursuit of optimal solutions.
- Optimization: AutoNAC optimizes chosen architectures by applying various criteria such as accuracy, latency and resource utilization. The implementation incorporates multi-objective optimization to guarantee that the resultant architecture is fit for deployment in practical settings.
Quantization Aware Architecture in YOLO- NAS
The Quantization Aware Architecture (QAA) marks a leap in the realm of deep learning, specifically when boosting the efficiency of neural networks. By using quantization, high-precision floating-point numbers are mapped to lower-precision numbers.
Using sophisticated techniques in YOLO-NAS quantization is paramount to enhancing the model's efficacy and operational excellence. The crux components of this cutting-edge process are as follows:
- Quantization-Aware Modules: YOLO-NAS employs specialized, cutting-edge quantization-aware modules known as QSP (Quantization-Aware Spatial Pyramid) and QCI (Quantization-Aware Convolutional Integrations). These ingenious components use powerful re-parameterizing techniques to enable 8-bit quantization. They minimize accuracy loss during post-training quantification. By incorporating these pioneering innovations, YOLO-NAS guarantees that the model preserves optimal performance and accuracy.
- Hybrid Quantization Method: YOLO-NAS opts for a more nuanced and selective approach than using an across-the-board quantization strategy. This technique involves targeting specific areas of the model for quantization purposes.
- Minimal drop precision: When converted to its INT8 quantized version, YOLO-NAS experiences only a minimal drop in precision. This unprecedented feat distinguishes it from its counterparts and highlights the effectiveness of its quantization strategy.
- Quantization-friendly architecture: The fundamental constituents of YOLO-NAS are crafted to be exceptionally adept at quantization. This architectural approach guarantees that the model remains impressively high-performing, even after undergoing quantization.
- Advanced training and quantization techniques: YOLO-NAS harnesses training methodologies and post-training quantization techniques to enhance its overall efficiency.
- Adaptative quantization: The YOLO-NAS model has been crafted to incorporate the adaptive quantization technique. This involves intelligently skipping specific layers to balance latency, throughput, and accuracy loss.
The drop in mean Average Precision for YOLO-NAS is only 0.51, 0. 65, and 0. 45 for the S, M, and L versions of YOLO-NAS. Other models usually lose 1-2 points when quantized.
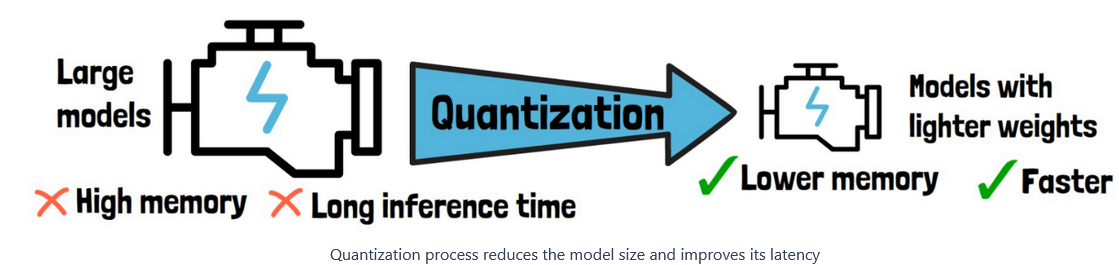
These techniques provide YOLO-NAS with incredible architecture that keeps robust object detection and performance. The quantization in YOLO-NAS allows fast inference with lower latency without losing too much accuracy. This makes it a great starting point for customizing models that need real-time inference.
Overcoming Quantization Challenges in YOLO-NAS with QARepVGG
QARepVGG is an improved version of the popular RepVGG block in object detection models. It significantly improves on the accuracy drop after quantization. The original RepVGG block replaces each convolutional layer with diverse operations.
However, the accuracy of RepVGG decreases when directly quantized to INT8. QARepVGG enhances RepVGG to fix its quantization issues from the multi-branch design. It reduces the number of parameters and improves the detection accuracy and speed of the model. Deci's researchers trained their neural architecture search algorithm to add QARepVGG into YOLO-NAS. This boosted its quantization-friendly abilities and efficiency.
YOLO NAS Architecture
The model uses techniques like attention mechanisms, quantization aware blocks, and reparametrization at inference time. These techniques help YOLO-NAS to identify objects of varying sizes and complexities better than other detection models. The YOLO-NAS architecture consists of three main components:
- Backbone
- Neck
- Head
The constituents of this system have been crafted and optimized using the NAS method. It results in a unified and robust object detection system.
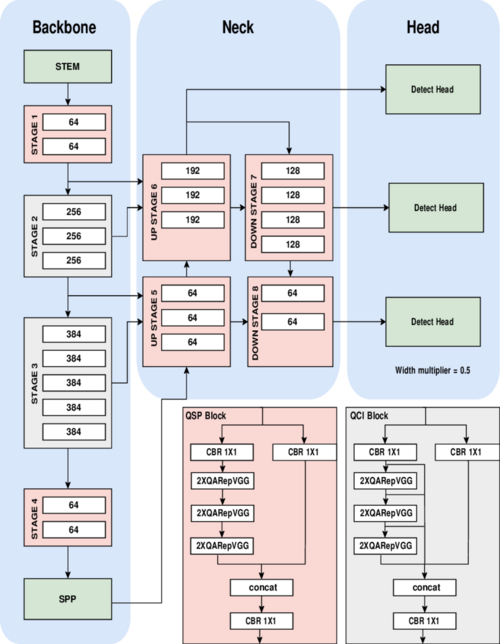
Backbone
This foundational element of YOLO-NAS is responsible for extracting features from input images. This component utilizes a series of convolutional layers and customized blocks that are optimized to capture low-level and high-level features effectively.
Neck
The YOLO-NAS neck component functions as a bridge between the backbone and the detection head. It facilitates feature aggregation and enhancement. It integrates information from various scales to enhance model efficiency in detecting objects that vary in size.
The YOLO-NAS system employs a sophisticated feature pyramid network (FPN) architecture in its neck, incorporating cross-stage partial connections and adaptive feature fusion. This innovative design facilitates optimized information flow across various neural network levels. It augments the model's capacity to address scale variations during object detection tasks.
Head
The detection head is where the final object predictions are made. YOLO-NAS uses a multi-scale detection head, similar to other recent YOLO variants. However, it incorporates several optimizations to improve both accuracy and efficiency:
- Adaptive anchor-free detection: The innovative YOLO-NAS technique for detection takes a revolutionary adaptive anchor-free approach rather than relying on rigid, preconceived notions of anchors box. As a result of this dynamic and intuitive strategy, this method offers improved flexibility in accurately predicting bounding boxes with remarkable precision.
- Multi-level feature fusion: The process of multi-level feature fusion involves the head cleverly integrating various features from diverse levels within the neck. This leads to a superior ability to detect objects present at varying scales.
- Efficient channel attention: The researchers have implemented a lightweight channel attention mechanism with incredible efficiency. It sharply hones in on the most relevant features for optimal detection.
Advantages of YOLO NAS
YOLO NAS has several advantages over traditional YOLO models, making it an excellent choice for object detection tasks:
- Efficiency: YOLO NAS rocks for object detection. Compared to traditional YOLO models, it's more efficient. That means we can perform real-time object detection even on wimpy mobile phones and drones.
- Accuracy: YOLO NAS doesn't skimp on accuracy. It excels on all the usual benchmarks. We can trust it for object detection tasks.
- Optimal architecture: It uses NAS to find the ideal architecture, resulting in a more efficient and accurate model.
- Robustness: YOLO NAS is robust to occlusion and clutter, making it suitable for object detection in complex environments.
Potential Use Cases of YOLO NAS
Suppose a company wants to develop an AI system to detect real-time objects in a video stream. They can use YOLO-NAS as a foundational model to build their AI system.
They can fine-tune the pre-trained weights of YOLO-NAS on their specific dataset using transfer learning, a technique that allows the model to learn from a small amount of labeled data. They can also use the quantization-friendly basic block introduced in YOLO-NAS to optimize the model's performance and reduce its memory and computation requirements.
YOLO NAS can be used in various real-world applications, such as:
- Surveillance: Some security cameras can detect events in real time using YOLO NAS. Artificial intelligence can spot intruders or weird behavior immediately without a human having to monitor the footage.
- Autonomous vehicles: Autonomous vehicles are improving. YOLO NAS can help self-driving cars detect objects around them. This includes pedestrians about to cross the street or other cars changing lanes. Driverless tech needs to recognize obstacles and react quickly to avoid accidents.
- Medical imaging: It can be used for object detection in medical imaging. It can identify tumors and abnormalities in X-rays or MRI scans.
- Retail: YOLO NAS can be used for object detection in retail, such as detecting products on shelves or tracking customer behavior.
Integration of YOLO NAS into Existing Computer Vision Pipelines
The YOLO-NAS model is available under an open-source license with pre-trained weights for non-commercial use on SuperGradients. YOLO-NAS is quantization-friendly and supports TensorRT deployment, ensuring full compatibility with production use. This breakthrough in object detection can inspire new research and revolutionize the field, enabling machines to perceive and interact with the world more intelligently and autonomously.
It can be plugged into existing computer vision pipelines built with PyTorch or TensorFlow. It can be trained to detect custom objects using the same training process as any other YOLO model.
Introduction to YOLONAS with SuperGradients
Bring this project to life
SuperGradients is a new PyTorch library for training models on everyday computer vision tasks like classification, detection, segmentation, and pose estimation. They've about 40 pre-trained models already in their model zoo. We can go ahead and check out the available ones here.
The code below uses pip to install four Python packages: super-gradients, imutils, roboflow, and pytube.
pip install super-gradients==3.2.0
pip install imutils
pip install roboflow
The first line installs the super-gradients package with version 3.2.0. After that, we bring in the imutils package. This provides a bunch of handy functions for performing regular image processing stuff. Then we pull in the roboflow package. This package provides Python API for the Roboflow platform, which helps to handle and label datasets for computer vision tasks.
Now, we will use one of their pre-trained models - YOLONAS comes in small(yolo_nas_s), medium(yolo_nas_m), and large(`yolo_nas_l`) versions. We'll rock with the large one for now.
Next, we import the models module from the super_gradients.training package to get the YOLO-NAS-l model with pre-trained weights.
from super_gradients.training import models
yolo_nas_l = models.get("yolo_nas_l", pretrained_weights="coco")The first line in the code above imports the models module from the super_gradients.training package.
The second line uses the get function from the models module to get the YOLO-NAS-l model with pre-trained weights.
The get function takes two parameters: the model name and the pre-trained weights to use. In this case, the model name is "yolo_nas_l," which specifies the large variant of the YOLO-NAS model, and the pre-trained weights are "coco," which specifies the pre-trained weights on the COCO dataset.
We can run the cell below if we're curious about the architecture. The code below uses the summary function from the torchinfo package to display a summary of the YOLO-NAS-l model.
pip install torchinfo
from torchinfo import summary
summary(model=yolo_nas_l,
input_size=(16, 3, 640, 640),
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"]In the above code, we import the summary function from the torchinfo package. The second line uses the summary function to display a summary of the YOLO-NAS-l model. The model parameter specifies the YOLO-NAS-l model to summarize.
The input_size parameter specifies the input size of the model. The col_names parameter specifies the column names to display in the output. The col_width parameter specifies the width of each column. The row_settings parameter specifies the row settings to use in the production.
So, we've got our model all setup and ready to go. Now comes the fun part - using it to make predictions. The predict method is super easy to use, and it can take in different inputs: A PIL image, a Numpy image, a file path to an image, a file path to a video, a folder path with some pictures of it, and even just an URL to an image.
There's also a conf argument to specify if we want to adjust the confidence threshold for detections. For example, we could do model. predict(path/to/image, conf=0. 35) only to get detections with 35% or higher confidence. Tweak this as needed to filter out less accurate predictions. Let's make an inference from the image below.

The below code uses the YOLO-NAS-l model to make predictions on the image specified by the url variable.
url = "https://previews.123rf.com/images/freeograph/freeograph2011/freeograph201100150/158301822-group-of-friends-gathering-around-table-at-home.jpg"
yolo_nas_l.predict(url, conf=0.25).show()This code shows how to use YOLO-NAS-l to make a prediction on an image and show the results. The predict function takes an image URL and a confidence level as input. It returns the predicted objects in the image. The show method displays the image with boxes around the predicted objects.
Note: The reader can launch the code and see the result.
Conclusion
YOLO NAS is a recent implementation of the YOLO algorithm that uses NAS to search for the optimal architecture for object detection. It's faster and more accurate than the original YOLO networks, so it's great for spotting objects in real-time.
YOLO NAS has achieved state-of-the art performance on a bunch of benchmarks, and we can integrate it into computer vision systems using popular deep learning frameworks. To improve the performance of YOLO NAS, researchers are checking out stuff like multi-scale training, attention mechanisms, hardware acceleration, and automated NAS methods.
References
 Shaoni Mukherjee
Shaoni Mukherjee
 Deci
Deci


 Deci-AI
Deci-AI











{kind=link}