
Bring this project to life
As per Wikipedia — a glossary, also known as a vocabulary, is an alphabetical list of terms in a particular domain of knowledge with the definitions for those terms. Traditionally, a glossary appears at the end of a book and includes terms within that book that are either newly introduced, uncommon, or specialized. Whereas, definitions are statements that explain the meaning of a term. A good list of glossary terms can make text comprehensible given enough 'commonsense' and 'background knowledge'.
In this blog post, we will focus on building an unsupervised NLP pipeline for automatically extracting/generating glossaries and associated definitions from a given text document like a book/chapter/essay. Manual generation of glossary lists and their definitions is a time-consuming and cumbersome task. With our pipeline, we aim to significantly reduce this effort and augment the writers with suggestions while still making their verdict to be the final one during selection.
Dataset Collection
We will be building a mostly unsupervised system, so for evaluating our pipeline's output, we will get started by extract 50 fiction/non-fiction novels from Gutenberg Project. Project Gutenberg is a library of over 60,000 free eBooks - completely without cost to readers. Having downloaded the books, the next task was to get their glossary and associated definitions. We can use GradeSaver for fetching this information. GradeSaver is one of the top editing and literature sites in the world. With this, we have some ground-truth data available to us for evaluating the goodness of our proposed pipeline.
Next, let's see the code for extracting novels, associated glossary, and definitions -
Code for Extracting Novels from Project Gutenberg
from bs4 import BeautifulSoup
import requests
import pandas as pd
import glob
import string
import os
import codecs
BASE_BOOK_URL = 'https://www.gutenberg.org/browse/scores/top'
html = requests.get(BASE_BOOK_URL).text
soup = BeautifulSoup(html)
unq_code = {}
for s in soup.findAll('li'):
url = s.a['href']
if 'ebooks' in url:
url_str = url.split('/')[-1]
if url_str!='':
unq_code[url.split('/')[-1]] = s.a.text
BOOK_TXT_BASE = 'https://www.gutenberg.org/files/'
book_urls = []
for code in unq_code:
book_urls.append(os.path.join(BOOK_TXT_BASE,f'{code}/{code}-0.txt'))
for b in book_urls:
name = b.split('/')[-2]
html = requests.get(b).text
with codecs.open(f'book/{name}.txt', 'w', 'utf-8') as infile:
infile.write(html)As can be seen in the above snippet, we use BeautifulSoup python library for extracting the unique code for every novel from top listings url. These listings are based on the number of times each eBook gets downloaded. Next, we simulate the click feature and extract novel's raw text if the 'Plain Text UTF-8' version of the book is present from the BOOK_TXT_BASE url. And finally, we download each novel and save it in our desired location with the proper naming convention.
Code for Extracting Glossary and Definitions from GradeSaver
BASE_GLOSS_URL = 'https://www.gradesaver.com/'
TERMINAL = '/study-guide/glossary-of-terms'
def punctuations(data_str):
data_str = data_str.replace("'s", "")
for x in data_str.lower():
if x in string.punctuation:
data_str = data_str.replace(x, "")
return data_str
for book in glob.glob('book/*'):
code = book.split('/')[-1].split('.')[0]
try:
bookname = unq_code[code]
bookname = bookname.split(' by ')[0].lower()
bookname = punctuations(bookname)
bookname = bookname.replace(" ", "-")
html = requests.get(BASE_GLOSS_URL+bookname+TERMINAL).text
soup = BeautifulSoup(html)
tt = []
for term in soup.findAll("section", {"class": "linkTarget"}):
tt.append(
[term.h2.text.lower().strip(),
term.p.text.lower().strip()]
)
if len(tt):
print (f'Done: {bookname}')
data = pd.DataFrame(tt, columns=['word', 'def'])
data.to_csv(f'data/{code}.csv', \
sep='\t', \
encoding='utf-8', \
index=False)
else:
print (f'Skipped: {bookname}')
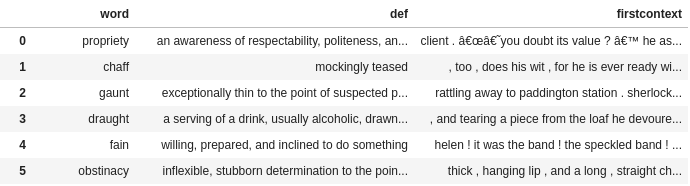
except Exception as e: print (e)As can be seen in the above snippet, we again use BeautifulSoup python library for extracting the glossary and associated definitions for each book from the GradeSaver database. The below image shows a glimpse of the file that gets generated as a part of the above code snippet -

Approach for Glossary Extraction
We approach the task of Glossary extraction by proposing a chunking pipeline, which at every step removes not-so-important candidate glossary words from the overall list. Lastly, we have a ranking function based on semantic similarity that calculates the relevance of each glossary word with the context and prioritizes the words in the glossary list accordingly.
We evaluate the output from our pipeline on Precision, Recall, and F1 scores against the ground truth obtained from GradeSaver for a particular novel. Precision measures how many of the glossary words produced are actually correct as per the available ground truth. Recall measures how many of the ground truth glossary words were produced/missed by the method proposed. F1 score is just a single numerical representation of Precision and Recall (represented as the harmonic mean of Precision (P) and Recall (R)).
Also, for simplicity purposes, we aim to only extract unigram, or single word, level glossary words. The below figure shows the entire process flow -
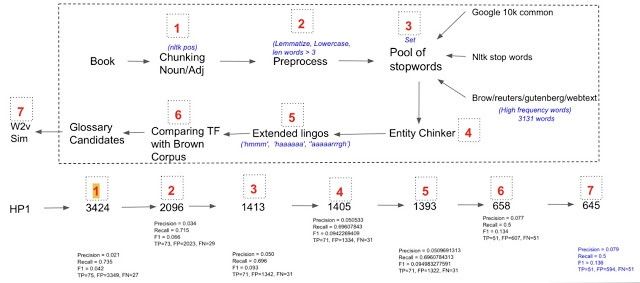
As can be seen in the above figure, we start off with a sample book from which we extract Nouns and Adjectives using the NLTK library. In step 2, we do some pre-processing like lemmatization, lowercasing, and min word length limit (words with very small length are likely to be stray marks, determiners, acronyms, etc) and might not necessarily have elaborate meaning for becoming the glossary words. In step 3, we filter all the common words, and we generate the set of such words by taking into account three different generic sources, namely, Google books common words, NLTK stop words, and High-frequency words from the chosen corpus like Brown, Reuters, etc. So any candidate glossary word that lies in the union list of words from these corpora is discarded immediately. In 4th step, we remove words that are any kind of entities in some sense(using spacy). In step 5, we remove extended lingos using regular expression. In step 6, we try to choose the words that are more specific to our corpus rather than some other global corpus based on Term-Frequency (TF).
At last, we go ahead and do one more step of ranking candidates on the basis of their relevance score. We define relevance measure as the cosine similarity between candidate glossary and corpus. The higher the score, the more the glossary keyword is relevant to the underlying corpus. In the above diagram, I have also mentioned a step-by-step impact on the P, R, and F1 scores. With the above-mentioned technique, we were able to get to Precision of 0.07, Recall of 0.5, and F1 of 0.13.
In the below image we present some of the results for Glossary worthy words extracted by our proposed system from Harry Potter Book - Part 1.

Some experiments which didn't workout
- Experimented with Graph-based word/phrase ranking method - TextRank for extracting candidate glossary words directly instead of the above-mentioned Noun-Adjective Chunking strategy.
- We believed that the complexity of a word is a good indicator of what a glossary word should be. For this, we considered the complexity in both written and spoken sense.
- We use the Flesch-Kincaid Grade Level metric for testing the written complexity.
- We count the number of Phonemes present as a measure of spoken complexity.
- We also tried forming word clusters based on dense vector representation and other custom features like complexity, word length, relevance, etc. And expected to see a separate glossary-worthy cluster.
Approach for Definition Extraction/Generation
The definitions consist of two parts, Definiendum and Definiens. The definiendum is the element that is to be defined. The definiens provides the meaning to definiendum. In a properly written simple text piece, definiendum and definiens are often found to be connected by a verb or punctuation mark. We approach the task of definition extraction/generation for a given glossary word under a given context as a 3-step pipeline(Rule-based Mining -> WordNet-based Selection -> GPT-2 based generation) with an exit option at each step. Let's discuss each of them in detail -
Rule-based Mining
In rule-based mining, we define certain grammatical constructs for extracting definition structures from the text for a given keyword. Some of the patterns we form are, for example — X is defined as Y, X is a Y, etc. Here, X is the glossary word or definiendum, and Y is expected to be the meaning or definiens. We use regular expression patterns for implementing this step.
WordNet-based Selection
The next step in the pipeline is to use a WordNet-based selection strategy for extracting relevant definitions for a given glossary word. The below figure illustrates the entire process in detail -
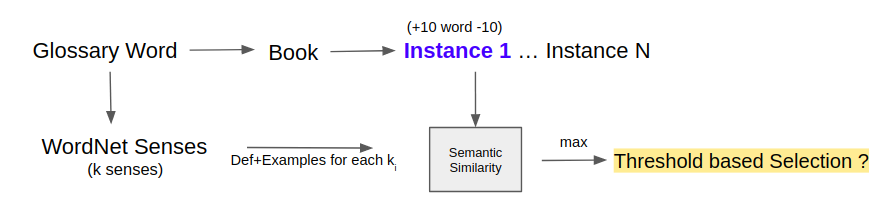
We start with finding the set of k senses (a sense is a.k.a meaning) for every glossary word found in the previous step using the WordNet library. We also extract the first context from the text where this glossary word occurs as a potential definition. The context is defined by setting a window of K words around the glossary word. The hypothesis here for selecting only the first context (marked in violet color) is that the author of the book/text is likely to define or explain the word as early as possible in the literature and then re-use it later as and when required. We understand that this hypothesis holds mostly in longer text pieces like books, novels, etc - which is reflective of our dataset.
For each of the unique senses from the set of k senses for a given glossary word, we extract the definition, related example and do a cosine similarity with the first context text. This helps in disambiguation and helps choose the most appropriate sense/meaning/definiens for a given word. As a part of the design implementation, one can either choose to select the top sense as per the similarity score or might want to not select anything at all and fall back to the 3rd step in the definition extraction/generation pipeline.
In the below image we present Definitions (column new_def) based on a WordNet selection scheme.

Code for Extracting Definitions from WordNet
Bring this project to life
We start by fetching the first occurring context of the glossary word from the text.
import codecs
import os
import pandas as pd
import glob
import nltk
nltk.download('punkt')
from nltk.corpus import PlaintextCorpusReader
def get_context(c):
try:
result = text.concordance_list(c)[0]
left_of_query = ' '.join(result.left)
query = result.query
right_of_query = ' '.join(result.right)
return left_of_query + ' ' + query + ' ' + right_of_query
except:
return ''
generated_dfs = []
BASE_DIR = 'data'
for book in glob.glob('book/*'):
book_name = book.split('/')[-1].split('.')[0]
try:
DATA_DIR = codecs.open('book/' + book_name + '.txt', \
'rb', \
encoding='utf-8').readlines()
true_data = pd.read_csv(
'data/'+book_name+'.csv', \
sep='\t')
full_data = ' '.join([i.lower().strip() for i in DATA_DIR if len(i.strip())>1])
tokens = nltk.word_tokenize(full_data)
text = nltk.Text(tokens)
true_data['firstcontext'] = true_data['word'].map(lambda k: get_context(k))
generated_dfs.append(true_data)
except Exception as e:
pass
final_df = pd.concat(generated_dfs[:], axis=0)
final_df = final_df[final_df['firstcontext']!='']
final_df = final_df[['word', 'def', 'firstcontext']].reset_index()
final_df.head(5)The below image shows the output data frame from the above snippet -
Next, we load word vectors using gensim KeyedVectors. We also define sentence representation as the average of vectors of the words present in the sentence.
import gensim
from gensim.models import Word2Vec
from gensim.utils import simple_preprocess
from gensim.models.keyedvectors import KeyedVectors
import numpy as np
from gensim.models import KeyedVectors
filepath = "GoogleNews-vectors-negative300.bin"
wv_from_bin = KeyedVectors.load_word2vec_format(filepath, binary=True)
ei = {}
for word, vector in zip(wv_from_bin.index_to_key, wv_from_bin.vectors):
coefs = np.asarray(vector, dtype='float32')
ei[word] = coefs
def avg_feature_vector(sentence, model, num_features):
words = sentence.split()
#feature vector is initialized as an empty array
feature_vec = np.zeros((num_features, ), dtype='float32')
n_words = 0
for word in words:
if word in embeddings_index.keys():
n_words += 1
feature_vec = np.add(feature_vec, model[word])
if (n_words > 0):
feature_vec = np.divide(feature_vec, n_words)
return feature_vecNext, we concatenate the definition of each sense and examples present in the WordNet library and calculate the semantic relatedness between this and the first context of the glossary word from the text. Lastly, we pick the one that has maximum similarity as the candidate definition.
def similarity(s1, s2):
s1_afv = avg_feature_vector(s1, model=ei, num_features=300)
s2_afv = avg_feature_vector(s2, model=ei, num_features=300)
cos = distance.cosine(s1_afv, s2_afv)
return cos
for idx in range(final_df.shape[0]):
fs = final_df.iloc[idx]['firstcontext']
w = final_df.iloc[idx]['word']
defi = final_df.iloc[idx]['def']
syns = wordnet.synsets(w)
s_dic={}
for sense in syns:
def,ex = sense.definition(), sense.examples()
sense_def = def + ' '.join(ex)
score = similarity(sense_def, fs)
s_dic[def]=score
s_sort = sorted(s_dic.items(), key=lambda k:k[1],reverse=True)[0]
final_df['new_def'][idx]=s_sort[0]
final_df['match'][idx]=s_sort[1]GPT-2 based Generation
This is the final step in our definition extraction/generation pipeline. Here, we fine-tune a medium-sized, pre-trained GPT-2 model on an openly available definitions dataset from the Urban Dictionary. We pick phrases and their related definitions from the 2.5 million data samples present in the dataset. For fine-tuning we format our data records with special tokens that help our GPT-2 model to act as a conditional language generation model based on specific prefix text.
How to load Kaggle data into a Gradient Notebook
- Get a Kaggle account
- Create an API token by going to your Account settings, and save kaggle.json. Note: you may need to create a new api token if you have already created one.
- Upload kaggle.json to this Gradient Notebook
- Either run the cell below or run the following commands in a terminal (this may take a while)
> Note: Do not share a notebook with your api key enabled
Now in the terminal:
mkdir ~/.kaggle/
mv kaggle.json ~/.kaggle/
pip install kaggle
kaggle datasets download therohk/urban-dictionary-words-dataset
kaggle datasets download adarshsng/googlenewsvectors
- Training Loop - I/O Format - <|startoftext|> word <DEFINE> meaning <|endoftext|>
- Testing Loop - Input Format - <|startoftext|> word <DEFINE> / Output Format - meaning <|endoftext|>
Here, <|startoftext|> and <|endoftext|> are special tokens for the start and stop of the text sequence, and <DEFINE> is the prompt token, telling the model to start generating definition for the existing word.
We start by first loading the urban dictionary dataset of words and definitions, as shown below -
import pandas as pd
train = pd.read_csv(
'urbandict-word-defs.csv', \
nrows=100000, \
error_bad_lines=False
)
new_train = train[['word', 'definition']]
new_train['word'] = new_train.word.str.lower()
new_train['definition'] = new_train.definition.str.lower()Next, we select the appropriate device and load the relevant GPT-2 tokenizer and model -
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import numpy as np
import os
from tqdm import tqdm
import logging
logging.getLogger().setLevel(logging.CRITICAL)
import warnings
warnings.filterwarnings('ignore')
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium')
model = GPT2LMHeadModel.from_pretrained('gpt2-medium')Next, we define the dataset class for appropriately formatting each input example. Since we are using an autoregressive model for generating text conditioned on prefix text, we define a trigger token <DEFINE> separating word and associated definition. We also add the start and end text tokens with each input example to make the model aware of starting and ending hints. We will also create a data loader from the dataset with a batch size of 4 and set shuffling to be true, making our model robust to any hidden patterns that might exist in the original dataset.
from torch.utils.data import Dataset, DataLoader
import os
import json
import csv
class GlossaryDataset(Dataset):
def __init__(self, dataframe):
super().__init__()
self.data_list = []
self.end_of_text_token = "<|endoftext|>"
self.start_of_text_token = "<|startoftext|>"
for i in range(dataframe.shape[0]):
data_str = f"{self.start_of_text_token} \
{new_train.iloc[i]['word']} \
<DEFINE> \
{new_train.iloc[i]['definition']} \
{self.end_of_text_token}"
self.data_list.append(data_str)
def __len__(self):
return len(self.data_list)
def __getitem__(self, item):
return self.data_list[item]
dataset = GlossaryDataset(dataframe=new_train)
data_loader = DataLoader(dataset, batch_size=4, shuffle=True)Next, we define our optimizer, scheduler, and other parameters.
from transformers import AdamW
EPOCHS = 10
LEARNING_RATE = 2e-5
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
model = model.to(device)
model.train()
optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)Finally, we write our training loop for performing forward and backward passes, and execute training.
for epoch in range(EPOCHS):
print (f'Running {epoch} epoch')
for idx,sample in enumerate(data_loader):
sample_tsr = torch.tensor(tokenizer.encode(sample[0]))
sample_tsr = sample_tsr.unsqueeze(0).to(device)
outputs = model(sample_tsr, labels=sample_tsr)
loss = outputs[0]
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
model.zero_grad()In the below image, we present some of the results from our GPT-2 based definition generation on inference.

Concluding thoughts
In this blog, we discuss a seed approach for extracting glossaries and related definitions using natural language processing techniques mostly in an unsupervised fashion. And we strongly believe that this can lay the foundations for building more sophisticated and robust pipelines. Also, we think that the evaluation of such tasks on some objective scale such as Precision, Recall is not entirely justified and should be evaluated by humans at the end of the day. Because the author of the book also considers the audience, demography, culture, etc he is targeting while coming up with the glossary list.
I hope you enjoyed reading this article. Thank you!











