
Salvador Dalí. An eccentric master of surrealism. Described by a handful of people as a mischievous provocateur. Many saw him as an arrogant disruptor. A few thought he was mad. Nonetheless, everyone agrees that he was a possessor of undeniable technical virtuosity. Simply put, not many could bring imagination to life like Dalí did. As a creative artist, Dalí was inspirational.
Making an allusion to this are the creators of the Spanish heist crime drama, La casa de papel and the more scientific creators at OpenAI – an AI research lab backed by Elon Musk. Although from two fields that are quite far apart, both sets of creators drew inspiration from Dalí. While the Dalí-inspired mask from the popular Netflix show alludes to the flamboyant personality Dalí had, DALL-E, the Artificial Intelligence product of OpenAI adverts to the ‘bringing imagination to life’ behavior of his works.
When DALL-E first launched in January 2021, OpenAI reported it as a 12-billion parameter version of GPT-3 trained to generate images from text descriptions, using a dataset of text-image pairs. At that point, questions about the origin of its name, DALL-E were not uncommon. However, on experiencing the prowess of the system, the consensus became that the application combined the wonderful craziness of Salvador Dalí with the make-life-easy attribute of the doe-eyed Disney robot, WALL-E from Pixar film of the same name. As such, not only is it worthy of the name, DALL-E but it was doing something incredibly different.
What is DALL-E?
Most Artificial Intelligence products at the time (and to this day) sought to turn one sense into another. Their works usually revolves around the credence of vision (i.e. image analysis, handwriting recognition etc.), language (i.e. translators, content moderators etc.), speech (i.e. speaker verification, text-to-speech transcriptions, real-time translation etc.), knowledge and search. For instance, Meta’s (then Facebook) wav2letter++ and Mozilla’s DeepSpeech would turn speech to text – working with two senses. But then, here came DALL-E and it was able to connect to the sense of imagination and recreate it like no other product had ever done. Unlike Google searches, DALL-E was not retrieving images that already existed.
At its simplest, DALL-E is made up of two components - an auto-encoder and a transformer. Whilst the former learns to accurately represent images in a compressed latent space, the latter learns the correlations that exist between languages and this discrete image representation. In my opinion, the transformer is the meat of DALL-E. This is because it is what allows the model to generate new images that correctly fit with a given text prompt. Moreover, it is responsible for how language and images fit together, so that when the model is prompted to generate images of ‘a green school bus parked in a parking lot’ as shown below with DALL-E inspired model DALL-E Mini, it is able to spit out some creative designs of the school buses that have probably only existed in our imagination prior especially since almost all school buses are yellow.

In April 2022, OpenAI announced DALL-E 2. The company cited its ability to generate more realistic and accurate images with four times greater resolution as its biggest edge over the preceding version, thereby testifying to the visual quality of the images which many have described as stunning. As impressive as that is, the system’s intelligence is even more astonishing. Although OpenAI has not, despite its name, opened up access to DALL-E 2 to all, a community of independent open-source developers have built some text-to-image generators out of other pre-trained models they have access to.
One of these generators is DALL-E Mini. It was recently launched on Hugging Face and took the internet by storm. The software takes its name and a lot of its code from DALL-E 2. I worked with it and here are some key points I was able to note about the system. Not only is the system able to apply a handful of diverse artistic styles to the specified subjects with remarkable fidelity and aptness but more importantly, it is able to capture their spirit/mood. This implies that cartoon images generated with the system are light-hearted, naturalism would be the theme for everyday scenes prompts, impressionist paintings would often come off as peaceful whilst bringing strong feelings to mind and of course, noir photographs created by the system were subtly disturbing. Furthermore, many of the images generated demonstrated DALL-E 2’s remarkable ability to create striking surrealist images.
Bring DALL-E Mini to life now with Gradient, and start generating unique artwork!
If at this point, you find yourself pondering over the workings of DALL-E 2’s algorithm, I think that is fair. In the coming paragraphs, I will explain the algorithm as I would explain it to my cousin who works in the tech ecosystem (not Machine Learning) and then, how I would explain to my elder sibling who is very familiar with machine learning.
EXPLAINING TO MY COUSIN
For a bit of context, it is important to note that in 2015, automated image captioning was developed. At that point, Machine Learning models could already label objects in images, but now they learnt to put those labels into natural language descriptions. Not only did this development make it known that image-to-text conversion was possible, but it also meant that there was a possibility for the flip scenario i.e. text-to-image conversion.
Now, for an image generator to be able to respond to so many different prompts, it needs a massive and diverse training dataset. Ideally, millions of images scraped from the internet along with text descriptions. These captions come from things like the ‘alt’ text that website owners upload with their images for accessibility and search engines. That is how engineers get these giant datasets. But then, what does the model actually do with the dataset? You might assume that when we give it a text prompt like “green ball on a yellow table”, it searches through the training data to find related images and then copy over some of these pixels. However, that assumption is wrong! That is not what happens since the newly generated image does not come from the training data. Instead, it comes from the learned ‘latent space’ of the deep learning model.
When a prompt is inputted, the deep learning algorithm initially goes through all the training data, finds variables that help improve its performance on the task and in the process, it builds out a mathematical space with well more than three dimensions. These axes represent variables that humans would not even recognize or have names for. Each axis would have meaningful clusters. For instance, we could have an axis that captures the essence of banana-ness and another that represents the textures and color of photos from the 1960s. Having created these axes, the text is then transported to a corresponding point in the mathematical space. Lastly, the point in that mathematical space is translated into an actual image. This involves a generative process called diffusion. It starts with just noise and then over a series of iterations, arranges pixels into a composition that makes sense to humans.
EXPLAINING TO MY ELDER SIBLING
At the production level, DALL-E 2 simply takes text as input and produces images as its output. However, this is not done in one go. A rough illustration of the process it takes is shown below.
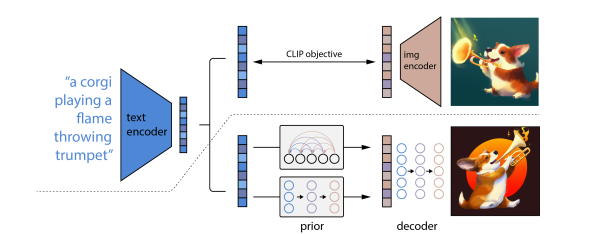
IMAGE CAPTION -> {through a CLIP text embedding} -> PRIOR -> {through a CLIP image embedding} -> DECODER -> IMAGE
As you can tell from the illustration above, to grasp the architecture of DALL-E 2, one needs to first understand CLIP - a crucial building block in DALL-E 2. An acronym for Contrastive Language Image Pre-training, it is a neural network that serves as the link between text and images. Also developed by OpenAI, CLIP does the opposite of what DALL-E 2 does – it returns the best caption for a given image. It is a contrastive model meaning that it matches images to their corresponding captions rather than classify them. To do this in DALL-E 2, it trains two encoders – one that trains images into image embedding and the other turns texts or captions into text embedding. This implies that it is able to create a vector space that represents both the features of images and those of languages. This shared vector space forms the architectural foundation of what gives the DALL-E model a sort of image-text dictionary to translate between one and the other.

Also, a diffusion model as referenced in the earlier explanation is a generative model which works by destroying training data through the iterative addition of Gaussian noise, and then learning to recover the data by reversing the process.
Note to my cousin: This process is similar to having an arranged Rubik cube, scrabbling it whilst taking a mental note of each move and then doing the exact opposite of that till one obtains an arranged Rubiks cube from the scrabbled cube.
Demo - DALL-E
In March 2021, OpenAI made the PyTorch package used for the discrete Variational AutoEncoder (dVAE) in DALL·E public. Discrete VAE (dVAE) which is a variant of VQ-VAE (Vector Quantized Variational Auto encoder) is the auto encoder technique adopted by DALL-E to learn the discrete image representations. Having installed the required libraries, gotten a sample image to work with, preprocessed the sample image, then the code for the application of the PyTorch package takes the look shown below.
from dall_e import map_pixels, unmap_pixels, load_model
from IPython.display import display, display_markdown
import torch.nn.functional as F
z_logits = enc(x)
z = torch.argmax(z_logits, axis=1)
z = F.one_hot(z, num_classes=enc.vocab_size).permute(0, 3, 1, 2).float()
x_stats = dec(z).float()
x_rec = unmap_pixels(torch.sigmoid(x_stats[:, :3]))
x_rec = T.ToPILImage(mode='RGB')(x_rec[0])
display_markdown('Reconstructed image:')
display(x_rec)
You can run this code in a Gradient Notebook by clicking the link below, and opening the usage.ipynb notebook:
Bring this project to life
Demo - DALL-E 2
Finally, DALL-E 2 improves on its preceding version in that it has the ability to edit existing images. For example, we can ‘add a couch’ with respect to an empty living room. Not long after DALL-E 2 was released, OpenAI CEO, Sam Altman tweeted ‘AGI is gonna be wild’. For some context, AGI (Artificial General Intelligence) according to Wikipedia implies the ability of an intelligent agent to understand or learn any intellectual task that a human being can. Basically, general-purpose AI. Now, first of all, I would like to point out that DALL-E 2 is unquestionably extremely impressive in terms of image generation. However, as much as I agree/think that the potential of AGI can be regarded as ‘wild’, I dispute whether DALL-E 2 constitutes progress with regards to solving the deep problems of commonsense reasoning, reliability, comprehension and other qualities that would be needed for a truly general-purpose AI.
AGI is gonna be wild
— Sam Altman (@sama) April 6, 2022
Unfortunately, as mentioned earlier, DALL-E 2 is not yet publicly accessible, though there is a waiting list one can use to apply for access. The incredible LucidRains has, however, created a PyTorch implementation of DALL-E 2, but it is still under development and has no available pre-trained models. Therefore, using DALL-E 2 would require training for each of the sub models for DALL-E 2. The following snippet from the repository details how to train a DALL-E 2 model using the publicly available, pre-trained CLIP model provided by OpenAI.
import torch
from dalle2_pytorch import DALLE2, DiffusionPriorNetwork, DiffusionPrior, Unet, Decoder, OpenAIClipAdapter
# openai pretrained clip - defaults to ViT-B/32
clip = OpenAIClipAdapter()
# mock data
text = torch.randint(0, 49408, (4, 256)).cuda()
images = torch.randn(4, 3, 256, 256).cuda()
# prior networks (with transformer)
prior_network = DiffusionPriorNetwork(
dim = 512,
depth = 6,
dim_head = 64,
heads = 8
).cuda()
diffusion_prior = DiffusionPrior(
net = prior_network,
clip = clip,
timesteps = 100,
cond_drop_prob = 0.2
).cuda()
loss = diffusion_prior(text, images)
loss.backward()
# do above for many steps ...
# decoder (with unet)
unet1 = Unet(
dim = 128,
image_embed_dim = 512,
cond_dim = 128,
channels = 3,
dim_mults=(1, 2, 4, 8),
text_embed_dim = 512,
cond_on_text_encodings = True # set to True for any unets that need to be conditioned on text encodings (ex. first unet in cascade)
).cuda()
unet2 = Unet(
dim = 16,
image_embed_dim = 512,
cond_dim = 128,
channels = 3,
dim_mults = (1, 2, 4, 8, 16)
).cuda()
decoder = Decoder(
unet = (unet1, unet2),
image_sizes = (128, 256),
clip = clip,
timesteps = 1000,
sample_timesteps = (250, 27),
image_cond_drop_prob = 0.1,
text_cond_drop_prob = 0.5
).cuda()
for unet_number in (1, 2):
loss = decoder(images, text = text, unet_number = unet_number) # this can optionally be decoder(images, text) if you wish to condition on the text encodings as well, though it was hinted in the paper it didn't do much
loss.backward()
# do above for many steps
dalle2 = DALLE2(
prior = diffusion_prior,
decoder = decoder
)
images = dalle2(
['a butterfly trying to escape a tornado'],
cond_scale = 2. # classifier free guidance strength (> 1 would strengthen the condition)
)
# save your image (in this example, of size 256x256)You can run run this code in a Gradient Notebook by clicking the link below:
Bring this project to life
CHALLENGES
As great as DALL-E is, it has some loopholes. In a research paper titled Discovering the hidden vocabulary of DALL-E 2 written by Giannis Daras and Alexandros G. Dimakis released in June 2022, a limitation of DALL-E 2 was mentioned. They discovered that DALL-E 2 struggles with texts. What does that mean, you ask? Well, text prompts such as ‘An image of the word car '' often led to generated images that depict gibberish text rather than the text. In the course of their research, it was discovered that the gibberish is in fact, not random. Rather, it reveals a hidden vocabulary that the model seems to have developed internally. This means that some words from this vocabulary can be learnt and used to generate absurd prompts that generate natural images. For instance, if fed with the gibberish text produced earlier, the model would produce images of cars. Also, their research showed that apoploe vesrreaitais means bird and contarra ccentnxnioms luryca tanniounous would sometimes mean bugs and pests. As such, images of cartoon birds could be generated with prompts like “an image of a cartoon apoploe vesrreaitais”.
Concluding thoughts
We can implement DALL-E Mini, DALL-E, and DALL-E 2 (to an extent) to generate varying quality level artificially generated images. Be sure to try out each of them in a Gradient Notebook and take advantage of their free GPU offerings to quickly get started generating your own artificially generated images today!











