
Bring this project to life
CLIP, has been a tool for text-image tasks, widely known for zero-shot classification, text-image retrieval and much more. However, the model has certain limitations due to its short text input, which is restricted to 77. Long-CLIP, released in 22 March 2024, addresses this by supporting longer text inputs without sacrificing its zero-shot performance. This improvement comes with challenges like maintaining original capabilities and costly pretraining. Long-CLIP offers efficient fine-tuning methods, resulting in significant performance gains over CLIP in tasks like long caption retrieval and traditional text-image retrieval. Additionally, it enhances image generation from detailed text descriptions seamlessly.
In this article we will perform zero-shot image classification using Long-CLIP and understand the underlying concept of the model.
CLIP's Limitations
Contrastive Language-Image Pre-training or widely known as CLIP is a vision-language foundation model, which consists of a text encoder and an image encoder. CLIP aligns the vision and language modalities through contrastive learning, a technique widely used in downstream tasks such as zero-shot classification, text-image retrieval, and text-to-image generation.
CLIP is a powerful tool for understanding images and text, but it struggles with processing detailed text descriptions because it's limited to only 77 tokens of text. Even though it's trained on brief texts, it can effectively only handle around 20 tokens. This short text limit not only restricts what CLIP can do with text but also limits how well it understands images. For example, when the text it's given is just a summary, it focuses on only the most important parts of the image and ignores other details. Also, CLIP sometimes makes mistakes when trying to understand complex images with consists of multiple attributes.
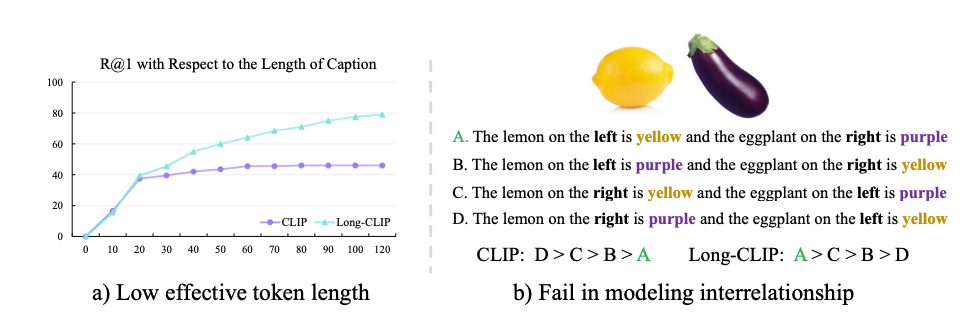
Long texts have a lot of important details and show how different things are connected. So, it's really important to be able to use long texts with CLIP. One way to do this would be to let CLIP handle longer texts and then train it more with pairs of long texts and images. But there are some problems with this approach: it messes up the representation of short texts, it makes the image part too focused on all the little details, and it changes the way CLIP understands things, making it harder to use in other programs.
To address the issues of CLIP, Long-CLIP is introduced. The model has undergone trainign with longer texts and image pairs, and some changes on to how it works to make sure it still understands short texts well. Researchers claims Long-CLIP, we can use longer texts without losing the accuracy of CLIP on tasks like classifying images or finding similar images. Further, Long-CLIP can be used in other programs without the need to change anything.
Overall, Long-CLIP helps us understand images and text better, especially when there are a lot of details to work with.
Zero-Shot Classification
Before diving deep into the methodology of the model, let us first understand what is zero-shot classification.
Supervised learning comes with a cost of learning from the data and sometimes tend to become impractical when there is a lack of data. Anotating large amount of data is time consuming, expensive and incorrect too. Hence with the rise of A.I. there the need for machine learning and A.I. model to be able to work without the need to train the model explicitly on new data points. This need has come with the solution of n-shot learning.
The zero-shot concept emerges from N-shot learning, were the letter 'N' denotes the number of samples required to train the model and make predictions on a new data. The models which require quite some training samples are known as 'Many-shot' learners. These models require a significant amount of compute and data to fine-tune. Hence, in order to mitigate this issue researchers came with a solution of zero-shot.
A zero-shot model requires zero training samples to work on new data points. Typically, in zero-shot learning tests, models are evaluated on new classes they haven't seen before, which is helpful for developing new methods but not always realistic. Generalized zero-shot learning deals with scenarios where models must classify data from both familiar and unfamiliar classes.
Zero-shot learning works by outputing a probability vector which represents the likelihood that the given object belongs to the specific class.
Few-shot learning, uses techniques such as transfer learning (a technique to reuse a trained model for a new task) and meta learning (a subset of ML mainly described as "learning to learn"), which aims to train models capable of identifying new classes with a limited number of labeled training examples. Similarly, in one-shot learning, the model is trained to recognize new classes with only a single labeled example.
Methodology
The model adapts two novel strategies:-
Knowledge Preserving Stretching
The Long-CLIP model efficiency tends to increase as the number of token increases. This indicates the model is able to effectively learn and utilize new peice of information added in the captions.
To tackle the challenge of training a new positional embedding, a popular technique involves interpolation. Typically, a widely adopted approach is linear interpolation of the positional embedding with a fixed ratio, commonly referred to as λ1.
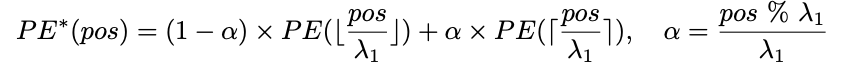
Linear interpolation for this specific task isn't the best choice for adjusting position embeddings in this task. That's because most training texts are shorter than the 77 tokens used in the CLIP model. Lower positions in the sequence are well-trained and accurately represent their absolute positions. However, higher positions haven't been trained as thoroughly and only roughly estimate relative positions. So, adjusting the lower positions too much could mess up their accurate representation.
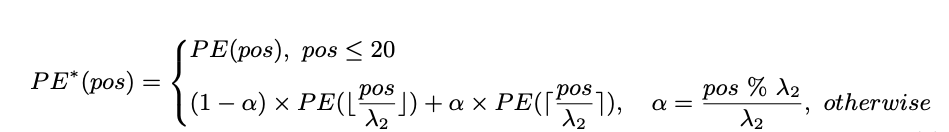
Instead, a different approach is used. The embeddings of the top 20 positions are kept as they are, as they're already effective. But for the remaining 57 positions, a different method called interpolation is used, where we blend their embeddings with those of nearby positions using a larger ratio, denoted as λ2. This way, we can make adjustments without disturbing the well-trained lower positions too much.
Fine-tuning with Primary Component matching
Further, to make the model handle both long and short captions well, extending the length it can handle or simply fine-tune it with long captions wont be of help. That would mess up its ability to deal with short ones. Instead, a method called Primary Component matching is adopted. Here's how it works:
- When fine-tuning with long captions, detailed features of images are matched with their long descriptions.
- At the same time, broader features are extracted from images that focuses on key aspects.
- These broader features are then aligned with short summary captions.
- By doing this, the model not only learns to capture detailed attributes but also understands which ones are more important.
- This way, the model can handle both long and short captions effectively by learning to prioritize different attributes.
So, we need a way to extract these broader image features from detailed ones and analyze their importance.
Comparison with CLIP
The model is compared to CLIP with three downstream tasks such as:-
1.) zero-shot image classification
2.) short-caption image-text retrieval
3.)long-caption image-text retrieval
The below tables shows the results of the comparison.
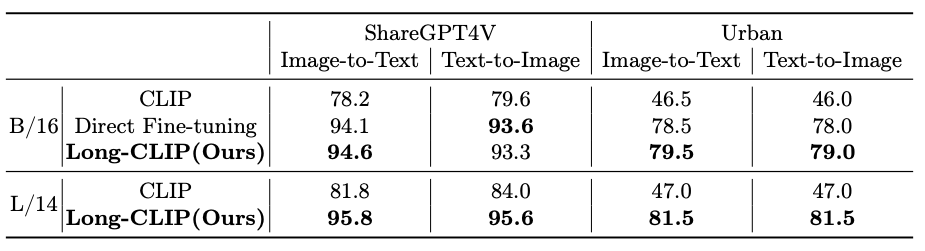
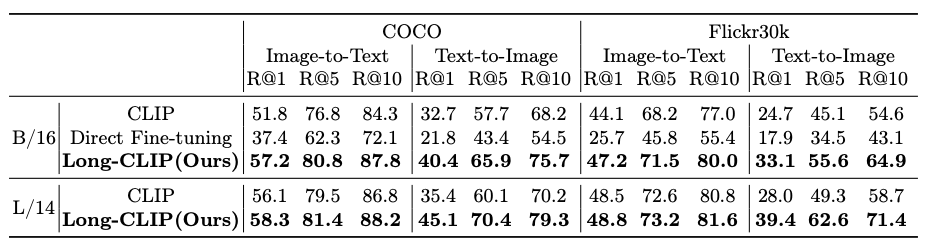
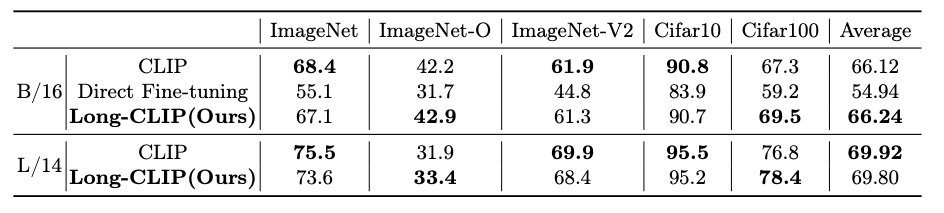
To get the detailed comparison results we highly recommend the original research paper.
Working with Long-CLIP
Bring this project to life
To start experimenting with Long-CLIP, click the link provided with the article, this will clone the repo or follow the steps:-
- Clone the repo and install necessary libraries
!git clone https://github.com/beichenzbc/Long-CLIP.gitOnce this step is executed succesfully, move to the Long-CLIP folder
cd Long-CLIP- Import the necessary libraries
from model import longclip
import torch
from PIL import Image
import numpy as npDownload the checkpoints from LongCLIP-B and/or LongCLIP-L and place it under ./checkpoints
- Use the model to output the predicted prababilities on any image, here we are using the below image.

device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = longclip.load("./checkpoints/longclip-B.pt", device=device)
text = longclip.tokenize(["A cat jumping.", "A cat sleeping."]).to(device)
image = preprocess(Image.open("./img/cat.jpg")).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs)# Label probs: [[0.00201881 0.99798125]]The model accurately conducts zero-shot classification and provides the probability of the image as its output.
Conclusion
In this article, we introduced Long-CLIP, a powerful CLIP model capable of handling longer text inputs up to 248 tokens. The recent research shows that the model has shown significant improvements in retrieval tasks while maintaining performance in zero-shot classification. Further, researchers claims that the model can seamlessly replace the pre-trained CLIP encoder in image generation tasks. However, it still has limitations regarding input token length, even though greatly improved compared to previous model. By leveraging more data, particularly long text-image pairs, the scaling potential of Long-CLIP is promising, as it can provide rich and complex information, enhancing its overall capabilities.








