
Bring this project to life
In the past few months, Google has introduced its Gemini models—large and mid-sized models meant for complex tasks. Gemma is part of the Gemini AI family, aimed at making AI development accessible and safe. This newly launched Gemma, however, is a lightweight, smaller model aimed at helping developers worldwide build AI responsibly, in compliance with Google’s AI principles.
This article will explore the Gemma model, training processes, and performance comparison across various benchmarks. It also includes a code demo to implement the Gemma model and other project ideas that can be implemented using this model.
What is Google’s Gemma?

The Gemma model is a family of lightweight, state-of-the-art open models developed by Google DeepMind. These models demonstrate academic solid performance in terms of language understanding, reasoning, and safety benchmarks.
The Gemma models come in two sizes, with 2 billion and 7 billion parameters, and both provide pre-trained and fine-tuned checkpoints. They outperform similarly sized open models on 11 out of 18 text-based tasks and have undergone comprehensive evaluations of safety and responsibility aspects. The development of the Gemma models involved training on up to 6T tokens of text using similar architectures, data, and training.
The Gemma model architecture is based on the transformer decoder, with core parameters such as the number of layers, feedforward hidden dimensions, number of heads, head size, and vocabulary size.
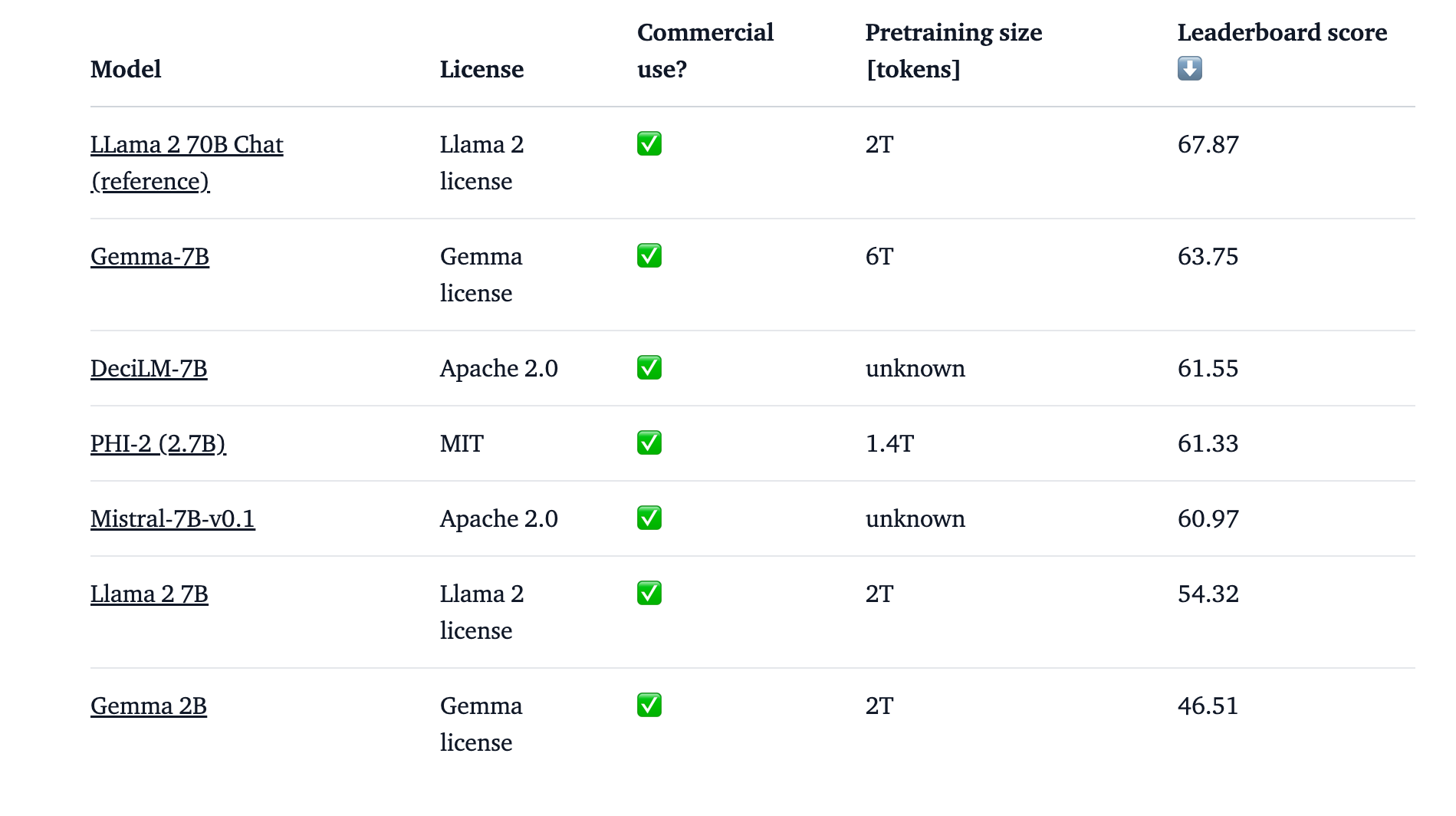
Gemma 7B and Gemma 2B are compared with other models like PHI-2,including Mistral 7B. Gemma 2B doesn't score as high as in the leaderboard in comparison to other models.But Gemma 7B scored good on leader board in comparison to Mistral and Llama 7B.
How is Gemma Trained?
Gemma 2B and 7B models were trained on 2T and 60 tokens and data sources like web docs, code, and mathematics. Before training, carefully filter and removes unwanted or unsafe content, including personal and sensitive data.
Supervised Fine-Tuning (SFT)
- Training of the Gemma model is done with a mix of real and made-up conversations (prompts and responses) where humans give instructions.
- To pick the best training data, a more extensive Gemma model checks which responses are better based on human preferences.
- Training data is cleaned by removing personal info, harmful content, and repeated stuff.
- This step helps Gemma understand instructions and respond accordingly.
Reinforcement Learning from Human Feedback (RLHF)
- Even after training with instructions, Gemma might make mistakes.
- Here, humans directly tell Gemma which responses they prefer, helping it learn from their feedback.
- The model is trained to produce responses with higher rewards, essentially teaching it to generate the types of responses humans liked more.
- Baseline models check the high-capacity models and ensure they learn the right lessons (e.g., tricking the system to get better scores without improving).
- A capacity model as an automatic rater is used to compute side-by-side comparisons against baseline models.
Comparison of Gemma with Other Models
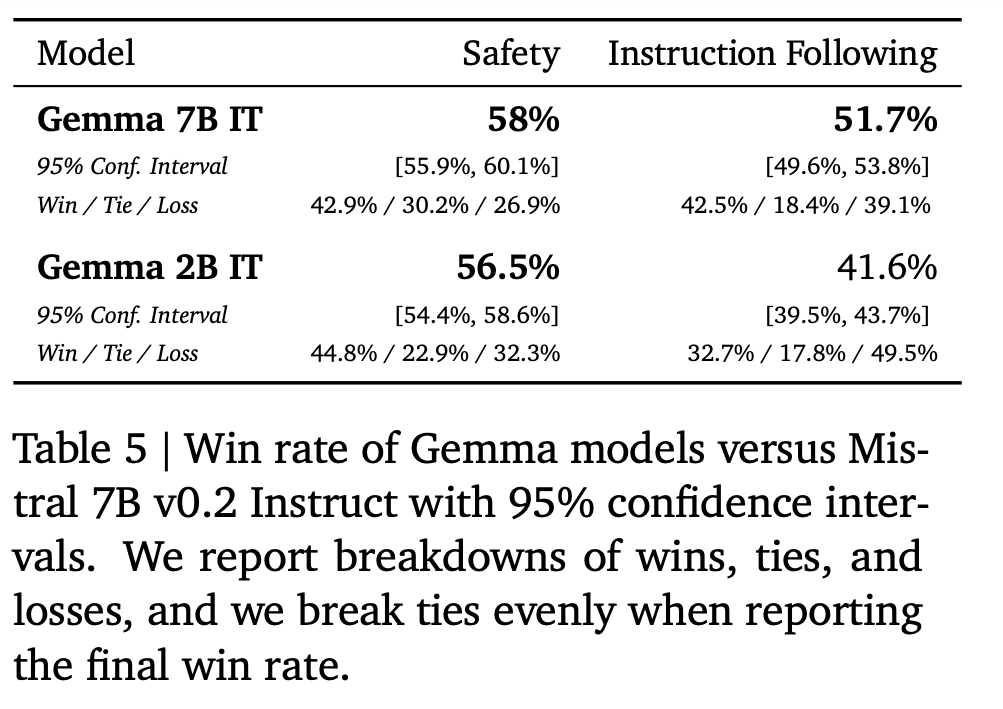
- Test Setup
- Two held-out collections of prompts were used:
- 1000 prompts: Focused on instruction following in various tasks.
- 400 prompts: Focused on testing basic safety protocols.
- Two held-out collections of prompts were used:
- Winning Model
- Instruction Following: Gemma 7B IT emerged victorious with a 51.7% positive win rate, followed by Gemma 2B IT (41.6%) and then Mistral v0.2 7B Instruct.
- Safety Protocols: Gemma 7B IT again secured a 58% positive win rate, closely followed by Gemma 2B IT (56.5%).
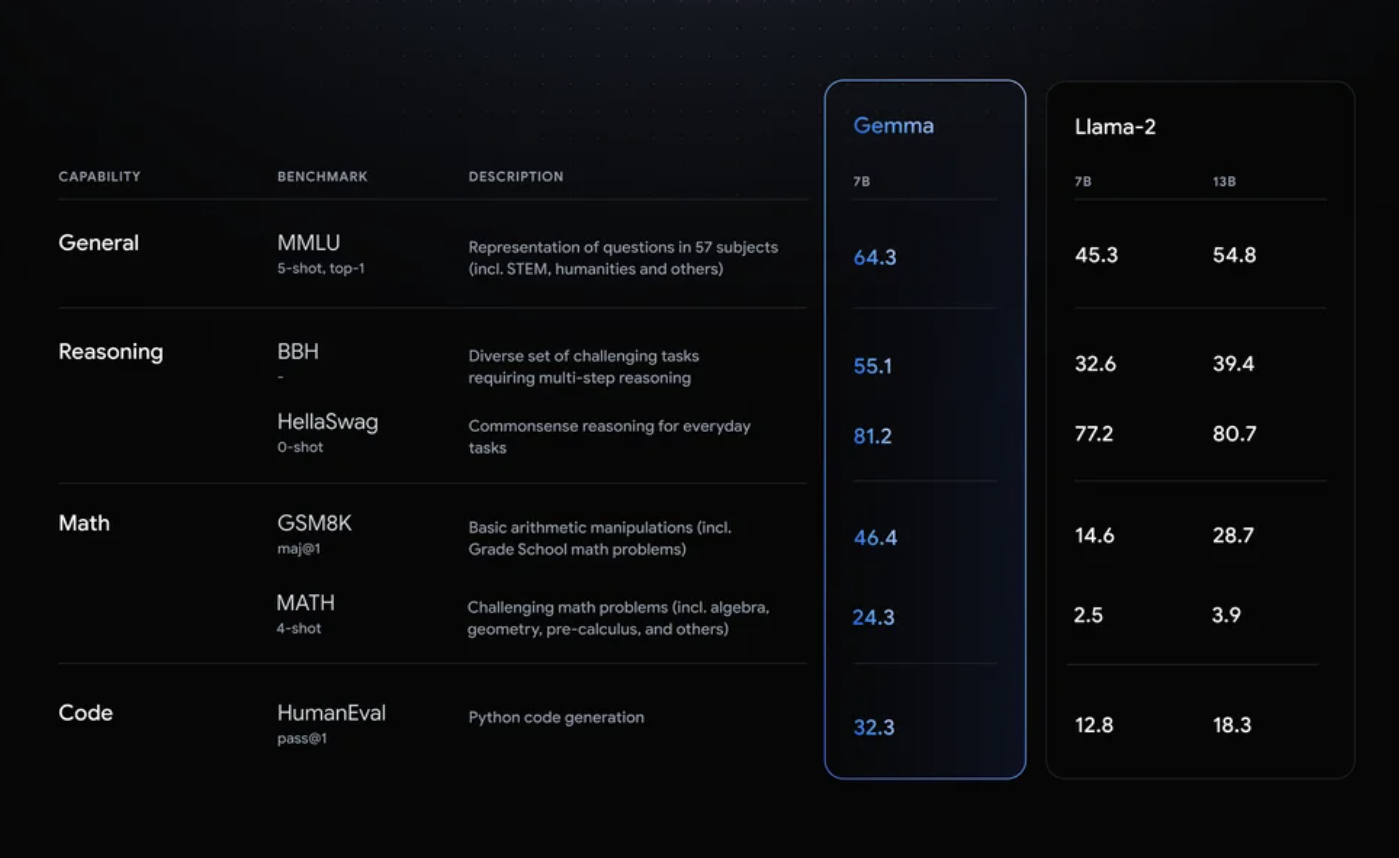
As shown in the above figure, Gemma 7 B is compared with LLama -2 7 B and 13 B on various benchmarks.
Gemma consistently outperformed Llama 2 in all these domains.
- Reasoning: Gemma scored 55.1 on the BBH benchmark compared to Llama 2's score of 32.6.
- Mathematics: Gemma scored 46.4, while Llama 2 lagged behind at 14.6.
- Complex Problem-Solving: In the MATH 4-shot benchmark, Gemma scored 24.3, which is significantly higher than Llama 2's 2.5 score.
- Python Code Generation: Gemma scored 32.3, outpacing Llama 2’s score of 12.8.
Comparison with Mistral Model
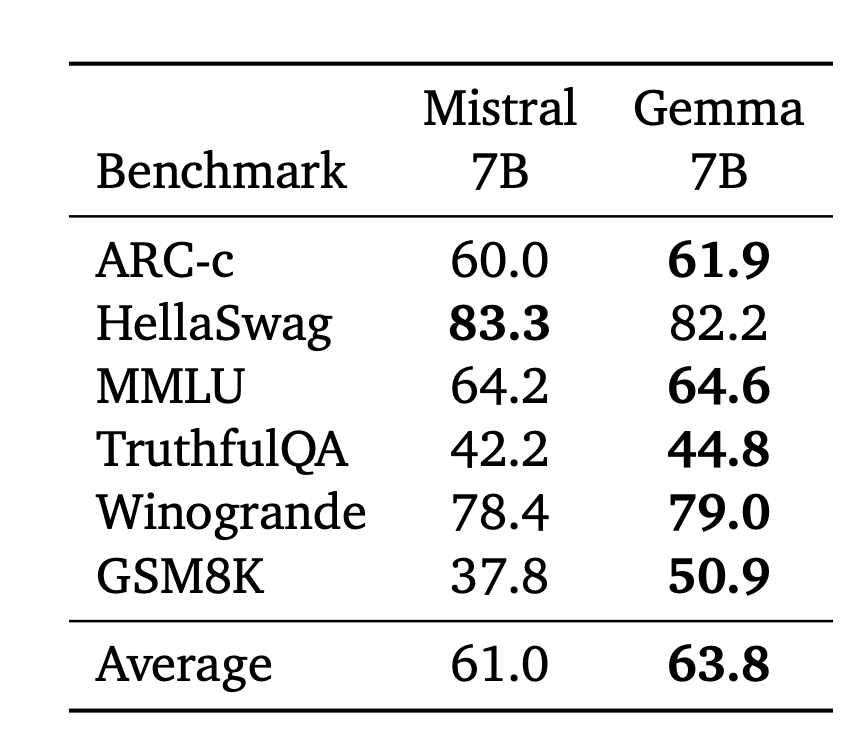
- Gemma 7B outperforms Mistral 7B across various capabilities, such as question answering, reasoning, math/science, and coding. So, in terms of language understanding and generation performance, Gemma is better than Mistral.
- Across different benchmarks such as ARC-c, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K, Gemma models show competitive performance compared to Mistral.
- On academic benchmarks like RealToxicity, BOLD, CrowS-Pairs, BBQ Ambig, BBQ Disambig, Winogender, TruthfulQA, Winobias, and Toxigen, Gemma models exhibit higher scores as compared to Mistral.
Demo
Bring this project to life
First signup on Paperspace. Choose the GPU, template and auto-shutdown time and get started.
Installing the dependencies
First, install all the dependencies.
!pip install datasets pandas transformers
!pip install -U transformers
!pip install accelerate
!pip install -U sentence-transformers
To access the model, you will also need a HuggingFace access token. You can generate one by going to Settings, then Access Tokens in the left sidebar, and clicking on the New token button to create a new access token.
Now the access token is generated, but where should it be pasted? For that, write the following code.
from huggingface_hub import notebook_login
notebook_login()Now, paste the access token and get access to the Gemma model.
Prepare Input for the Model and Generating Response
Load and prepare dataset
from datasets import load_dataset
import pandas as pd
from sentence_transformers import SentenceTransformer
from transformers import AutoTokenizer, AutoModelForCausalLM
dataset = load_dataset("AIatMongoDB/embedded_movies", split="train")
dataset = dataset.remove_columns(["plot_embedding"]).to_pandas()
dataset.dropna(subset=["fullplot"], inplace=True)
# Function to generate response using Gemma model
def generate_response(query):
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it", use_auth_token="hf_v")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b-it", use_auth_token="hf_v")
# Prepare input for the model
input_ids = tokenizer(query, return_tensors="pt").input_ids
# Generate a response
response = model.generate(input_ids, max_length=500, max_new_tokens=500, no_repeat_ngram_size=2)
return tokenizer.decode(response[0], skip_special_tokens=True)AIatMongoDB/embedded_movies dataset is loaded from the HuggingFace datasets library. This dataset appears to contain movie data, including plots. Rows with missing values in the fullplot column are dropped. The use_auth_token parameter is used for authentication with the Hugging Face API, suggesting that the model is hosted in a private repository or requires API access.
Prepare Input for the Model and Generating Response
# Example query
query = "What is the best romantic movie to watch and why?"
# Generate response
print(generate_response(query))The query is tokenised and converted into a format that the model can understand (input_ids). The model generates a response based on the input query. Some parameters are passed, such as max_length of the output, max_new_tokens to limit the number of new tokens generated, and no_repeat_ngram_size to avoid repeating n-grams in the output.
The generated response is then decoded from its tokenised form into human-readable text and returned.
Try this Assignment on Paperspace Gradient!!!
We have implemented Gemma 2B, so Gemma 7B can be used for better results for the following project ideas:
1. Generating personalised news digests for users based on their interests, summarising articles from various sources.
2. Developing an interactive tool that uses Gemma to provide language learning exercises, such as translations, filling in the blanks, or generating conversational practice scenarios.
3. Creating a platform where users can co-write stories with Gemma, choose plot directions, or ask Gemma to develop certain story aspects.
Closing Thoughts
As we stand on the brink of a new era in artificial intelligence, it's clear that models like Gemma will play a crucial role in shaping the future. For developers and researchers eager to explore the potential of Gemma and harness its power for their projects, now is the time to dive in. With resources like Paperspace GPUs available, you have everything you need to start experimenting with Gemma and unlock new possibilities in AI development. So, embark on this exciting journey with Gemma, and let's see what incredible innovations we can bring to life together.










