
Bring this project to life
NLP stands out as one of the most widely adopted sub-disciplines of Machine/Deep Learning. Its prominence has become even more evident due to the widespread integration of Generative Pretrained Transformer (GPT) models like ChatGPT, Alpaca, Llama, Falcon, Bard, and numerous others across diverse online platforms.
With the advancement of these models, there's a huge focus on making them more accessible to all. Open-source models are particularly important in this effort, enabling researchers, developers, and enthusiasts to explore their complexities, customize them for specific purposes, and expand upon their fundamentals.
In this blog post, we will explore the Falcon LLM model which is ranking top on Hugging Face leaderboard as the largest open-source LLMs. Falcon's massive success is making waves in the AI community, with some going so far as to call it an official Llama Killer. To further explore Falcon LLM, we have included a demo on how to run Falcon 40b within a Paperspace notebook. In this code demo we will run Falcon 40b, using the A4000x2 GPU, equipped with 90GB of VRAM, and the cost will be only $1.52 per hour.

Introduction to Falcon - a new entrant in the LLM domain
The Technology Innovation Institute (TII) in the United Arab Emirates (UAE) has revealed Falcon 180B on 6th September 2023, the most extensive open-source large language model (LLM) currently available, boasting a reported 180 billion parameters. This model was trained using 3.5 trillion tokens, with a context window of 2048 tokens. That is 4x times the amount of data used to train Llama 2.
The model training utilized 4096 A100 40GB GPUs, using a 3D parallelism strategy (TP=8, PP=8, DP=64) combined with ZeRO. In addition to that, the model underwent training for approximately 7,000,000 GPU hours. Falcon 180B exhibits a 2.5 times greater speed compared to LLMs like Llama 2.
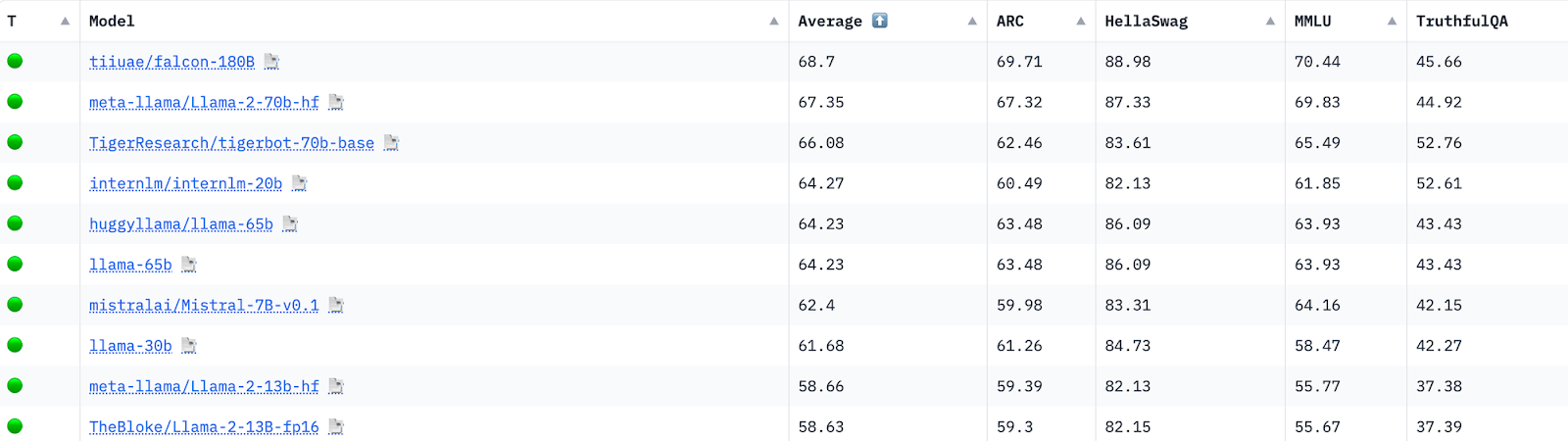
The model also outperforms Llama 2 in multi-task language understanding (MMLU) tasks. This open LLM tops the Hugging Face leaderboard for pre-trained models and is available for research and commercial purposes. It also matches Google's PaLM 2-Large on HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC, ReCoRD.
Furthermore, they found that, all together in aggregate, they were able to show that Falcon 180B has accuracy comparable to the top-of-the-line PaLM-2 Large model. Falcon has proven to be a competitor for PaLM-2 and GPT-3 as well and is just behind GPT-4.
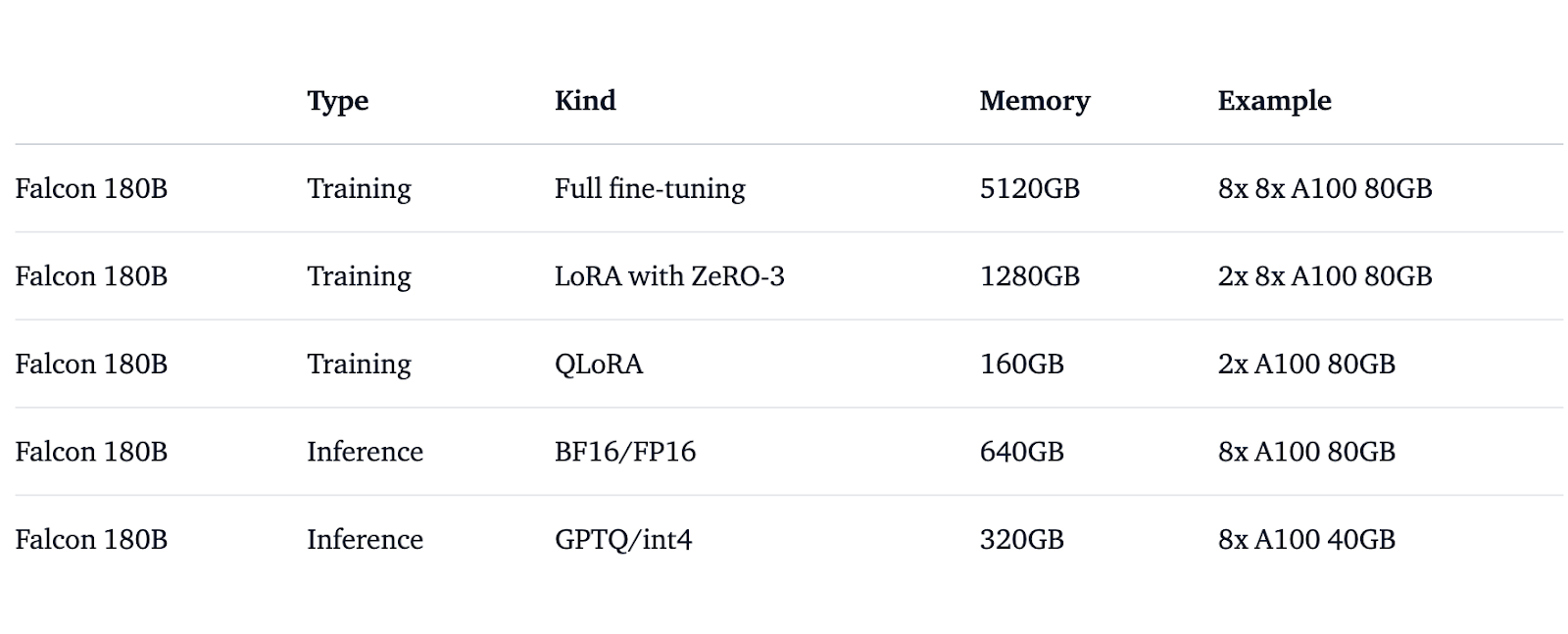
It's important to highlight that the model's size requires a minimum of 320GB of memory for proper functioning, which could entail a significant investment in resources.
Brief overview of large language models
Large Language Model or LLMs are deep learning algorithms that are designed to perform Natural Language Processing (NLP) tasks. The base of any LLMs are typically Transformers blocks, and these models are often trained on massive amounts of data. The Big Data training required to make an LLM is the reason it is called the Large Language Model.
Apart from instructing AI applications in human languages, large language models can be trained for diverse tasks, including interpreting protein structures, generating software code, and more. To perform these specific tasks these LLMs similar to the human brain require training and fine tuning. Their problem-solving abilities find application in healthcare, finance, and entertainment, where large language models support various NLP tasks like translation, chatbots, and AI assistants.
The LLMs are usually trained on a massive number of hyperparameters and training data which helps the model to understand the pattern of the data.
Falcon's architecture and design
As we understood, the base architecture of any LLMs is the Transformer model which consists of an encoder and a decoder.
Transformers in Large Language Models (LLMs) work by employing the Transformer architecture. This structure allows these models to process and understand language by using self-attention mechanisms. In simpler terms, transformers handle input data in a parallel manner, enabling them to consider the entire context of a sentence or piece of text.
Each word or token in a sentence is embedded into a high-dimensional space. Transformers then apply attention mechanisms allowing every word to 'attend' or contribute to the understanding of every other word in the sentence. This mechanism helps capture the relationships between words and their contextual meaning within the sentence.
Transformers in LLMs are made up of multiple layers, each containing a series of self-attention mechanisms and feedforward neural networks. This multi-layered approach allows for sophisticated language understanding and generation. The model learns to represent the text data in a way that helps in various natural language processing tasks, such as text generation, sentiment analysis, language translation, and more.
Falcon 180B, an evolution from Falcon 40B, expands upon its innovations, including multiquery attention for enhanced scalability. Trained on up to 4096 GPUs, totaling around 7,000,000 GPU hours, it is 2.5 times larger than Llama 2 and utilized four times the computational power to train.
The training dataset primarily comprises RefinedWeb data, accounting for approximately 85% of the dataset. RefinedWeb data is a novel massive web dataset which is based on CommonCrawl. Additionally, it has been trained using a combination of carefully curated information, including discussions, technical papers, and a minor portion of code, constituting around 3% of the dataset.
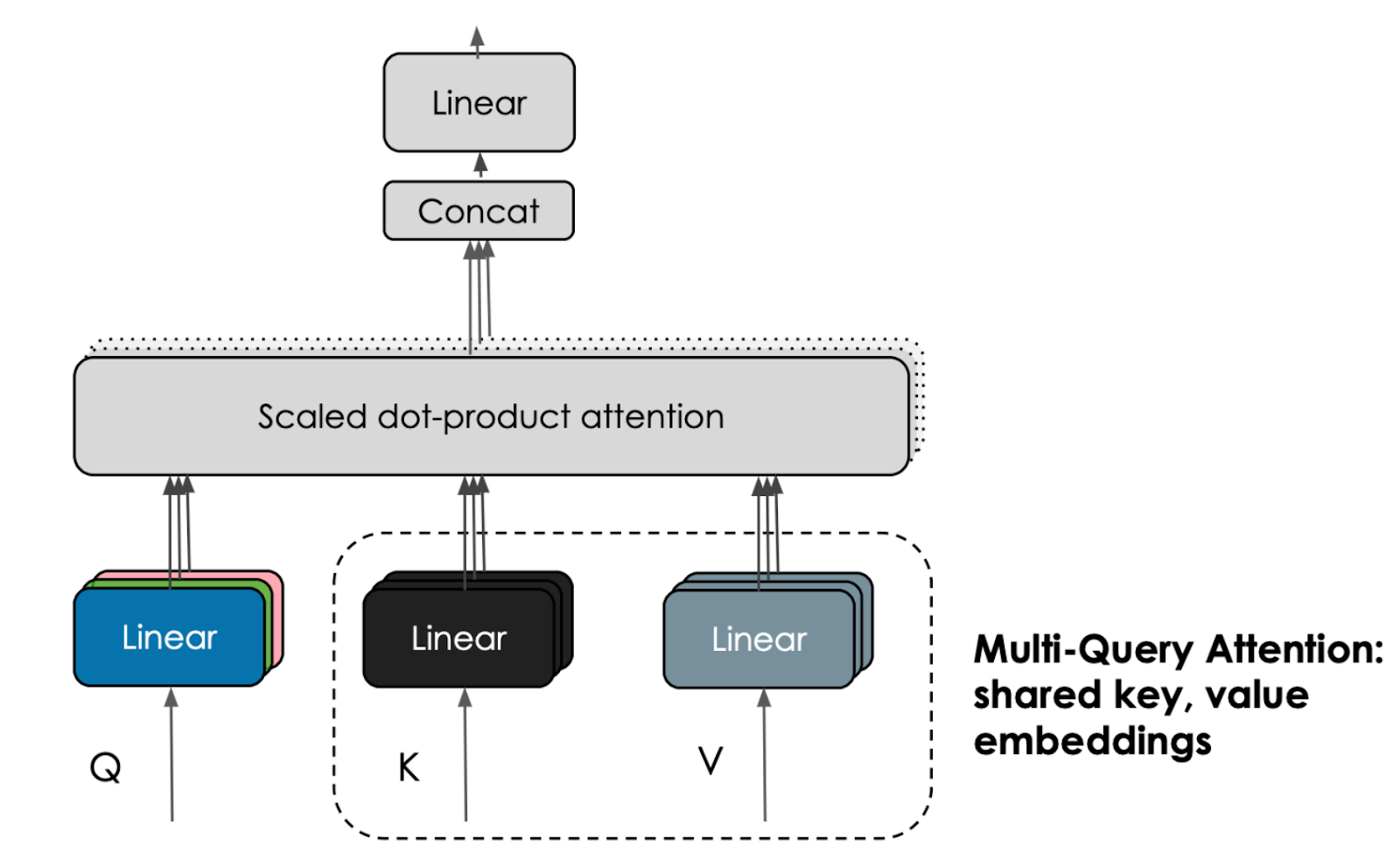
The Falcon 180B architecture is roughly adapted from the GPT-3 paper (Brown et al., 2020), with a few key differences such as:
- Positional embeddings: (Su et al., 2021);
- Attention: multiquery (Shazeer et al., 2019) and FlashAttention (Dao et al., 2022);
- Decoder-block: parallel attention/MultiLayer Perceptron (MLP) with two layer norms.
Falcon's architecture is fine-tuned for inference, surpassing leading models like those developed by Google, Anthropic, Deepmind, and LLaMa, as demonstrated by its performance on the OpenLLM Leaderboard.
Comparison with existing language models
- Falcon 180 billion is significantly bigger when compared to GPT-3 which has 175 billion parameters. Falcom 180b scores lies in between GPT-3.5 and GPT-4
- All of the LLMs are trained on a massive dataset. The exact training size of the GPT model is not clear as GPT models are still closed source. However, Falcon 180b is trained on 3.5 trillion tokens using TII’s RefinedWeb dataset
- In terms of scale, Falcon 180B is 2.5 times larger than Meta's LLaMa 2 model, which was previously regarded as one of the most capable open-source LLMs. Falcon 180B, with a score of 68.74 on the Hugging Face Leaderboard, has achieved the highest ranking among openly released pre-trained LLMs, surpassing Meta’s LLaMA 2, which scored 67.35
- Falcon is an open source and permits commercial usage unlike Open AI's GPT models
- Falcon 180B not only exceeds LLaMa 2 but also surpasses other models in both scale and benchmark performance across various natural language processing (NLP) tasks
Falcon 180B is currently the largest accessible language model, exceeding both its predecessors and competitors in size. Please feel free to access the blog post link on Paperspace Platform for an extensive explanation of the GPT model architecture.
Advantages of Falcon over existing models
Falcon and its variants - 1B, 7B, 40B, 180B have gained immense recognition as the most powerful open-source language model to date. This powerful LLM is evident in the Hugging Face Leaderboard. Also, being open source will empower researchers and innovators to explore the model closely.
Meticulous filtering and relevance checks guarantee the inclusion of top-quality data. Building a strong data pipeline for efficient processing was crucial, as high-quality training data significantly influences language model performance. TII researchers utilized advanced filtering and de-duplication methods to extract superior content from the web.
Apart from English, this LLM possesses an understanding in German, Spanish, and French. They also exhibit basic proficiency in multiple European languages such as Dutch, Italian, Romanian, Portuguese, Czech, Polish, and Swedish. This extensive linguistic range broadens Falcon's potential applications across diverse language contexts.
While LLaMA's codes are open sourced in github, the weight of the model is still hidden hence possessing a limitation on the usage. Falcon which employs a modified Apache license enabling the LLM for fine-tuning and commercial application.
Hardware Requirements
Falcon has been released as the open source LLM for research and commercial purposes. The requirement of large amounts of memory and expensive GPU to run the model remains a downside of the Falcon 180b.
To run the model, it requires 640GB of memory that is 8 X A100 80GB GPUs quantized to half precision. Furthermore, if quantized down to int4, it requires 320GB of memory that is 8 X A100 40GB GPUs.
Addressing potential limitations and challenges
The primary concern is the considerable resource demand of the Falcon 180B. For optimal performance, the model necessitates a substantial 400GB of VRAM, which equates to approximately five A100 GPUs. These high specifications render the model inaccessible for most medium-sized businesses and pose a significant challenge for many researchers.
The base model does not come with a predefined prompt format. It's important to note that it is not designed for generating conversational responses, as it hasn't been trained with specific instructions. While the pretrained model serves as a solid foundation for further fine-tuning, using it as-is for generating conversation may not yield optimal results. The chat model follows a straightforward conversation structure.
The cost to run inference on this model adds up to thousands of dollars, which again is not feasible for many researchers and AI enthusiasts.
Apart from the immense resource needs, there's a scalability issue. The model is nearing a point where adding more parameters to a model won't gain further significant results. Every technology, including AI models, has boundaries. This raises concerns about the sustainability of continually increasing model size. In short, there's a limit to the advancements we can achieve through this approach. This approach might have a chance to make LLAMA 2 a more practical choice for many in the open-source sphere.
Last but not least, the current trend shows a race to be the biggest and the best without considering the practicalities of real world applications. The focus shouldn't solely revolve around the magnitude and dimensions of these models, but rather on their practicality, effectiveness, and broader utility for a more extensive user base.
On the contrary, smaller models are capable of running effectively on standard consumer hardware, offering users the ability to fine-tune and personalize them according to their requirements.
Falcon 40b in Action using Paperspace Platform
In this tutorial we will load and run Falcon 40b using Paperspace platform.
Running the 40b parameter might lead to memory issues and also can be expensive. Memory issues might still persist even when utilizing Nvidia A100 GPUs and 45 GB RAM. However, with the diverse range of Paperspace GPUs one can execute the model at an affordable price. In this code demo we used a Notebook powered by a A4000x2 GPU enabled machine, equipped with 90GB of VRAM, with a cost of only $1.52 per hour.
Bring this project to life
- We start by Installing the required libraries to run the model
#install the dependencies
!pip install -qU transformers accelerate einops langchain xformers bitsandbytes- The below code is used to initialize and load a pre-trained model for language modeling using the Hugging Face Transformers library. Let us understand the code by further breaking it down into parts.
#import necessary libraries to get the model running
import torch
from torch import cuda, bfloat16
import transformers
#Store the pre trained model to the variable
model_name = 'tiiuae/falcon-40b'
#Determines the computing device to be used for model inference. If a CUDA-enabled GPU is available, it sets the device to the GPU (specifically, the current CUDA device); otherwise, it defaults to the CPU.
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
# set quantization configuration to load large model with less GPU memory
# this requires the `bitsandbytes` library
bnb_config = transformers.BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=bfloat16
)
model = transformers.AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
quantization_config=bnb_config,
device_map='auto'
)
model.eval()
print(f"Model loaded on {device}")- Quantization Configuration (bnb_config): The code sets up a quantization configuration using the BitsAndBytesConfig class from the transformers library. Quantization is a technique to reduce the memory footprint of a model. The configuration includes parameters such as loading in 4-bit precision, specifying the quantization type, using double quantization, and setting the compute data type to bfloat16.
- model = transformers.AutoModelForCausalLM.from_pretrained(...): This line of code loads the pre-trained model for language modeling using the specified model name ('tiiuae/falcon-40b'). It utilizes the AutoModelForCausalLM class from the Transformers library.
- model.eval(): This puts the loaded model in evaluation mode. In PyTorch, this typically disables dropout layers, which are commonly used during training but not during inference.
- print(f"Model loaded on {device}"): Next, print the message indicating on which device the model has been loaded, whether it's the GPU (specified by CUDA) or the CPU.
This code will take approximately 30 min to load the pre-trained model with the specified quantization configurations, considering the GPU availability and usage.
- Create the tokenizer,
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
- Next, use the Hugging Face Transformers library to convert token sequences into their corresponding token IDs.
The main objective of the code is to convert specific token sequences into their numerical representations a.k.a (token IDs) using a tokenizer, and store the results in the stop_token_ids list. These token IDs could be used as stopping criteria during the model training.
from transformers import StoppingCriteria, StoppingCriteriaList
#take a list of tokens (x) and convert them into their corresponding token IDs using the tokenizer.
stop_token_ids = [tokenizer.convert_tokens_to_ids(x) for x in [['Human', ':'], ['AI', ':']]]
stop_token_ids- We will convert each integer value in the stop_token_ids list into a PyTorch LongTensor and then move the resulting tensors to a specified device.
import torch
#converting each integer value in stop_token_ids into a PyTorch LongTensor and moving it to a specified device
stop_token_ids = [torch.LongTensor(x).to(device) for x in stop_token_ids]
stop_token_ids- The below code sets up a text generation pipeline using the Hugging Face Transformers library. The resulting generate_text object is a callable function that, when provided with a prompt, will generate text based on the specified configuration. This pipeline simplifies the process of interacting with our pre-trained Falcon 40b model for text generation tasks. Let us understand the steps along with the code.
#create the model pipeline
generate_text = transformers.pipeline(
model=model, #pass the model
tokenizer=tokenizer, #pass the tokenizer
return_full_text=True, #to return the original query, making it easier for prompting.
task='text-generation', #task
# we pass model parameters here too
stopping_criteria=stopping_criteria, #to eliminate unnecessary conversations
temperature=0.3, #for 'randomness' of model outputs, 0.0 is the min and 1.0 the max
max_new_tokens=512, #max number of tokens to generate in the output
repetition_penalty=1.1 #without this output begins repeating (make sure to experiment with this)
)- generate_text = transformers.pipeline(...): This line instantiates a text generation pipeline using the pipeline function from the Transformers library. It takes in the below mentioned parameters.
- model=model and tokenizer=tokenizer: These parameters specify the pre-trained language model that needs to be considered and the tokenizer to be used in the text generation pipeline. These parameters we have already declared in our previous code.
- return_full_text=True: This parameter indicates that the generated output should include the original query.
- task='text-generation': This parameter specifies the task for the pipeline, in this case, text generation.
- stopping_criteria=stopping_criteria: This parameter uses a stopping criteria previously defined in the code. Stopping criteria are conditions that, when met, halt the text generation process. This can be useful for controlling the length or quality of the generated text. Please use this parameter cautiously.
- temperature=0.3: Temperature is a hyperparameter that controls the randomness of the model's output. Lower values (closer to 0) make the output more deterministic, while higher values (closer to 1) introduce more randomness.
- max_new_tokens=512: This parameter sets the maximum number of tokens to generate in the output. It can also be used to limit the length of the generated text. Feel free to experiment with this parameter.
- repetition_penalty=1.1: Repetition penalty is a hyperparameter that adds a penalty to the model from repeating the same tokens in its output. It helps in generating more diverse text.
- Next we will generate the output,
#generate output
res = generate_text("Explain to me the difference between centrifugal force and centripetal force.")
print(res[0]["generated_text"])
#generate sequential output
sequences = generate_text("Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
Please click on the demo link to view the entire code and experiment with the code and the model.
Bring this project to life
Future Developments in LLM and Impacts
The size of the global AI market is estimated to rise up to $1,811.8 billion by 2030.
Within the realm of AI, Natural Language Processing (NLP) is experiencing significant attention, with forecasts suggesting the global NLP market will surge from $3 billion in 2017 to a projected $43 billion by 2025 (Source). With the development of no code platforms LLMs are emerging as the cutting edge technology to boost business growth and reduce human effort.
Furthermore future LLMs have additional properties to fact check the information themselves. Doing this will make the model more reliable and better suited for real-world applications.
As of now LLMs are still behind humans when it comes to language understanding and due to this sometimes provides incorrect information. To solve these issues the demand for prompt engineers are increasing. These engineers specializing in prompt engineering can enhance the model's ability to produce more pertinent and precise responses, even when dealing with intricate inquiries. Two widely recognized methods in prompt engineering include Few-Shot Learning and Chain of Thought prompting. Few-Shot Learning involves crafting prompts containing a few comparable instances along with the intended result, acting as navigational aids for the model to generate responses. Chain of Thought prompting comprises a series of strategies tailored for tasks requiring logical reasoning or step-by-step computation.
In addition to conventional fine-tuning methods, new emerging approaches aim to augment the precision of LLMs. For example is Reinforcement Learning from Human Feedback (RLHF), a method employed in the training of ChatGPT. Similarly, Fine-Tuning with PEFT (Parameter Efficient Fine Tuning) is used for Falcon. Using the PEFT library, the fine-tuning procedure utilizes the QLoRA method, incorporating adapters for fine-tuning over a locked 4-bit model.
Emerging ideas such as integrating quantum computing into expansive language models mark the evolving landscape of innovations in LLMs. It's an exhilarating prospect to anticipate how forthcoming advancements will tackle the persisting challenges encountered by these language models.
Concluding Thoughts
The Falcon LLMs have demonstrated impressive capabilities when compared to closed-source LLMs. Hugging Face's leaderboard has indicated its potential to compete with Google’s PaLM 2, the language model supporting Bard, emphasizing that it surpasses the performance of GPT-3.5. However, to run the Falcon 180b, one needs to pay attention to GPU requirements, RAM and VRAM.
Although the larger Falcon models such as 40b and 180b demand significant computational resources, the smaller 7B variant can be operated on using low-cost or free Paperspace GPUs. Refinement is achievable via QLoRA, PEFT, and SFT Trainer.
The release of Falcon 180B underscores the rapid evolution of AI, emphasizing that no single provider will indefinitely dominate the market. Despite OpenAI's initial lead with ChatGPT, competitors continuously advance, making it challenging for any provider to maintain a distinctive edge as others enhance their performance.
In this article, we covered a brief introduction to Falcon 180b and included a code demo to run Falcon 40b using the Paperspace platform. We also understood a few relevant topics in the realm of Large Language Model. Also, Falcon 180b is a powerful open source model. This much is abundantly clear from our experimentation. We have made this LLM accessible through the robust infrastructure and a wide range of GPUs provided by Paperspace.
Please feel free to test out this tutorial! Thank you for reading.
Additional Resources and References
- Paperspace blog on LLM and GPT models: Navigating the Large Language Model revolution with Paperspace
- Official Hugging Face Page: tiiuae (Technology Innovation Institute)
- Hardware setup required: Hardware requirements for Falcon 180b
- What are LLMs
- Fine-tuning large language models in practice: LLaMA 2
- Top AI Statistics And Trends In 2023
- Revenues from the natural language processing (NLP) market worldwide from 2017 to 2025
- Code Reference
- Implementation of stopping criteria
- Detailed Parameter: https://huggingface.co/docs/api-inference/detailed_parameters











