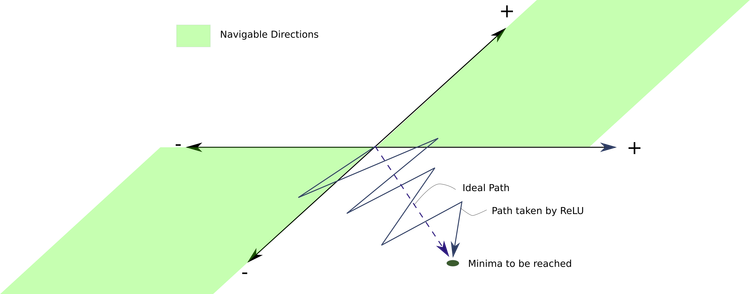
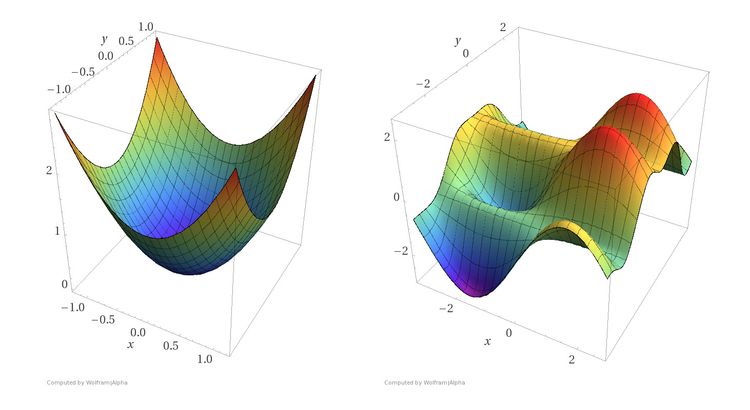
Intro to Optimization in Deep Learning: Busting the Myth About Batch Normalization
Batch Normalisation does NOT reduce internal covariate shift. This posts looks into why internal covariate shift is a problem and how batch normalisation is used to address it.
8 years ago