This article covers a detailed study about tackling the problem of natural language question-answering on tabular data. We will cover a few approaches which use deep learning and go in-depth on the architecture and the datasets used and compare their performance using suitable evaluation metrics.
Answering questions on tabular data is a research problem in NLP with numerous approaches to reach a solution. Some involve a heuristic method to break down the natural language input and translate it to be understandable by structured query languages, while others involve training deep learning models.
A good solution would cover the following:
- Understand the relationships between the columns and values
- Have a good semantic understanding of the natural language query
- Preserve efficiency in performance, memory, and cross-domain interpretability
This is what we'll try to accomplish in this tutorial. We'll also be covering the following:
- Understanding tabular data using heuristic methods
- AI-assisted tools vs pre-trained models
- TableQA: an AI-assisted tool for question answering on tabular data
- Popular datasets for pre-trained models
- TAPAS
- Choosing the best solution
- Conclusion
Understanding Tabular Data using Heuristic Methods
Tabular data is data that is structured into rows and columns. Since the data can be big in size, it is not easy to manually extract the answer to a particular user query, given a condition or a set of conditions. Tabular data can also be found in relational databases.
While Structured Query Language (SQL) queries are often used to extract particular information from a database, an individual's knowledge of SQL queries may be limited. A more universal solution is to query the tabular data using natural language.
LN2SQL is one approach which used heuristic approaches to convert natural language to SQL queries. A set of parsers are used to break down the natural language construct into its respective SQL components. A thesaurus is used to improve keyword filtering to enable easier translation of specific entities like column names, SQL keywords, etc. The SQL output would then be queried to fetch results.
AI-assisted tools vs Pre-trained models
Neural networks help to understand tabular data in multiple ways. A pre-trained model, for example, can predict the pattern that connects the complex structure of a natural language query with tabular data by embedding them and passing through the neural network model.
Other solutions are not pre-trained on datasets containing tabular information but use AI and some heuristics to arrive at the solution. These are known as AI-assisted tools. We will take a look at such a tool below.
TableQA: an AI-assisted tool for question answering on tabular data
As we saw earlier, one method for breaking down natural language into smaller components is converting them into SQL queries. A SQL query is built from several component statements which include conditions, aggregate operations, etc.
TableQA converts natural language queries to SQL queries in such a manner. Let's see a demo on how to use this tool for querying cancer death data obtained from the Abu Dhabi open platform.
First, install the package and requirements. Install the module via pip:
!pip install tableqa
Next, we'll access the sample data from the repository.
!git clone https://github.com/abhijithneilabraham/tableQA/
%cd tableQA/tableqa/And now we'll take our first look at the data.
import pandas as pd
df = pd.read_csv("cleaned_data/Cancer Death - Data.csv")
# A first look at data
df.head()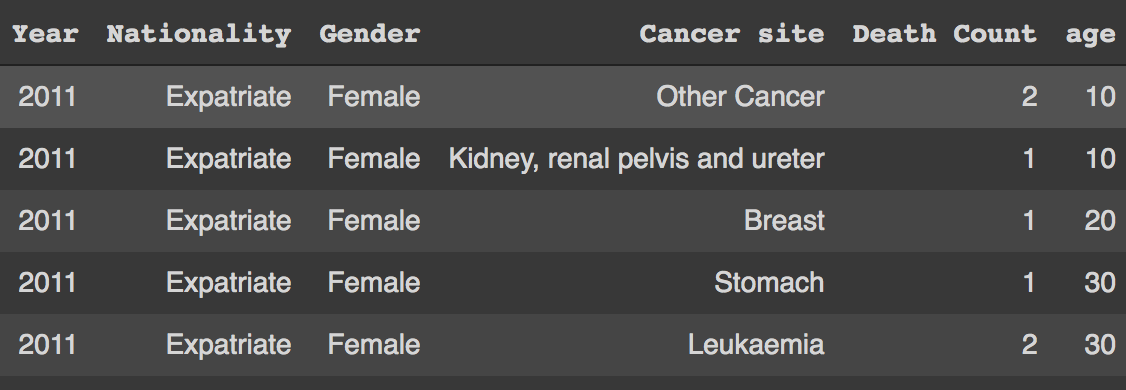
You can see the file we are trying to query is a CSV (comma separated values) file with columns like Year, Nationality, Gender, Cancer Site, Death Count, and age. Let's try to answer some questions from this dataset.
from tableqa.agent import Agent
agent = Agent(df)
#Ask a question
agent.query_db("how many deaths of age below 40 had stomach cancer?")>>> [(24,)]
We could also take a look at the associated SQL query related to the same.
agent.get_query("how many deaths of age below 40 had stomach cancer?")
>>> SELECT COUNT(death_count) FROM dataframe WHERE age < 40 AND cancer_site = "Stomach"
As you can see here, there is a COUNT operation done on the column Death Count with conditions like age<40 and Cancer Site="Stomach".
TableQA uses a combination of deep learning-enabled entity extractor and aggregate clause classifier to build the SQL query. The entity extractor matches the conditions by mapping the columns with their respective values if there are any in the question. It uses a pre-trained question answering model trained on SQUAD to help easily locate the column's value from the input question.
The aggregate clause classifier is a two-layer deep learning model which helps in classifying the nature of the input question in any of the following:
- SELECT
- COUNT
- MAXIMUM
- MINIMUM
- AVERAGE
- SUM
Combining the entity extraction and clause classification with the help of some heuristics will generate a SQL query which is then used to query the data. One possible advantage of this approach is that there is no re-training necessary for adding any new feature – some custom fixes could be done by modifying the code, replacing the AI models inside with more accurate ones, etc.
Popular Datasets for Pre-trained models
The solutions which used heuristics have their own limitations. The increase in question complexity is not easy to tackle with explicit programming.
For example, we need to be able to answer questions that require multiple steps which are non-trivial, like: "Who finished first in this year's F1 championship?" or "What is the cheapest mode of transport that departs tomorrow morning?"
A model pre-trained with a dataset containing such questions can be used in such cases where a human-like inference is required.
The WikiTableQuestions (WTQ) is a dataset that consists of complex questions along with a table from Wikipedia. The dataset contains 2108 tables from a large variety of topics (to cover more domain knowledge) and 22033 questions with different complexity.
Microsoft has made available a Sequential Question Answering dataset, also known as SQA. The task of answering sequences of questions are done on HTML tables. SQA was created by decomposing 2,022 questions from WikiTableQuestions (WTQ). Each WTQ question is decomposed into three, resulting in a dataset of 6,066 sequences that contain 17,553 questions in total. Each of the questions was also associated with answers in the form of cell locations in the tables.
Another popular dataset for this task is WikiSQL, a dataset of 80654 human-annotated pairs of questions and SQL queries distributed across 24241 tables from Wikipedia. Unlike other datasets above, WikiSQL contains SQL queries mapped from questions with annotated components.
Bring this project to life
TAPAS: Weakly Supervised Table Parsing via Pre-training
In 2020, Google Research open-sourced a popular deep learning model for querying tabular data without generating logical forms called TAPAS. It extends the Masked Language Modeling (MLM) approach to structured data.
Like BERT, TAPAS uses features which have to encode the tabular input. It then initializes a joint pre-training of text sequences and tables trained end to end and is successfully able to restore masked words and table cells. It can infer from a query by selecting a subset of table cells. If available, aggregate operations are also performed on top of them. Various datasets have been benchmarked using TAPAS, including WTQ, SQA, and WIKISQL.
Let's look at a sample.
First, install the requirements:
!pip install tapas-table-parsing
Copy the model files from the cloud to our machine:
!gsutil cp gs://tapas_models/2020_04_21/tapas_sqa_base.zip . && unzip tapas_sqa_base.zip
We are going to make a predict() function to input the table as a dataframe:
import tensorflow.compat.v1 as tf
import os
import shutil
import csv
import pandas as pd
import IPython
tf.get_logger().setLevel('ERROR')
from tapas.utils import tf_example_utils
from tapas.protos import interaction_pb2
from tapas.utils import number_annotation_utils
from tapas.scripts import prediction_utils
os.makedirs('results/sqa/tf_examples', exist_ok=True)
os.makedirs('results/sqa/model', exist_ok=True)
with open('results/sqa/model/checkpoint', 'w') as f:
f.write('model_checkpoint_path: "model.ckpt-0"')
for suffix in ['.data-00000-of-00001', '.index', '.meta']:
shutil.copyfile(f'tapas_sqa_base/model.ckpt{suffix}', f'results/sqa/model/model.ckpt-0{suffix}')
max_seq_length = 512
vocab_file = "tapas_sqa_base/vocab.txt"
config = tf_example_utils.ClassifierConversionConfig(
vocab_file=vocab_file,
max_seq_length=max_seq_length,
max_column_id=max_seq_length,
max_row_id=max_seq_length,
strip_column_names=False,
add_aggregation_candidates=False,
)
converter = tf_example_utils.ToClassifierTensorflowExample(config)
def convert_interactions_to_examples(tables_and_queries):
"""Calls Tapas converter to convert interaction to example."""
for idx, (table, queries) in enumerate(tables_and_queries):
interaction = interaction_pb2.Interaction()
for position, query in enumerate(queries):
question = interaction.questions.add()
question.original_text = query
question.id = f"{idx}-0_{position}"
for header in table[0]:
interaction.table.columns.add().text = header
for line in table[1:]:
row = interaction.table.rows.add()
for cell in line:
row.cells.add().text = cell
number_annotation_utils.add_numeric_values(interaction)
for i in range(len(interaction.questions)):
try:
yield converter.convert(interaction, i)
except ValueError as e:
print(f"Can't convert interaction: {interaction.id} error: {e}")
def write_tf_example(filename, examples):
with tf.io.TFRecordWriter(filename) as writer:
for example in examples:
writer.write(example.SerializeToString())
def predict(table_data, queries):
table=[list(table_data.columns)]+table_data.values.tolist()
examples = convert_interactions_to_examples([(table, queries)])
write_tf_example("results/sqa/tf_examples/test.tfrecord", examples)
write_tf_example("results/sqa/tf_examples/random-split-1-dev.tfrecord", [])
! python -m tapas.run_task_main \
--task="SQA" \
--output_dir="results" \
--noloop_predict \
--test_batch_size={len(queries)} \
--tapas_verbosity="ERROR" \
--compression_type= \
--init_checkpoint="tapas_sqa_base/model.ckpt" \
--bert_config_file="tapas_sqa_base/bert_config.json" \
--mode="predict" 2> error
results_path = "results/sqa/model/test_sequence.tsv"
all_coordinates = []
df = pd.DataFrame(table[1:], columns=table[0])
display(IPython.display.HTML(df.to_html(index=False)))
print()
with open(results_path) as csvfile:
reader = csv.DictReader(csvfile, delimiter='\t')
for row in reader:
coordinates = prediction_utils.parse_coordinates(row["answer_coordinates"])
all_coordinates.append(coordinates)
answers = ', '.join([table[row + 1][col] for row, col in coordinates])
position = int(row['position'])
print(">", queries[position])
print(answers)
return all_coordinates
Now let's use a sample table and load it as a dataframe. It consists of columns containing actor names and the number of movies they played in.
data = {'Actors': ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], 'Number of movies': ["87", "53", "69"]}
queries = ["Who played less than 60 movies", "How many movies has George Clooney played in?"]
table = pd.DataFrame.from_dict(data)
result = predict(table, queries)The model inference from the table can be seen below:
> Who played less than 60 movies
Leonardo Di Caprio
> How many movies has George Clooney played in?
69However, there are certain limitations while using TAPAS. It handles single tables as context, which are able to fit in memory. This makes it unsuitable for large datasets or multiple databases. Also, questions in need of multiple aggregate operations are not possible, such as: "how many actors have average movies higher than 10?"
Choosing the best solution
A good solution to this task depends on various factors and user preferences.
Non-deep-learning solutions that use heuristics are the fastest, but they come with a cost of poor semantic understanding.
A deep learning model like TAPAS can help with complex semantic understanding of a natural language question and the table structure, however it comes with concerns over memory issues and expensive compute requirements.
An AI-assisted solution like TableQA has an advantage in the usage of heuristics, since the heuristics can be modified in order to improve performance on the solution in most cases without having to re-train the deep learning model. But as the natural language gets more complex, more errors occur in the retrieval of information from the table.
Conclusion
In this article, we went through various solutions for question-answering on tabular data. We also saw different solutions which use heuristics and deep learning to semantically parse the information combined from tabular data and the natural language question. Choosing the best solution is done by considering various factors: speed, performance on understanding natural language, and memory.