
Google’s Tensor Procesing Unit (TPU) has been making a splash in the ML/AI community for a lot of good reasons.
Currently, training deep learning models takes an enormous amount of computing power (and a lot of energy). There is no question that NVIDIA has been the gold standard for training deep learning models with most frameworks built on top of CUDA. The release of the new TPUv2 has started shifting the conversation.
Over the last year or so we have seen a lot of new developments in the AI chip space. Companies like Intel, Graphcore, Cerebras, Vathys, and more have been racing to develop newer hardware architectures that promise to take the general compute model of a GPU and build it specifically for the task of training and deploying deep learning models.
Over the last few weeks we have been working to integrate the new TPUv2 into our suite of Machine learning and AI tools called Gradient°. Along the way we have learned a lot about this new hardware, and more importantly, what the future of hardware for Machine Learning looks like. Let’s dive in.
TPU Overview
The TPU is the first of these new chips to become publicly available and we are just starting to see the real-world performance benchmarks. The team at RiseML recently published a benchmark comparing the TPU to the NVIDIA P100 and V100 chipsets and the first results are exciting to say the least.
The TPUv2 differs from a traditional GPU in a few ways. Each chip actually combines 4 TPU chips each with 16GB of high-performance memory. The TPUv2 is capable of addressing up to 2,400GB/s memory bandwidth and like a GPU, it is designed to be connected to multiple TPU nodes for even faster parallel compute.
That said, there are a few key limitations worth noting:
- the TPU only works with TensorFlow currently, although there is work going on to support PyTorch.
- the TPU is expensive. The node itself $6.50/hr and you also need a compute node to attach it to so realistically you are looking at $+7.00/hr to use a TPU. That said, with great performance it might actually be more cost effective compared to alternative GPU options on a normalized price/performance scale.
- It’s not fully publicly available yet. This could change quickly, but as it stands you still need to apply to be a part of the Beta program to gain access to a TPU.
TPU Storage Model
There are some key differences in how machine learning tasks use storage when running on a GPU verses a TPU. For traditional GPU-backed training a GPU has to rely on a host process running on the CPU to pull data from a local filesystem or other storage source into the CPU’s memory, and transfer that memory to the GPU for further processing.
We rely on nvidia-docker containers to manage hardware dependencies and provide local storage access for GPUs. Additionally, underlying each Gradient GPU job is a shared persistent data store that is automatically mounted to /storage, which can also be used as the main storage source for from the GPU-based training.
In deep learning tasks IO can quickly become a bottleneck and we have heavily optimized the Gradient storage architecture to be able to fully saturate a GPU training job with multiple tasks hitting a single data source.
The TPU storage access is quite different than a GPU. TPUs currently leverage the Distributed Tensorflow framework to pull and push dataflows for training sessions. This framework supports several different file system plugins, but Google has chosen Google Cloud Storage as the only supported TPU storage model currently.
On a TPU it is considered sub-optimal to run any code on the “compute node” — ideally you get as much of your TensorFlow code as possible compiled to executable units using the XLA (accelerated linear algebra) architecture. This requires a slight rework of most existing code to use TPU-specific versions of some of the core Tensorflow algorithms. In turn, these TPU-specific routines require use of data sources and sinks in Google Cloud Storage to operate.
For Gradient access to TPUs we automatically provide a block of Google cloud storage automatically to your machine learning jobs. In a TPU tensorflow job the input dataflow location is typically referred to as the dataflow_dir and the output location is the model_dir. At the completion of the training job the TPU outputs are automatically loaded into a web-accessible artifacts directory for download and browsing.
TPUs as Network Devices
Another major difference between TPUs and GPUs is that TPUs are provided as network addressable devices, as opposed GPUs which are typically locally attached hardware devices on a PCI bus. TPUs listen on an IP address and port for XLA instructions and operations to perform.
In Google’s current TPU deployment model these network devices reside in a Google-defined TPU project and network separate from your personal or corporate Google cloud resources. The TPU projects and networks are specific to your account, but you do not have direct access to them through Google’s console or APIs.
To make use of a TPU in this separate environment you must first establish various trust relationships between your network resources and the Google managed TPU project and network, including setting up VM instances with specific service account roles, and granting TPU access to Google cloud storage buckets. Gradient’s job runner simplifies this by managing all of these relationships automatically, thus obviating the need to do a lot of complex manual setup and configuration.
TPU Name Resolution
TPUs also have human readable names in Google’s cloud, similar to DNS names. Google provides a basic name resolution library for translating a TPU name into a network address and port (actually a TPU gRPC URL i.e. grpc://${TPU_IP}:8470), so that your code does not have to hard-code this information.
There is a version of the library included with TensorFlow 1.6, but we have already seen some breaking changes to it appear in TensorFlow 1.7. We’ve also found that the TPU name resolution library requires higher levels of permissions in order to access required Google Cloud APIs and function correctly.
As we have been working to integrate the TPU in to Gradient, we have attempted to smooth over these issues by pre-resolving the TPU names and providing a usable TPU_GRPC_URL as an environment variable within the TensorFlow container. Gradient also provides some supplemental docker images that have the required TPU name resolution dependencies pre-installed for users who want to exercise those capabilities.
Running code on a TPU
The TPU is weird in the sense that it requires a slight change in how you think about traditional deep learning tasks. Currently the TPU only supports TensorFlow code, and there are a few requirements for porting existing code to the new architecture.
At a high level, the TPU docs recommend using the new TPUEstimator class which abstracts away some of the implementation details of running on a TPU. For most TensorFlow developers, this is a well-known best practice.
my_tpu_estimator = tf.contrib.tpu.TPUEstimator(
model_fn=my_model_fn,
config=tf.contrib.tpu.RunConfig()
use_tpu=False)
You can check out more here: https://www.tensorflow.org/programmers_guide/using_tpu
Try it today
With Gradient, you can easily try out the TPU today (subject to demand and availability)!
After you have created an account at www.paperspace.com/account/signup and installed our CLI you now train a model on a TPU in the cloud.
First, clone the sample repo at https://github.com/Paperspace/tpu-test and cd tpu-test in to the new directory.
Initialize a project namespace using paperspace project init. Now with a single line of code you can submit the project to a TPU running on Gradient.
paperspace jobs create --machineType TPU --container gcr.io/tensorflow/tensorflow:1.6.0 --command “python main.py”
If you go to your console you will see the job and the logs that are generated:
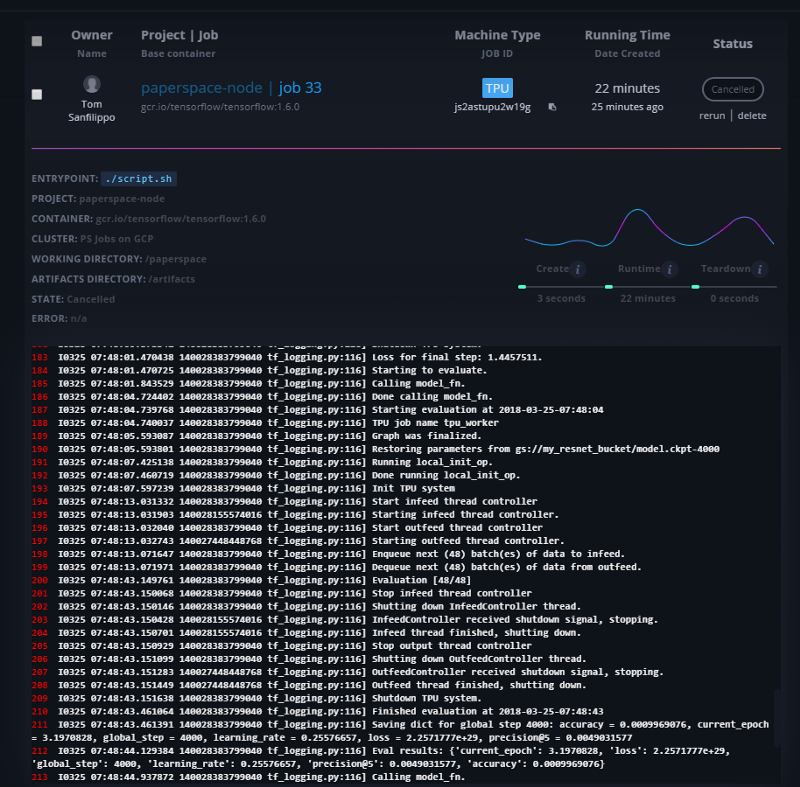
That’s it! You’ve run a TPU job. Want try a more advanced model? Checkout our repo for training Resnet-50 on a TPU
Note: The ResNet-50 example is potentially a long-running job, and can take up to 20 hours to complete.
The future of parallel compute architectures
We are entering a Golden Era of cloud machine learning. As a company focused on making production Machine Learning technology available to all developers, we are incredibly excited by the explosion of new hardware accelerators and what they might mean for the end user.
While the GPU is not going anywhere, the TPU is the first real competitor and it points to a future where a developers will have their choice of hardware and software.
top image artist: Julie Mehretu









