
Intro
Building machine learning models can be a simple process when we have the right data to train our models. An example would be a situation where we need to train a model to be able to predict if some customer will churn. If we had a sufficiently well made dataset, all we would have to do is plug that data into a model, with a simple library like Brains.js or TensorFlow, and add a back-propagation algorithm to optimize our model. With that, we would have a model that is able to take our input data and return an optimized prediction for whether or not a customer would stop buying a product.
But what if we don't have good data, and gathering data is beyond our capabilities? We have to define our targets goal, or what we think an optimal answer would be, and thats where algorithms like genetic algorithms and reinforcement learning come into play. In these paradigms, we are able to define a goal, and our model interacts with the environment it is in to learn from its pervious experiences until it is able to solve its defined task.
Series Recap
So far, we have gone through the basics of the genetic algorithm, its components, and the concepts behind its functioning that enable it to find optimal solutions to simple and hard problems. We did so by using one to guess a phrase by comparing how many letters it got correct, and using those instances closest to being correct to create children instances or offsprings that carry information about our problem space into the next generation. You can check out that tutorial here. In the second article, we were able to use our learnings from the previous article to optimize a deep neural network. We adapted information gotten from our previous tutorial to solve our optimization problem, to add 2 numbers passed into it, and we built our own custom neural network that was able to take advantage of our customization to manipulate the values of weights and biases, instead of doing so through an already made library like TensorFlow.
The goal of this article
For today's article, we are going to go over building the environment that our model would interact with, making changes to that environment, and reading the state of it.
Setting up our Player
We need to have a player object capable of looking at the environment and making decisions based on the state of the environment.
A Naive player
Here is the full code for the Player class we will use in this tutorial:
class Player {
constructor(id, env, play, model,player) {
this.id = id;
this.env = env;
this.play = play; ///x or O
this.model = model;
this.position = '';
this.freeIndexes = 9;
this.won = false
}
getFreeIndexes() {
const free = [];
for (let i = 0; i < this.objectGrid.length; i++) {
const row = this.objectGrid[i];
for (let j = 0; j < row.length; j++) {
const column = this.objectGrid[i][j];
if (column === '-') {
free.push(`${i}${j}`);
}
}
}
return free;
}
verticalWin() {
const starts = [0, 1, 2];
for (let i = 0; i < starts.length; i++) {
let found = 0;
for (let j = 0; j < 3; j++) {
const position = this.objectGrid[j][i];
if (position === this.play) {
found++;
}
}
if (found === 3) {
return true; //// found a row
}
}
return false;
}
horizontalWin() {
const starts = [0, 1, 2];
for (let i = 0; i < starts.length; i++) {
let found = 0;
for (let j = 0; j < 3; j++) {
const position = this.objectGrid[i][j];
if (position === this.play) {
found++;
}
}
if (found === 3) {
return true; //// found a row
}
}
return false;
}
sideWays() {
let found = 0;
for (let i = 0; i < this.objectGrid[0].length; i++) {
const position = this.objectGrid[i][i];
if (position === this.play) {
found++;
}
}
if (found === 3) {
return true; //// found a row
}
found = 0;
for (let i = 0; i < this.objectGrid[0].length; i++) {
const max = this.objectGrid[0].length;
const position = this.objectGrid[0 + i][max - i];
if (position === this.play) {
found++;
}
}
if (found === 3) {
return true; //// found a row
}
return false; //// fo
}
win() {
//checks if i won
///vertical check
///horizontal check
///sideways
console.log({ vertival: this.verticalWin() });
console.log({ horizontalWin: this.horizontalWin() });
console.log({ sideways: this.sideWays() });
if (this.verticalWin() ||this.horizontalWin() || this.sideWays()) {
return true
}
return false
}
//generate random move
move() {
const freeIndexes = this.getFreeIndexes();
this.freeIndexes = freeIndexes.length;
if (freeIndexes.length === 0) {
return this.objectGrid;
}
const think = this.think(freeIndexes);
console.log(think);
this.objectGrid[think[0]][think[1]] = this.play;
this.position = `${think[0]}${think[1]}`;
console.log('changed position to ' + this.position);
if (this.win()) {
this.won = true
}
return this.objectGrid;
}
think(freeIndexes) {
console.log({ freeIndexes });
const random = Math.floor(Math.random() * freeIndexes.length);
const chosen = freeIndexes[random];
console.log(chosen);
return [parseInt(chosen[0]), parseInt(chosen[1])];
}
}
Our naive player is able to look at the environment, view empty spaces, and randomly pick one of those spaces to draw either an X or an O on. Our naive player does not take advantage of our genetic algorithm model; it isn't able to learn how to play the game and is just choosing random empty spaces to play. We would later give our player the ability to make more educated choices after we set up our genetic algorithm.
Our player class is able to look at the board and declare if they won or not after a move by calling the win() function. Wins can be either vertical, horizontal, or adjacent in nature.
Design for our model
Designing a way of solving this problem can be a bit tricky. We need to figure out how to represent the 3 different states on our board. These 3 states are:
- A space occupied by agent
- A space occupied by an opponent
- An empty space
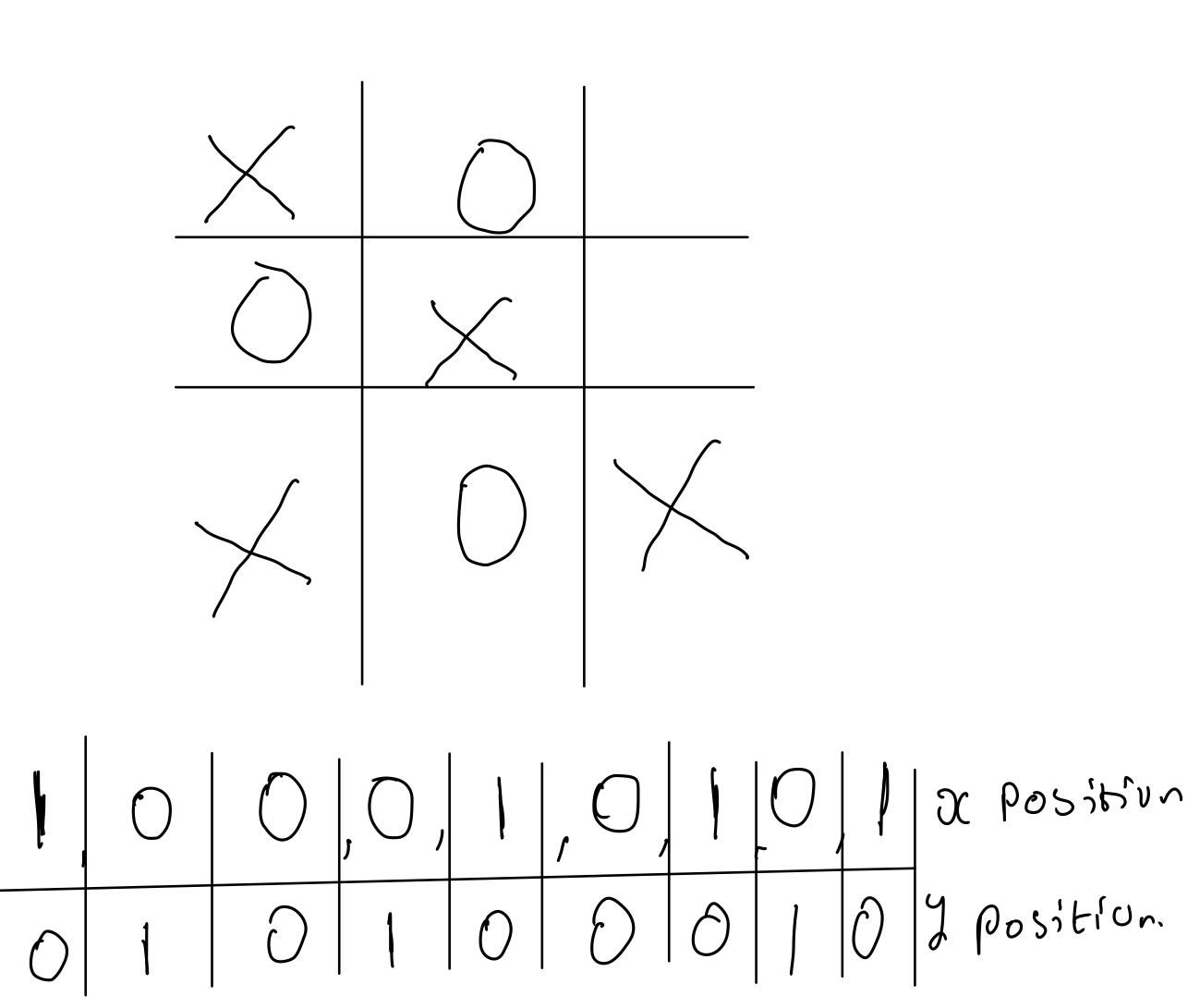
If we had 2 states, we could conveniently identify one as 1 and the other as 0. But three leaves us with two choices: represent the values in the range -1 to 1 (-1,0,1), or have an array of length 18. In the latter option, indexes 0 to 8 can mark where our agent chose, and indexes 9 to 17 can represent places occupied by our opponent. Let's try the second option for this tutorial. You can see an explanation for how this array would be formed above.
We opt to use ReLu for our hidden layers because they, as usual, outperformed sigmoid (to nobody's surprise).
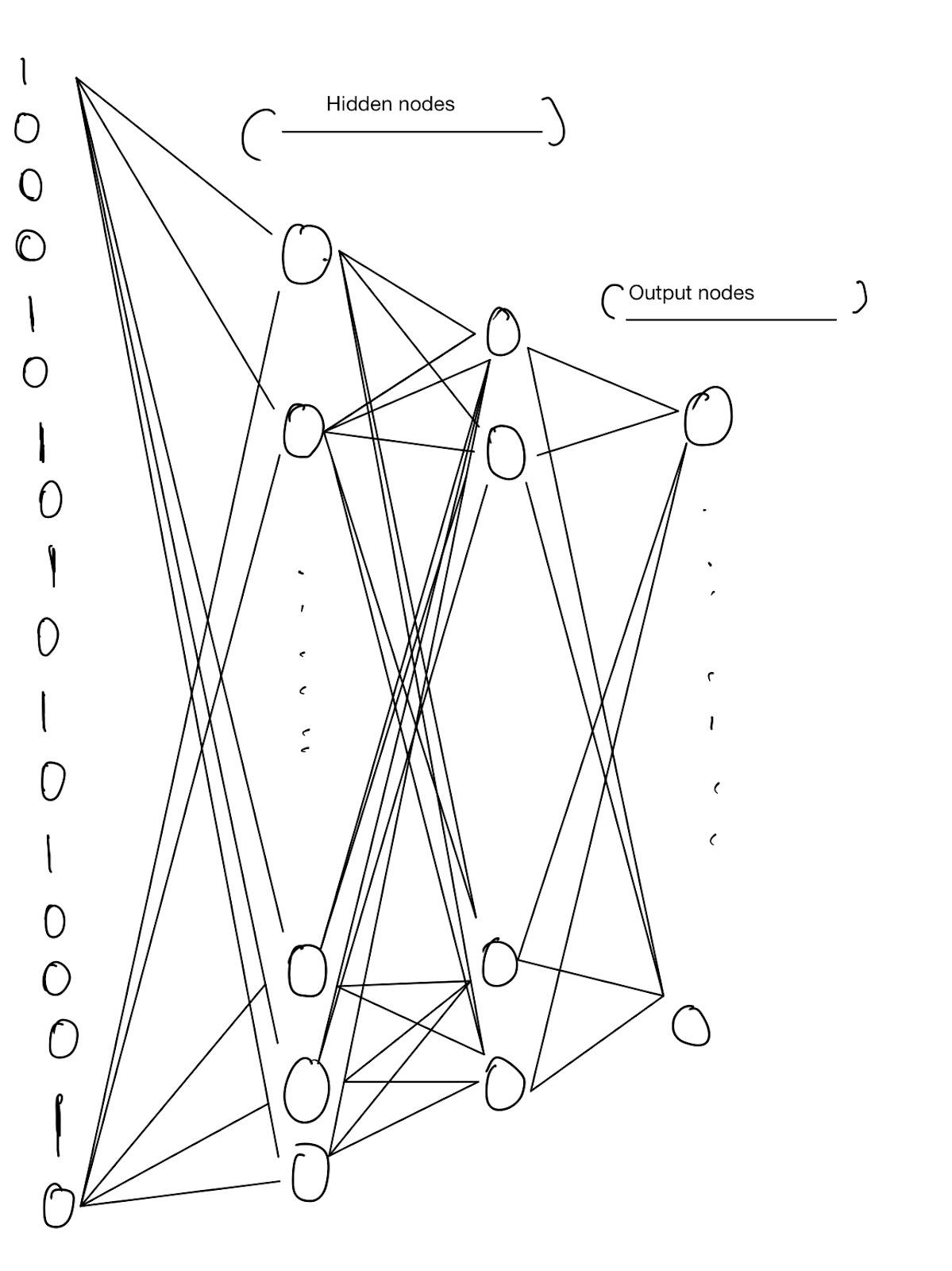
Here is a visual explanation of our model.
The new version of our genetic algorithm Code
For this article, you need to have already gone through part 1 and part 2 of this series, and ensure you understand the basics. We are going to be using the same code template, and going over changes in the codebase.
The Code
class GNN {
constructor(number,) {
this.population = []
this.genePool = []
this.numnber = number
this.mostFit = { fitness: 0 }
this.initializePopulation()
this.elittSize = parseInt(this.numnber * 0.3)
this.elites = []
this.soFar = {}
}
initializePopulation() {
for (let i = 0; i < this.numnber; i++) this.population.push({ chromosomes: this.makeIndividual(), fitness: 0 })
}
solve() {
for (var i = 0; i < 200; i++) {
this.calcFitnessAll()
this.crossParents()
this.mutate()
}
this.calcFitnessAll()
var fs = require('fs');
const sorted = this.population.sort((a, b) => a.fitness - b.fitness).reverse();///sort from smallest to biggest every time i add a new smallest
sorted.map((elit)=>{
console.log(elit.fitness)
})
const getBeestElite =sorted[0]
var data = JSON.stringify(getBeestElite);
fs.writeFile('./config.json', data, function (err) {
if (err) {
console.log('There has been an error saving your configuration data.');
console.log(err.message);
return;
}
console.log('Configuration saved successfully.')
});
}
mutate() {
this.population.forEach((object) => {
const shouldIMutateChromosome = Math.random() < 0.3
if (shouldIMutateChromosome) {
const layer = object.chromosomes
for (var j = 0; j < layer.weightsFlat.length; j++) {////going through all the layers
const shoulIMutateGene = Math.random() < 0.05
if (shoulIMutateGene) {
///mutate the item in the array
layer.weightsFlat[j] = (Math.random() * 2) - 1; //between -1 and 1
}
}
layer.reconstructWeights()
////recontruct the array
}
})
}
playAGame(player1, player2, Player1StartsFirst) {
class Env {
constructor() {
this.state = [
['-', '-', '-'],
['-', '-', '-'],
['-', '-', '-'],
];
this.id = Math.random()
}
}
///iniitialiise game environment
const env = new Env()
///iniitialise players and pass in agents
const playerX = new Player(0, env, 'X', Player1StartsFirst ? player1 : player2);
const playerO = new Player(1, env, 'O', Player1StartsFirst ? player2 : player1);
/**
*
* @returns @description this function is a reculrsive function that keeps playing until someone wins or a drraw
*/
const aSet = () => {
try {
playerX.move();
if (playerX.win()) {
return 1////player won
}
if (!playerX.getFreeIndexes().length === 0) {
///no free space means its a draw
return 1
}
playerO.move();
if (playerO.win()) {
return 0////player loss
}
if (!playerO.getFreeIndexes().length === 0) {
///no free space means its a draw
return 1
}
else {
return aSet() /////keep playing
}
} catch (error) {
return 0
}
}
return aSet() ///false means it lost the game, we consider win and draw to be acceptable criterias
}
calcFitnessAll() {
this.population.forEach((object) => {
let totalGames = 0;
let totalLoss = 0;
for (let i = 0; i < this.population.length; i++) {
///the fitness function is defined as the (totalGamesPlayed - totalGamesLoss)/totalGamesPlayed
///for each player we meet, games are started by this player and the next is started by the next player
totalGames = totalGames + 2/////we count the games in advance
totalLoss = totalLoss + (this.playAGame(object.chromosomes, this.population[i].chromosomes, false) ? 0 : 1)
totalLoss = totalLoss + (this.playAGame(object.chromosomes, this.population[i].chromosomes, true) ? 0 : 1)
}
object.fitness = (totalGames - totalLoss) / totalGames
let fit = parseInt(object.fitness * 1000)
for (let i = 0; i < fit; i++) {
this.genePool.push(object.chromosomes)
}
console.log(`total games is ${totalGames} total loss is ${totalLoss} total agents in testrun is ${this.genePool.length}`)
})
if (this.genePool.length < this.population.length) {
///sort the best
const newPopulation = this.population.sort((a, b) => a.fitness - b.fitness);///sort from smallest to biggest every time i add a new smallest
///get the best
this.genePool = this.genePool.concat(newPopulation.slice(0, newPopulation.length - this.genePool.length).map((data) => data.chromosomes))
}
const getBeestElite = this.elites[this.elites.length - 1]
///run test
console.log(`Best item so far has fittness as ${getBeestElite.fitness} id ${getBeestElite.chromosomes.id} `)
}
amIElite(object) {
const smallest = this.elites[0]
if (this.elittSize > this.elites.length) {
this.elites.push(object)///elites not yet enough
}
else if (parseInt(object.fitness) > parseInt(smallest.fitness)) {///check if am bigger than the smallest
///bigger than this guy so am going to replace him
this.elites.shift()
this.elites.push(object)
}
this.elites = this.elites.sort((a, b) => a.fitness - b.fitness);///sort from smallest to biggest every time i add a new smallest
}
crossParents() {
let newPopulation = [];
const pool = this.genePool
while (this.population.length - this.elites.length !== newPopulation.length) {
const parent1 = pool[Math.floor(Math.random() * pool.length)];
const parent2 = pool[Math.floor(Math.random() * pool.length)];
const newKid = this.makeIndividual()
const newKid2 = this.makeIndividual()
////select crossSection
const crossSection = Math.floor(Math.random() * parent1.weightsFlat.length)
////kid 1
const layerParent1 = parent1.weightsFlat.filter(() => true)
const layerParent2 = parent2.weightsFlat.filter(() => true)
const layerParent1bias = parent1.weightsFlat.filter(() => true)
const layerParent2bias = parent2.weightsFlat.filter(() => true)
const newKidWeights = layerParent1.slice(0, crossSection).concat(layerParent2.slice(crossSection, layerParent2.length))
const newKid2Weights = layerParent2.slice(0, crossSection).concat(layerParent2.slice(crossSection, layerParent1.length))
newKid.weightsFlat = newKidWeights
newKid.reconstructWeights()
newKid2.weightsFlat = newKid2Weights
newKid2.reconstructWeights()
const crossSectionBias = Math.floor(Math.random() * layerParent2bias.length)
const newKidBias = layerParent1bias.slice(0, crossSectionBias).concat(layerParent2bias.slice(crossSectionBias, layerParent2bias.length))
const newKidBias2 = layerParent2bias.slice(0, crossSectionBias).concat(layerParent1bias.slice(crossSectionBias, layerParent2bias.length))
newKid.biasFlat = newKidBias
newKid.reconstructBias()
newKid2.biasFlat = newKidBias2
newKid2.reconstructBias()
newPopulation.push({ chromosomes: newKid, fitness: 0 })
newPopulation.push({ chromosomes: newKid2, fitness: 0 })
}
const sorted = this.population.sort((a, b) => a.fitness - b.fitness).reverse();///sort from smallest to biggest every time i add a new smallest
newPopulation = newPopulation.concat(sorted.slice(0,parseInt(this.population.length * 0.3)))///making sure we pass on elites
this.population = newPopulation
this.genePool = []///clear genepool
}
makeIndividual() {
return new NeuralNetwork([18, 15, 15, 9]);
}
}
Now that we've looked at the code, let's go through the functions and see what is new in our codebase.
Fitness function
Our Fitness function for making an agent learn to play is very simple. Our objective is to reduce the number of times we lose. If this was gradient descent, our cost function would be an equation that tells us how many times we lose or how many times an agent loses a game. Knowing this we can derive our fitness function to be the ratio between total games played and total games not lost
(totalGames - totalGamesLost)/totalGames
We consider both draws and wins as equally desirable outcomes for now, and try to optimize for either of them as this optimizes for the lowest loss.
To see how to fit our agent, we need to actually test it against an opponent, and there is no better opponent than other agents we create. Each agent competes with its siblings, and plays both as the first player and the second player. We do this because a tic tac toe game players can either be first or second to make a move in a game.
PlayAGame Function
This function takes in 2 players and is able to simulate the entire gameplay for our agent and its opponent. We do this to see if our agent is better than his opponent. We are keener in preventing our agent from loosing so a draw is okay, but we could optimize for a win by giving wins 1 and draws half(0.5) (Try this out after you finish this tutorial to see how well it works!).
How do we make the agent not play in an occupied box?
An intuition we want to give our agent is one where it knows it cant play a box already occupied by it or its opponent. To train out this behavior, we just flat out declare the game as failed when they make such a move.
try {
`````
playerX.move();
`````
} catch (error) {
return 0
}
Where the move function is able to check to see if our choice to play is occupied or not, this automatically returns a zero (we basically discourage that too).
Completing our player Agent
We need to make some changes to our Player class. Currently, it doesn't think before it plays, it just selects a random space that is available and marks that location. This is not intuitive and imparts no strategy for winning. we need to make our player take advantage of the Model we pass into it. Take a look at the code below.
//generate random move
move() {
const freeIndexes = this.getFreeIndexes();
this.freeIndexes = freeIndexes.length;
if (freeIndexes.length === 0) {
return this.env.state;
}
const think = this.think();
const maxOfArrray = think.max()
const dic = [[0, 0], [0, 1], [0, 2], [1, 0], [1, 1], [1, 2], [2, 0], [2, 1], [2, 2]]
const loc = dic[maxOfArrray]
if (this.env.state[loc[0]][loc[1]] !== '-') {
///checks if this agent is trying to play a position thats already played
throw new Error('Some one home Already')
}
this.env.state[loc[0]][loc[1]] = this.play;
if (this.win()) {
this.won = true
}
}
think() {
///get state of the env
const state = this.env.state
///flatten array
const flat = state.flat();
///encoding data to enter the neuralNet
const opponnet = this.play === 'X' ? 'O' : 'X'
const firstHalf = flat.flat().join().replaceAll('-', '0').replaceAll(this.play, 1).replaceAll(opponnet, 0).split(',')
const secondHalf = flat.flat().join().replaceAll('-', '0').replaceAll(opponnet, 1).replaceAll(this.play, 0).split(',')
///now we have two separate arrays showing us what boxes we occupy on the first half and the opponent boxes on the second half
const together = firstHalf.concat(secondHalf).map((number) => {
return parseInt(number)///format data to b integer again
})
// console.log({ player: this.play, together })
// console.log(together)
///pass data to neurral net
const prrediction = this.model.predict(together)
// console.log({
// prrediction
// })
return prrediction
}
Think function
Our think function is able to take advantage of our model by taking the state of the environment and creating a single [1 * 18 ] Matrix which we pass into the machine learning model and generates an output (Note: our model uses a softmax activation function; we select the max value as our position to mark by the player).
Move Function
Movement is gotten from the think function. The answer is mapped to a location on the game by think, and the move function can place the player's mark on that location thereby occupying it.
Running our code
To run the code, all we need to do is call the solve function, and you can do so by following the code below:
const gnn = new GNN(100)
gnn.solve()We tested the codebase with different populations sizes between 100, 200, and 1000, and found the code trains more efficiently with a population size of 100. It optimizes pretty quickly, and we were able to get a top fitness function of 84%. That isn't bad, but it means that our best model only won 84 percent of its games.
Here is an example output:
total games is 400 total loss is 65 total agents in testrun is 96937
total games is 400 total loss is 206 total agents in testrun is 97422
total games is 400 total loss is 66 total agents in testrun is 98257
total games is 400 total loss is 65 total agents in testrun is 99094
total games is 400 total loss is 67 total agents in testrun is 99926
total games is 400 total loss is 100 total agents in testrun is 100676
total games is 400 total loss is 65 total agents in testrun is 101513
total games is 400 total loss is 230 total agents in testrun is 101938
total games is 400 total loss is 66 total agents in testrun is 102773
total games is 400 total loss is 65 total agents in testrun is 103610
total games is 400 total loss is 66 total agents in testrun is 104445
total games is 400 total loss is 66 total agents in testrun is 105280
total games is 400 total loss is 66 total agents in testrun is 106115
total games is 400 total loss is 66 total agents in testrun is 106950
total games is 400 total loss is 78 total agents in testrun is 107755
total games is 400 total loss is 234 total agents in testrun is 108170
total games is 400 total loss is 66 total agents in testrun is 109005
total games is 400 total loss is 276 total agents in testrun is 109315
total games is 400 total loss is 66 total agents in testrun is 110150
total games is 400 total loss is 97 total agents in testrun is 110907
total games is 400 total loss is 81 total agents in testrun is 111704
total games is 400 total loss is 66 total agents in testrun is 112539
total games is 400 total loss is 67 total agents in testrun is 113371
total games is 400 total loss is 66 total agents in testrun is 114206
total games is 400 total loss is 67 total agents in testrun is 115038
total games is 400 total loss is 66 total agents in testrun is 115873
total games is 400 total loss is 66 total agents in testrun is 116708
total games is 400 total loss is 65 total agents in testrun is 117545
total games is 400 total loss is 232 total agents in testrun is 117965
total games is 400 total loss is 400 total agents in testrun is 117965
total games is 400 total loss is 234 total agents in testrun is 118380
total games is 400 total loss is 245 total agents in testrun is 118767
total games is 400 total loss is 66 total agents in testrun is 119602
total games is 400 total loss is 79 total agents in testrun is 120404
total games is 400 total loss is 400 total agents in testrun is 120404
total games is 400 total loss is 66 total agents in testrun is 121239
total games is 400 total loss is 66 total agents in testrun is 122074
total games is 400 total loss is 66 total agents in testrun is 122909
total games is 400 total loss is 66 total agents in testrun is 123744
total games is 400 total loss is 66 total agents in testrun is 124579
total games is 400 total loss is 67 total agents in testrun is 125411
total games is 400 total loss is 67 total agents in testrun is 126243
total games is 400 total loss is 66 total agents in testrun is 127078
total games is 400 total loss is 67 total agents in testrun is 127910
total games is 400 total loss is 66 total agents in testrun is 128745
total games is 400 total loss is 400 total agents in testrun is 128745
total games is 400 total loss is 67 total agents in testrun is 129577
total games is 400 total loss is 67 total agents in testrun is 130409
total games is 400 total loss is 65 total agents in testrun is 131246
total games is 400 total loss is 67 total agents in testrun is 132078
total games is 400 total loss is 234 total agents in testrun is 132493
total games is 400 total loss is 72 total agents in testrun is 133313
total games is 400 total loss is 66 total agents in testrun is 134148
total games is 400 total loss is 67 total agents in testrun is 134980
total games is 400 total loss is 66 total agents in testrun is 135815
total games is 400 total loss is 91 total agents in testrun is 136587
The best item so far has fitness of 0.8425 id 0.6559877604817235 Conclusion
Following along this tutorial series, we were able to create a machine learning model that optimizes the values of its weights with a genetic algorithm. We started with building understanding about how genetic algorithms work by creating a phrase that matches a known phrase. By doing this we were able to understand how genetic algorithms find answers to problems. In the part 2, we were able to update the weights of a neural network. For this tutorial, we finally applied all our knowledge, and built a model to solve our tic tac toe problem using neural networks and genetic algorithms. We can apply this method in different problem spaces from chess to wall breaker to predicting stock prices.











