
Attention mechanisms have become a household name in the domain of Computer Vision. The incorporation of a tailored or generalized attention mechanism has become imperative for making a recipe for success for the task at hand, be it generative modeling, image classification, object detection, or any downstream vision task.
Recent novel designs of attention mechanisms have been based on the fundamental Squeeze-and-Excitation Module. These include Global Context Networks, Convolutional Block Attention Module, Bottleneck Attention Module, Efficient Channel Attention, and many more.
In this article, we will cover a new structural form of the channel and spatial attention inspired primarily from CBAM, known as Triplet Attention (accepted at WACV 2021). We will first do a quick overview of the channel and spatial attention of CBAM, before discussing the fundamental intuition behind Triplet Attention. Further, we will take a look at the results presented in the paper and provide the PyTorch code for the module, before rounding off our discussion by touching on some shortcomings.
Table of Contents
- Abstract Overview
- Channel and Spatial Attention
- SENet
- CBAM
- Drawbacks to Current Attention Mechanisms
- Cross-Dimension Interaction
- Triplet Attention
- PyTorch Code
- Results
- ImageNet Classification
- Object Detection on MS-COCO
- GradCAM
- Shortcomings
- References
Abstract Overview
Our triplet attention module aims to capture cross-dimension interaction and thus is able to provide significant performance gains at a justified negligible computational overhead, as compared to the above described methods, where none of them account for cross-dimension interaction while allowing some form of dimensionality reduction which is unnecessary to capture cross-channel interaction.
Channel and Spatial Attention
Note: It's highly advisable to go through the other posts in my Computer Vision Attention Mechanism Series to have a good foundation for this topic. Link here.

Attention mechanisms are a simple yet intuitive idea derived from human visual perception. The fundamental idea behind representation learning is that of finding or extracting discriminative features from an input that would differentiate a particular object from an object of a different type or class. At a human visual perception level, this can be correlated to humans determining features that uniquely describe a particular object. For instance, the eyes, nose, lips, and ears are the descriptive features that indicate the subject in focus is a human face.
In the deep neural networks used in computer vision, attention mechanisms often involve channel or spatial attention (or both). In a nutshell, channel attention is essentially used to weigh each feature map/channel in the tensor, while spatial attention provides context at each feature map level by weighing each pixel in a singular feature map. Let's take a look at two prominent examples of such forms of attention mechanisms.
SENet
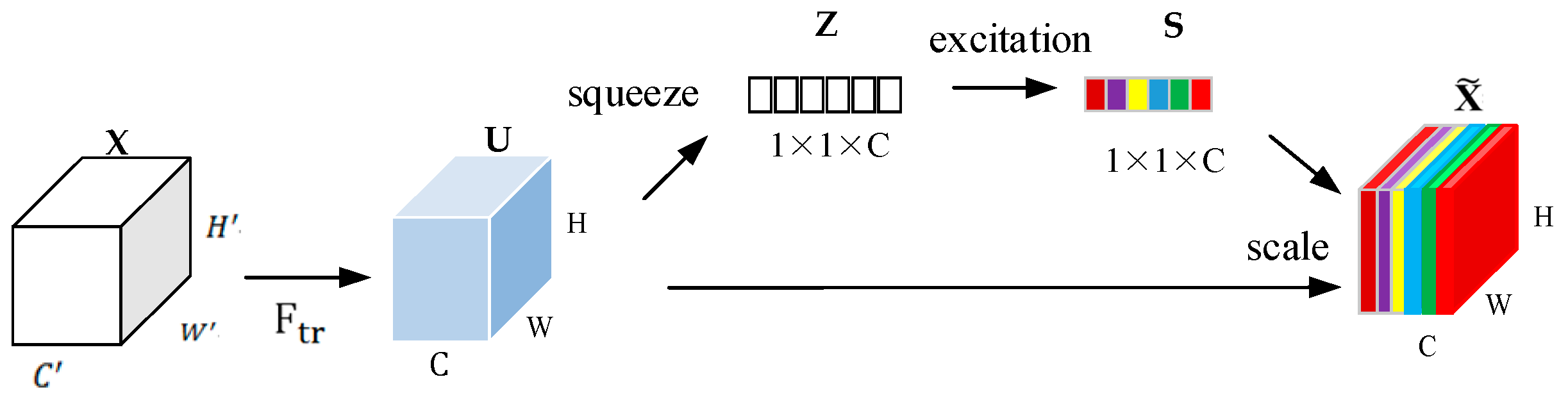
Squeeze and Excitation Networks (SENets) have a channel attention mechanism that is essentially made up of three components: a Squeeze Block, an Excitation Block, and a Scaling Block.
The Squeeze Block is responsible for reducing the input feature maps $(C \times H \times W)$ to single pixels using Global Average Pool (GAP), while keeping the number of channels the same $(C \times 1 \times 1)$. The squeezed tensor is then passed to the Excitation block, which is a multi-layer perceptron (MLP) bottleneck responsible for learning the channel attention weights. Finally, these singular weights are passed through a sigmoid activation and then are element-wise multiplied to their corresponding channels in the non-modulated input tensor.
CBAM
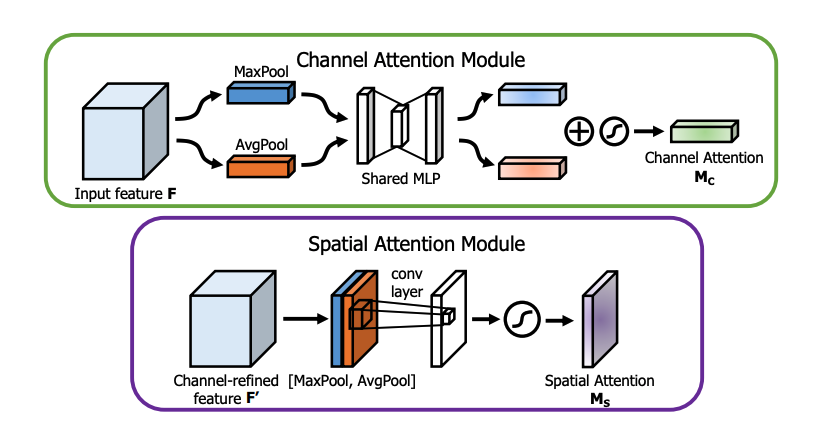
Convolutional Block Attention Module (CBAM) takes inspiration from SENet and SCA-CNN to propose a novel and efficient attention mechanism that combines the idea of both channel and spatial attention consecutively (in that order). The channel attention module in CBAM is identical to that of SENet. The only caveat is that instead of just decomposing the input tensor by GAP, it also does the same by GMP (Global Max Pooling) and aggregates both of them before passing through the shared MLP bottleneck. Similarly, in the spatial attention module, it decomposes the input tensor into two channels, which are the max-pooled and average-pooled feature representations of all the feature maps. This two-channel tensor is passed through a convolutional layer which reduces it to a single channel. Thus, this single-channel tensor is passed through sigmoid activation before being element-wise multiplied with every channel of the output tensor from the channel attention module.
Drawbacks to Current Attention Mechanisms
Although these attention mechanisms have showcased incredible performance jumps, they are not without their flaws. These include (but are not limited to) the following:
- Dimensionality Reduction - Most channel attention mechanisms involve an MLP bottleneck-like structure which is used to control the parametric complexity of the structure, but in return also causes significant information loss.
- Absence of Spatial Attention - Many novel attention mechanisms proposed to overlook the need and advantages of having a spatial attention mechanism and are only equipped with a channel attention mechanism, thus reducing the overall efficacy and expressivity of the whole attention mechanism.
- Disjoint Between Spatial and Channel Attention - Often, attention mechanisms employing a dedicated spatial attention module and channel attention module keep them separated and disjoint, thus not allowing interaction between the two modules, which is not optimal.
- Absence of Cross-Channel Interaction - Many attention mechanisms don't emphasize allowing channels to interact with other channels while computing attention weights, thus decreasing information propagation.
- Efficiency - Most attention mechanisms add substantial extra computation in the form of model parameters and FLOPs, resulting in larger and slower architectures.
Cross-Dimension Interaction
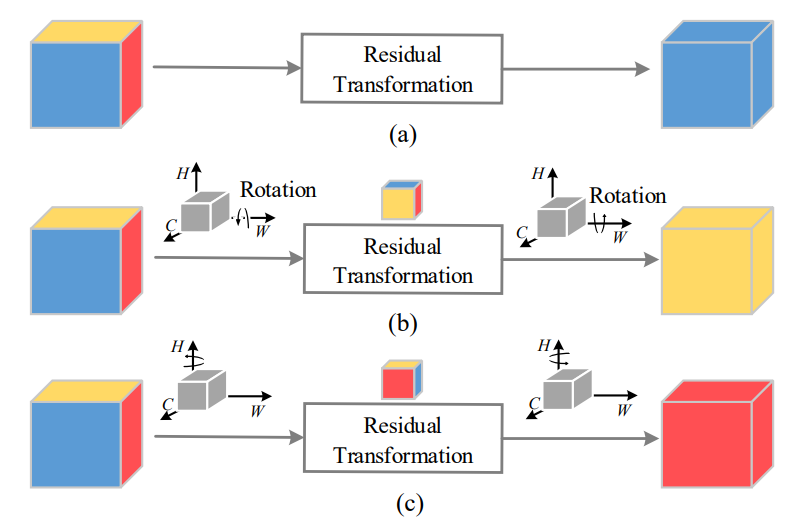
In an attempt to address the above-mentioned drawbacks, Triplet Attention proposes a novel and intuitive way of computing attention weights called Cross-Dimension Interaction. Cross-Dimension Interaction is a simple idea involving allowing the module to compute attention weights for each of the dimensions against every other dimension, i.e., $C \times W$, $C \times H$, and $H \times W$. This essentially allows it to compute both spatial and channel attention in a singular module. Cross-Dimension Interaction is achieved by simply permuting the input tensor dimension, which is followed by a simple residual transform that generates the attention weights. This thus allows the attention mechanism to form a strong dependency on each of the dimensions in the input tensor, which in turn is crucial for providing tighter bounds over the region of attention on the feature maps. Let's understand how Triplet Attention achieves Cross-Dimension Interaction.
Triplet Attention
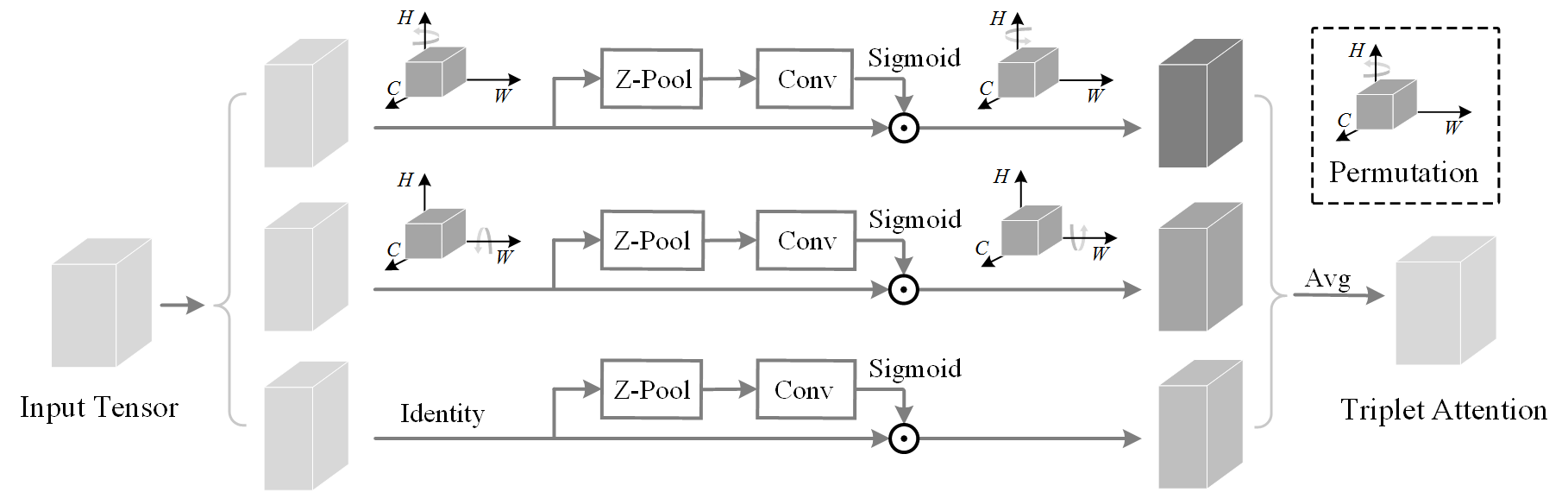
As the name suggests, Triplet Attention is a three-branch structure, where each branch is responsible for computing and applying the attention weights across two of the three dimensions of the input tensor. The top two branches compute the channel attention weights against each of the two spatial dimensions, while the bottom branch is responsible for computing simple spatial attention identical to that present in CBAM.
In the top two branches, the input tensor is first rotated to change the dimensions, after which it undergoes the Zeroth Pool (Z-Pool) operator which essentially reduces the zeroth dimension to two by concatenating the average-pooled and max-pooled features of the tensor across that dimension. This resulting tensor is further passed through a single spatial convolution layer, which reduces the zeroth dimension further to one, after which point this output is passed through sigmoid activation. The final output is then element-wise multiplied with the permuted input, and then subsequently rotated back to the original dimensions (the same as that of the input). After this is done for all three branches, the three resulting tensors are aggregated by simple averaging, which forms the output of Triplet Attention.
Thus, Triplet Attention incorporates Cross-Dimension Interaction which removes the information bottleneck and dimensionality reduction prevalent in most attention mechanism structures. Subsequently, since the Triplet Attention mechanism doesn't incorporate MLP structures but rather three convolutional layers, the parametric complexity of this module is extremely cheap as showcased in the following table.
| Attention Mechanism | Parameters | Overhead (ResNet-50) |
|---|---|---|
| SE | 2C2/r | 2.514M |
| CBAM | 2C2/r + 2k2 | 2.532M |
| BAM | C/r(3C + 2k2C/r + 1) | 0.358M |
| GC | 2C2/r + C | 2.548M |
| Triplet Attention | 6k2 | 0.0048M |
PyTorch Code
import torch
import math
import torch.nn as nn
import torch.nn.functional as F
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ZPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
class AttentionGate(nn.Module):
def __init__(self):
super(AttentionGate, self).__init__()
kernel_size = 7
self.compress = ZPool()
self.conv = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.conv(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, no_spatial=False):
super(TripletAttention, self).__init__()
self.cw = AttentionGate()
self.hc = AttentionGate()
self.no_spatial=no_spatial
if not no_spatial:
self.hw = AttentionGate()
def forward(self, x):
x_perm1 = x.permute(0,2,1,3).contiguous()
x_out1 = self.cw(x_perm1)
x_out11 = x_out1.permute(0,2,1,3).contiguous()
x_perm2 = x.permute(0,3,2,1).contiguous()
x_out2 = self.hc(x_perm2)
x_out21 = x_out2.permute(0,3,2,1).contiguous()
if not self.no_spatial:
x_out = self.hw(x)
x_out = 1/3 * (x_out + x_out11 + x_out21)
else:
x_out = 1/2 * (x_out11 + x_out21)
return x_outResults
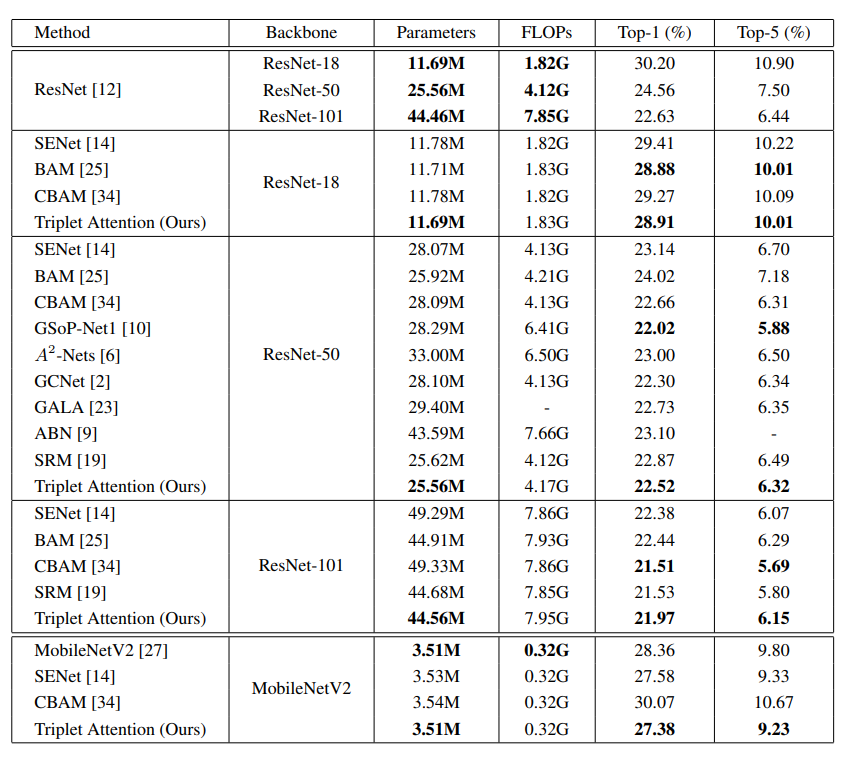
ImageNet Classification
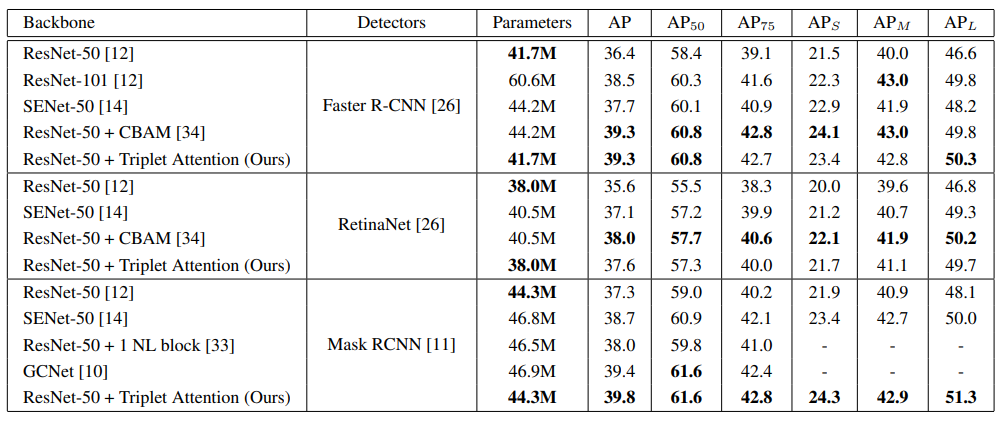
Object Detection on MS-COCO
GradCAM
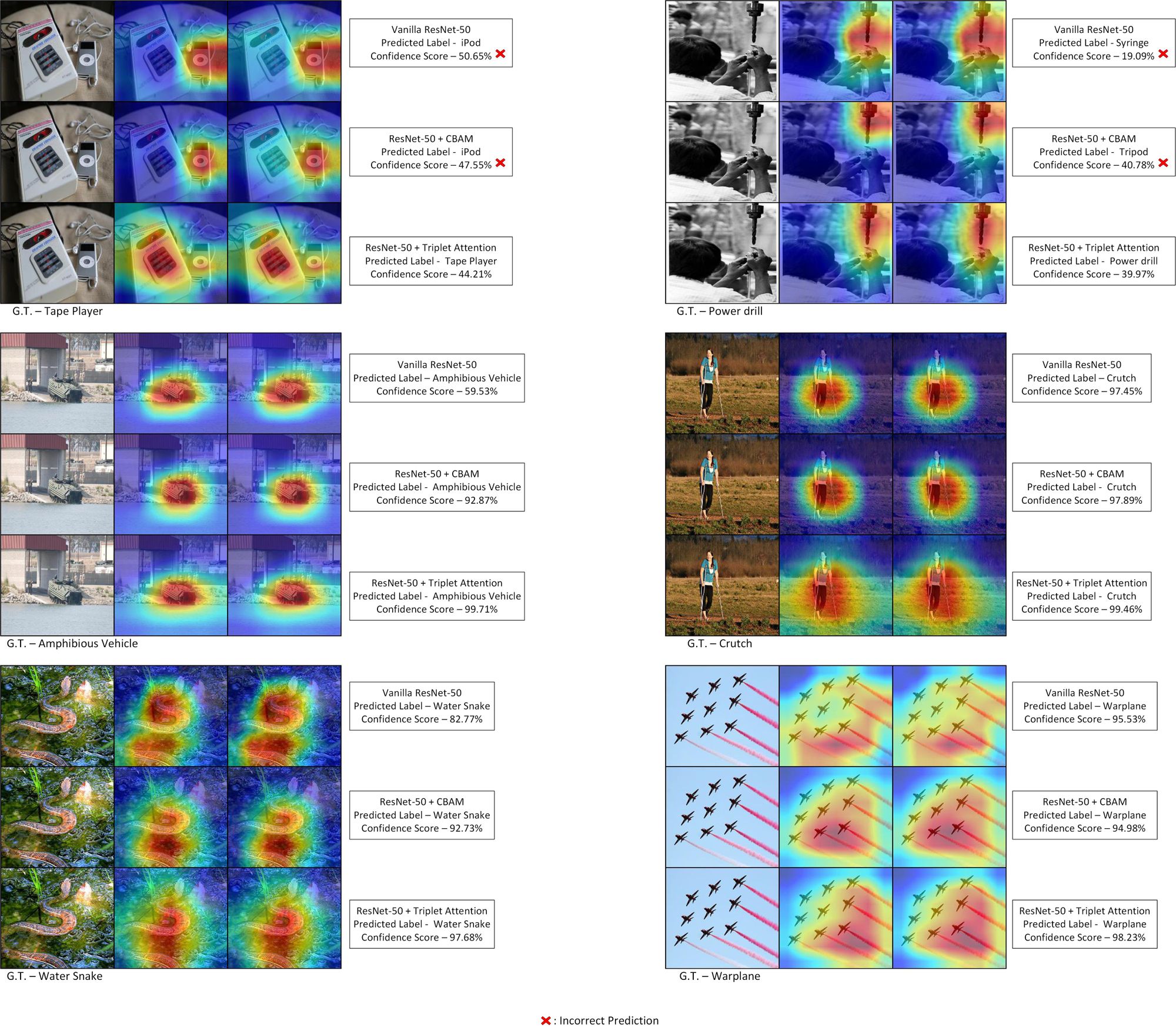
As shown above, the Triplet Attention Mechanism can provide extremely respectable results on diverse and difficult tasks, like ImageNet classification and object detection on MS-COCO, while being extremely lightweight in terms of parametric complexity. More importantly, it provides better and tighter ROI bounds on the GradCAM and GradCAM++ plots, which is extremely important for the interpretability of the attention mechanism. Because of the Cross-Dimension Interaction, Triplet Attention can find refined objects with a smaller scope.
Shortcomings
- Although the paper introduces an extremely lightweight and efficient attention mechanism, the resulting increase in FLOPs is still high.
- The way of aggregating the attention weights in each of the three branches of Triplet Attention by simple averaging might be sub-optimal, and could be significantly improved.
References
- Rotate to Attend: Convolutional Triplet Attention Module
- Official Implementation of Triplet Attention
- Squeeze-and-Excitation Networks
- GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
- CBAM: Convolutional Block Attention Module
- BAM: Bottleneck Attention Module
- ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks











