

Python might be one of today's most popular programming languages, but it's definitely not the most efficient. In the machine learning world in particular, practitioners sacrifice efficiency for the ease-of-use that Python offers.
That doesn't mean that you can't speed things up in other ways. Cython is an easy way to significantly lessen computation time of Python scripts, without sacrificing the functionality easily achieved using Python.
This tutorial will introduce you to using Cython to speed up Python scripts. We'll look at a simple yet computationally expensive task: creating a for loop that iterates through a Python list of 1 billion numbers, and sums them. Since time is particularly important when running code on resource-limited devices, we'll put this issue into context by considering how to implement Python code in Cython on Raspberry Pi (RPi). Cython makes a significant change in the speed of calculation. Think of it like a sloth compared to a cheetah.

The sections covered in this tutorial are as follows:
- Python, CPython, and Cython
- Cythonizing Simple Python Code
- Cythonizing a for Loop
- Assigning C Data Types to the Variables
- Using Cython in Raspberry Pi
Let's get started.
Bring this project to life
Python and CPython
Many people are unaware of the fact that languages like Python are actually implemented in other languages. For example, the C implementation of Python is called CPython. Note that it is not Cython. For more information about the different implementations of Python, you can read this post.
The default and most popular implementation of Python is CPython. There is an important advantage of using it. C is a compiled language and its code is converted into machine code, which is executed directly by the central processing unit (CPU). Now you may wonder, if C is a compiled language, does that mean Python is too?
Python implementation in C (CPython) is not 100% complied, and also not 100% interpreted. There is both compilation and interpretation in the process of running a Python script. To make this clear, let's see the steps of running a Python script:
- Compiling source code using CPython to generate bytecode
- Interpreting the bytecode in a CPython interpreter
- Running the output of the CPython interpreter in a CPython virtual machine
Compilation takes place when CPython compiles the source code (.py file) to generate the CPython bytecode (.pyc file). The CPython bytecode (.pyc file) is then interpreted using a CPython interpreter, and the output runs in a CPython virtual machine. According to the above steps, the process of running a Python script involves both compilation and interpretation.
The CPython compiler generates the bytecode just once, but the interpreter is called each time the code runs. Usually the interpretation of the bytecode takes a lot of time. If using an interpreter slows down the execution, why use it at all? The big reason is that it helps make Python cross-platform. Since the bytecode runs in a CPython virtual machine on top of the CPU, it is independent of the machine it's running on. As a result, the bytecode can run in different machines unchanged.
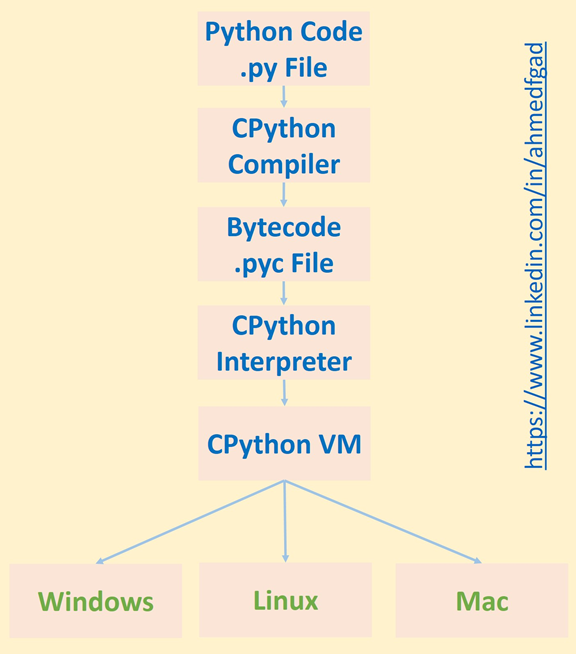
If there is no interpreter used, then the CPython compiler will generate machine code that directly runs in the CPU. Because different platforms have different instructions, the code will not be cross-platform.
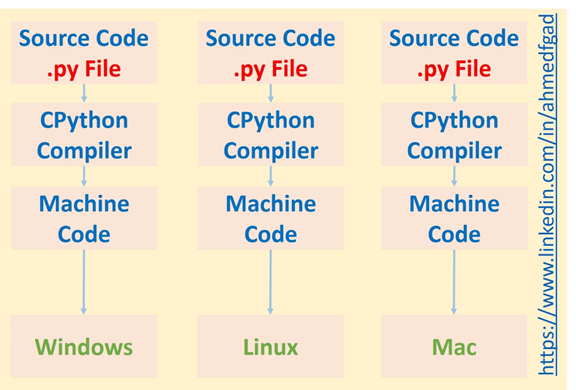
In summary, using a compiler speeds up the process but an interpreter makes the code cross-platform. So, a reason why Python is slower than C is that an interpreter is used. Remember that the compiler just runs once but the interpreter runs each time the code is executed.
Python is much slower than C, but many programmers still prefer it since it's so much easier to use. Python hides many details from the programmer, which can help prevent frustrating debugging. For instance, since Python is a dynamically-typed language you do not have to explicitly specify the type of each variable in your code – Python will deduce it automatically. In contrast, with statically-typed languages (like C, C++ or Java) you must specify the types of the variables, as seen below.
int x = 10
string s = "Hello"Compare this to the implementation below in Python. Dynamic typing makes it easier to code, but adds much more burden on the machine to find the suitable datatype. This makes the process slower.
x = 10
s = "Hello"Generally speaking, "higher level" languages like Python are much easier to use for developers. However, when the code is run it will need to be converted into low-level instructions. This conversion takes more time, which is sacrificed for ease-of-use.
If time is an important factor, then you need to use the lower-level instructions. So rather than typing the code using Python, which is the interface, you can write it using CPython which is the backend of Python implemented in C. However, if you do so you will feel that you are programming in C, not Python.
CPython is much more complex. In CPython, everything is implemented in C. There is no way to escape the C complexity in coding. This is why many developers opt for Cython instead. But how is Cython different from CPython?
How Cython Is Different
According to the Cython documentation, Cython is Python with C data types. Another definition from the Cython tutorial 2009 paper clarifies:
Cython is a programming language based on Python with extra syntax to provide static type declarations. This takes advantage of the benefits of Python while allowing one to achieve the speed of C.
According to the above definitions, Cython is a language which lets you have the best of both worlds – speed and ease-of-use. You can still write regular code in Python, but to speed things up at run time Cython allows you to replace some pieces of the Python code with C. So, you end up mixing both languages together in a single file. Note that you can imagine that everything in Python is valid in Cython, but with some limitations. For more info about the limitations, you can visit this page.
The regular Python file has a .py extension, but the Cython file has the .pyx extension instead. The same Python code can be written inside the .pyx files, but these allow you to also use Cython code. Note that just placing the Python code into a .pyx file may speed up the process compared to running the Python code directly, but not as much as when also declaring the variable types. Thus, the focus of this tutorial is not only on writing the Python code within the .pyx file but also on making edits which will make it run faster. By doing so we add a bit of difficulty to the programming, but much time is saved from doing so. If you have any experience with C programming, then it will be even easier for you.
Cythonizing Simple Python Code
To make your Python into Cython, first you need to create a file with the .pyx extension rather than the .py extension. Inside this file, you can start by writing regular Python code (note that there are some limitations in the Python code accepted by Cython, as clarified in the Cython docs).
Before going forward, make sure Cython is installed. You can do so with the following command.
pip install cythonTo generate the .pyd/.so file we need to first build the Cython file. The .pyd/.so file represents the module to be imported later. To build the Cython file, a setup.py file will be used. Create this file and place the code below within it. We'll use the distutils.core.setup() function to call the Cython.Build.cythonize() function, which will cythonize the .pyx file. This function accepts the path of the file you want to cythonize. Here I'm assuming that the setup.py file is placed in the same location as the test_cython.pyx file.
import distutils.core
import Cython.Build
distutils.core.setup(
ext_modules = Cython.Build.cythonize("test_cython.pyx"))In order to build the Cython file, issue the command below in the command prompt. The current directory of the command prompt is expected to be the same as the directory of the setup.py file.
python setup.py build_ext --inplaceAfter this command completes, two files will be placed beside the .pyx file. The first one has the .c extension and the other file will have the extension .pyd (or similar, based on the operating system used). In order to use the generated file, just import the test_cython module and the "Hello Cython" message will appear directly, as you see below.
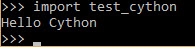
We have now successfully cythonized the Python code. The next section discusses cythonizing a .pyx file in which loop is created.
Cythonizing a "for" Loop
Now let's optimize our aforementioned task: a for loop that iterates through 1 million numbers and sums them. Let's start by looking at the efficiency of just the iterations of the loop. The time module is imported for estimating how long it takes to execute.
import time
t1 = time.time()
for k in range(1000000):
pass
t2 = time.time()
t = t2-t1
print("%.20f" % t)In a .pyx file, the mean time for 3 runs is 0.0281 seconds. The code is running on a machine with Core i7-6500U CPU @ 2.5 GHz and 16 GB DDR3 RAM.
Compare this with the time it takes to run in a normal Python file, the mean of which is 0.0411 seconds. This means Cython is 1.46 times faster than Python for the iterations alone, even though we don't need to modify the for loop to get it to execute at C-speed.
Now let's add the summing task. We'll use the range() function for this.
import time
t1 = time.time()
total = 0
for k in range(1000000):
total = total + k
print "Total =", total
t2 = time.time()
t = t2-t1
print("%.100f" % t)Note that both of the scripts return the same value, which is 499999500000. In Python this takes an average of 0.1183 seconds to run (between three trials). In Cython it is 1.35 times faster, at an average of 0.0875 seconds.
Let's see another example in which the loop iterates through 1 billion number starting from 0.
import time
t1 = time.time()
total = 0
for k in range(1000000000):
total = total + k
print "Total =", total
t2 = time.time()
t = t2-t1
print("%.20f" % t)The Cython script completed in nearly 85 seconds (1.4 minutes) while the Python script completed in nearly 115 seconds (1.9 minutes). In both cases it's simply too much time. What is the benefit of using Cython if it lasts for more than a minute on such a trivial task? Note that this is our fault, not Cython's.
As discussed previously, writing the Python code within the Cython .pyx script is an improvement, but it does not make a very large cut in the execution time. We have to make edits to the Python code within the Cython script. The first thing to focus on is to explicitly define the data types of the variables used.
Assigning C Data Types to Variables
According to the previous code, there are 5 variables used: total, k, t1, t2, and t. All of these variables have their data types deduced implicitly by the code, thus taking more time. To save the time used for deducing their data types, let's assign their data types from the C language instead.
The type of the total variable is unsigned long long int. It is an integer because the sum of all numbers is an integer, and it is unsigned because the sum will be positive. But why it is long long? Because the sum of all numbers is very large, long long is added to increase the variable size to the maximum possible size.
The type defined for the variable k is int, and the float type is assigned for the remaining three variables t1, t2, and t.
import time
cdef unsigned long long int total
cdef int k
cdef float t1, t2, t
t1 = time.time()
for k in range(1000000000):
total = total + k
print "Total =", total
t2 = time.time()
t = t2-t1
print("%.100f" % t)Note that the precision defined in the last print statement is set to 100, and all of these numbers are zeros (see the next figure). This is what we can expect from using Cython. While Python takes more than 1.9 minutes, Cython takes no time at all. I cannot even say that the speed is 1000 or 100000 faster than Python; I tried different precisions for the printed time, and still no number appears.

Note that you can also create an integer variable for holding the value passed to the range() function. This will boost performance even more. The new code is listed below, where the value is stored in the maxval integer variable.
import time
cdef unsigned long long int maxval
cdef unsigned long long int total
cdef int k
cdef float t1, t2, t
maxval=1000000000
t1=time.time()
for k in range(maxval):
total = total + k
print "Total =", total
t2=time.time()
t = t2-t1
print("%.100f" % t)Now that we've seen how to speed up the performance of the Python scripts by using Cython, let's apply this to Raspberry Pi (RPi).
Accessing Raspberry Pi from PC
If this is the first time you're using your Raspberry Pi, then both your PC and the RPi need to get connected over a network. You can do this by connecting both of them to a switch in which the DHCP (Dynamic Host Configuration Protocol) is active to assign them IP addresses automatically. After successful network creation, you can access the RPi based on the IPv4 address assigned to it. How do you know what the IPv4 address assigned to your RPi is? Don't worry, you can simply use an IP scanner tool. In this tutorial, I will use a free application called Advanced IP Scanner.
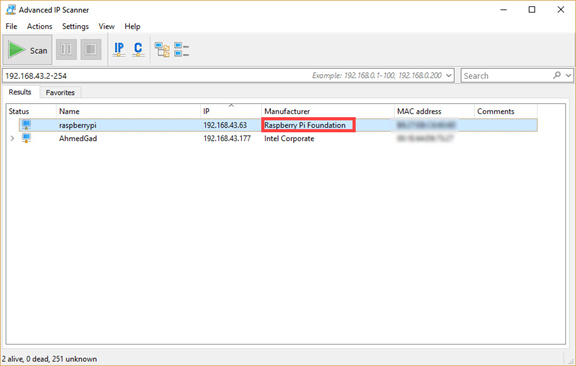
The interface of the application is as seen below. It accepts a range of IPv4 addresses to search for, and returns the information for active devices.
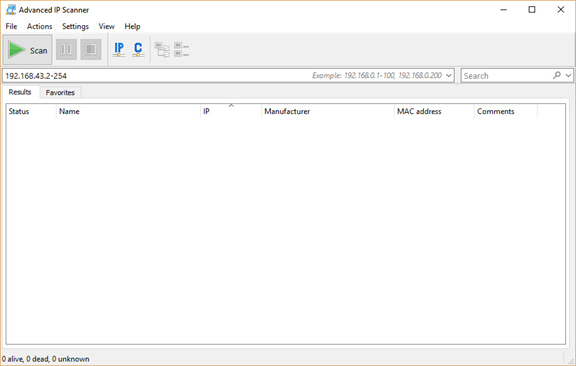
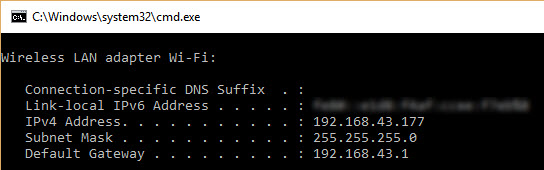
You need to enter the range of IPv4 addresses in your local network. If you do not know the range, just issue the ipconfig command in Windows (or ifconfig in Linux) to know your PC IPv4 address (as shown in the figure below). In my case, the IPv4 address assigned to the Wi-Fi adapter of my PC is 192.168.43.177 and the subnet mask is 255.255.255.0. This means that the range of IPv4 addresses in the network is from 192.168.43.1 to 192.168.43.255. According to the figure, the IPv4 address 192.168.43.1 is assigned to the gateway. Note that the last IPv4 address in the range, 192.168.43.255, is reserved for broadcast messages. Thus, the range to search should start from 192.168.43.2 and end at 192.168.43.254.
According to the result of the scan shown in the next figure, the IPv4 address assigned to the RPi is 192.168.43.63. This IPv4 address can be used to create a secure shell (SSH) session.
For establishing the SSH session, I will use a free software called MobaXterm. The interface of the application is as follows.
In order to create an SSH session, just click on the Session button at the top-left corner. A new window appears as shown below.
From this window, click on the SSH button at the top-left corner to open the window shown below. Just enter the IPv4 address of the RPi and the username (which is by default pi), then click OK to start the session.
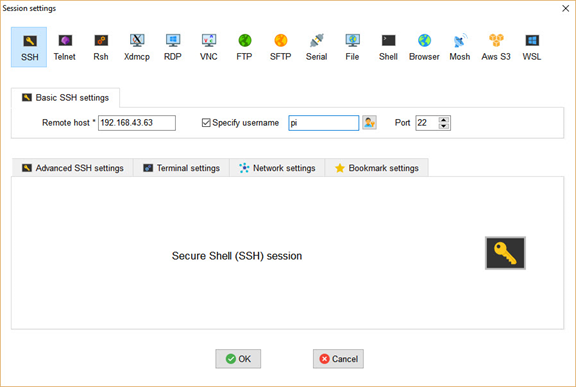
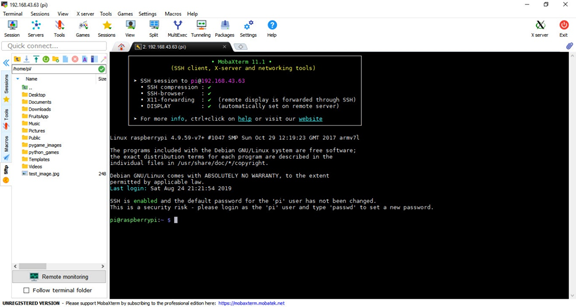
After clicking the OK button, a new window appears asking for the password. The default password is raspberrypi. After logging in, the next window appears. The pane to the left helps to navigate the directories of the RPi easily. There is also a command-line for entering commands.
Using Cython with Raspberry Pi
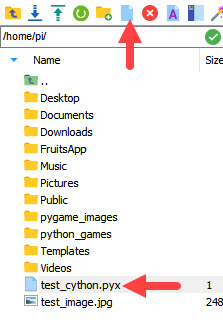
Create a new file and set its extension to .pyx for writing the code of the last example. There are options in the bar at the left pane for creating new files and directories. You can use the new file icon to make things even simpler, as shown in the following figure. I created a file named test_cython.pyx in the root directory of the RPi.
Just double-click the file to open it, paste the code, and save it. After that we can create the setup.py file, which is exactly the same as we discussed previously. Next we must issue the following command for building the Cython script.
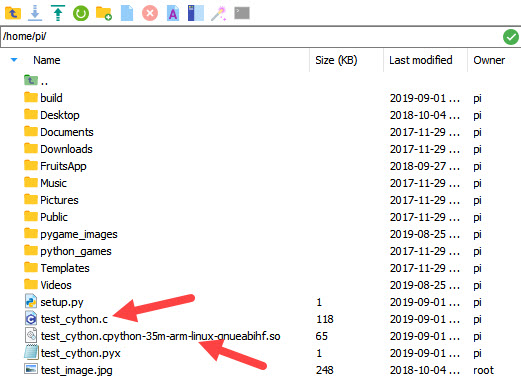
python3 setup.py build_ext --inplaceAfter this command completes successfully, you can find the output files listed in the left pane according to the next figure. Note that the extension of the module to be imported is now .so, as we are no longer using Windows.
Now let's activate Python and import the module, as shown below. The same results achieved on the PC are also achieved here; the consumed time is essentially zero.

Conclusion
This tutorial discussed how to use Cython to reduce the computation time of executing Python scripts. We looked at the example of using a for loop to sum all elements in a Python list of 1 billion numbers, and compared its time for execution with and without declaring the variable types. While this takes nearly two minutes to run in pure Python, it takes essentially no time to run with static variables declared using Cython.
In the next tutorial we'll replace this Python list with a NumPy array, and see how we can optimize NumPy array processing using Cython. Then we'll look at how to cythonize more advanced Python scripts, such as genetic algorithms. This are great ways to easily enhance the efficiency of your machine learning projects.










