Are you looking for an efficient and modern framework to create your deep learning model? Look no further than PyTorch!
In this article we'll cover an introduction to PyTorch, what makes it so advantageous, and how PyTorch compares to TensorFlow and Scikit-Learn. Then we'll look at how to use PyTorch by building a linear regression model, and using it to make predictions.
Let's get started.
Introduction to PyTorch
PyTorch is a machine learning framework produced by Facebook in October 2016. It is open source, and is based on the popular Torch library. PyTorch is designed to provide good flexibility and high speeds for deep neural network implementation.
PyTorch is different from other deep learning frameworks in that it uses dynamic computation graphs. While static computational graphs (like those used in TensorFlow) are defined prior to runtime, dynamic graphs are defined "on the fly" via the forward computation. In other words, the graph is rebuilt from scratch on every iteration (for more information, check out the Stanford CS231n course).
Bring this project to life
Advantages of PyTorch
While PyTorch has many advantages, here we'll focus on a core few.
1. Pythonic Nature
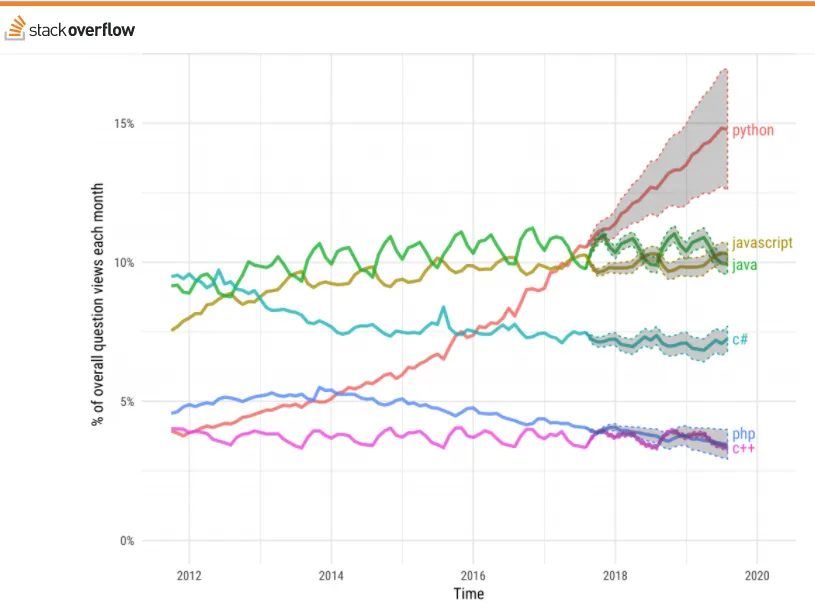
As you can see from the graph below, Python is one of the fastest growing programming languages from the last 5-10 years. Most machine learning and artificial intelligence-related work is done using Python. PyTorch is Pythonic, which means that Python developers should feel more comfortable while coding with PyTorch than with other deep learning frameworks. That being said, PyTorch has a C++ frontend as well.
You can also use your favorite Python packages (like NumPy, SciPy, and Cython) to extend PyTorch functionalities when desired.
2. Easy to Learn
Like the Python language, PyTorch is considered relatively easier to learn compared to other deep learning frameworks. The primary reason is due to its easy and intuitive syntax.
3. Strong Community
Though PyTorch is a comparatively newer framework, it has developed a dedicated community of developers very quickly. Not only that, the documentation of PyTorch is very organised and helpful for developers.
4. Easy Debugging

PyTorch is deeply integrated with Python, so many Python debugging tools can be easily used with it. For example, the Python pdb and ipdb tools can be used to debug PyTorch code. PyCharm’s debugger also works seamlessly with PyTorch code.
PyTorch vs TensorFlow
- Dynamic vs Static: Though both PyTorch and TensorFlow work on tensors, the primary difference between PyTorch and Tensorflow is that while PyTorch uses dynamic computation graphs, TensorFlow uses static computation graphs. That being said, with the release of TensorFlow 2.0 there has been a major shift towards eager execution, and away from static graph computation. Eager execution in TensorFlow 2.0 evaluates operations immediately, without building graphs.
- Data Parallelism: PyTorch uses asynchronous execution of Python to implement data parallelism, but with TensorFlow this is not the case. With TensorFlow you need to manually configure every operation for data parallelism.
- Visualization Support: TensorFlow has a very good visualization library called TensorBoard. This visualization support helps developers to track the model training process nicely. PyTorch initially had a visualization library called Visdom, but has since provided full support for TensorBoard as well. PyTorch users can utilize TensorBoard to log PyTorch models and metrics within the TensorBoard UI. Scalars, images, histograms, graphs, and embedding visualizations are all supported for PyTorch models and tensors.
- Model Deployment: TensorFlow has great support for deploying models using a framework called TensorFlow serving. It is a framework that uses REST Client API for using the model for prediction once deployed. On the other hand, PyTorch does not provide a framework like serving to deploy models onto the web using REST Client.
PyTorch vs Scikit-Learn
Deep Learning vs Machine Learning: Sklearn, or scikit-learn, is a Python library primarily used in machine learning. Scikit-learn has good support for traditional machine learning functionality like classification, dimensionality reduction, clustering, etc. Sklearn is built on top of Python libraries like NumPy, SciPy, and Matplotlib, and is simple and efficient for data analysis. However, while Sklearn is mostly used for machine learning, PyTorch is designed for deep learning. Sklearn is good for defining algorithms, but cannot really be used for end-to-end training of deep neural networks.
Ease of Use: Undoubtedly Sklearn is easier to use than PyTorch. Mostly you will have to write more lines of code to implement the same code in PyTorch compared to Sklearn.
Ease of Customization: It goes without saying that if you want to customize your code for specific problems in machine learning, PyTorch will be easier to use for this. Sklearn is relatively difficult to customize.
The Tensor in PyTorch
PyTorch tensors are similar to NumPy arrays with additional feature such that it can be used on Graphical Processing Unit or GPU to accelerate computing.
A scalar is zero dimensional array for example a number 10 is a scalar.
A vector is one dimensional array for example [10,20] is a vector.
A matrix is two dimensional array.
A tensor is three or more dimensional array.
However, it is common practice to call vectors and matrices as a tensor of dimension one and two respectively.
The main difference between a PyTorch Tensor and a numpy array is that a PyTorch Tensor can run on Central Processing Unit as well as Graphical Processing Unit. If you want to run the PyTorch Tensor on Graphical Processing Unit you just need to cast the Tensor to a CUDA datatype.
CUDA stands for Compute Unified Device Architecture. CUDA is a parallel computing platform and application programming interface model created by Nvidia. It allows developers to use a CUDA-enabled graphics processing unit.
Creating a Regression Model
Linear Regression is one of the most popular machine learning algorithm that is great for implementing as it is based on simple mathematics. Linear regression is based on the mathematical equation of a straight line, which is written as y = mx + c, where m stands for slope of the line and c stands for y axis intercept.
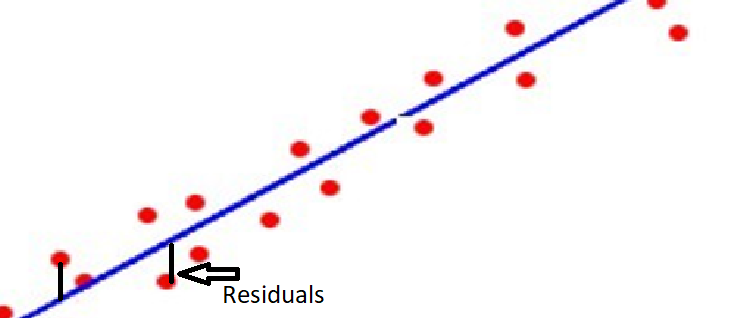
As you can see in the above image we have data points represented in red dots and we are trying to fit a line that should represents all the data points. Note that all the red data points may not be on the straight line, however our aim is to find the straight line that best fits all the data points. And finding that best fit straight line essentially means finding the slope m and intercept c, as these two parameters can define a unique line. Note that here x is called independent variable and y is called dependent variable.
Assumptions of Linear Regression
There is five important assumption for linear regression.
- Linear regression assumes the relationship between the independent and dependent variables to be linear.
- The data is normally distributed
- Independent variables (if more than one) are not correlated with each other.
- There is no auto-correlation in the data. Auto-correlation is observed when the residuals are dependent on each other. For example, for stock price data the price is dependent on the previous price.
- Data is homoscedastic, which means the residuals are equal across the regression line.
Prerequisites to Build the Model
You can install numpy, pandas and PyTorch using the commands below.
pip install numpy
pip install pandas
conda install pytorch torchvision cudatoolkit=10.1 -c pytorchNote that after installing the PyTorch, you will be able to import torch as shown below.
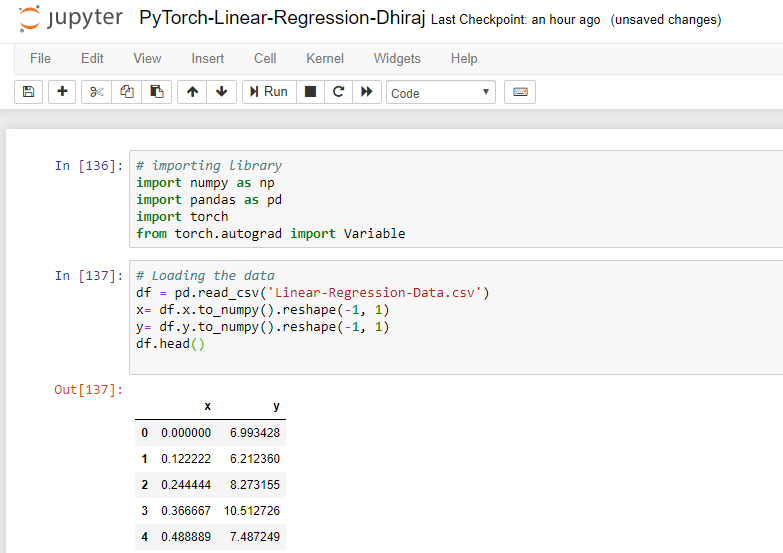
Importing Libraries
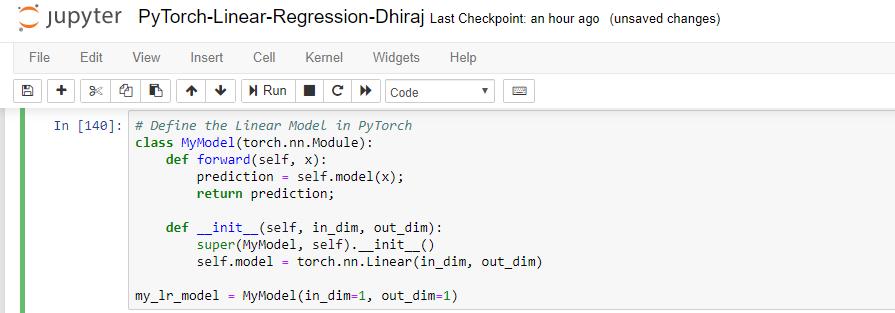
Defining the Model
Let us start defining our model by creating a class called MyModel as shown below. Inside the class MyModel we need to define two methods named forward and init. After that we will create the instance of the class MyModel and the instance name here is my_lr_model.
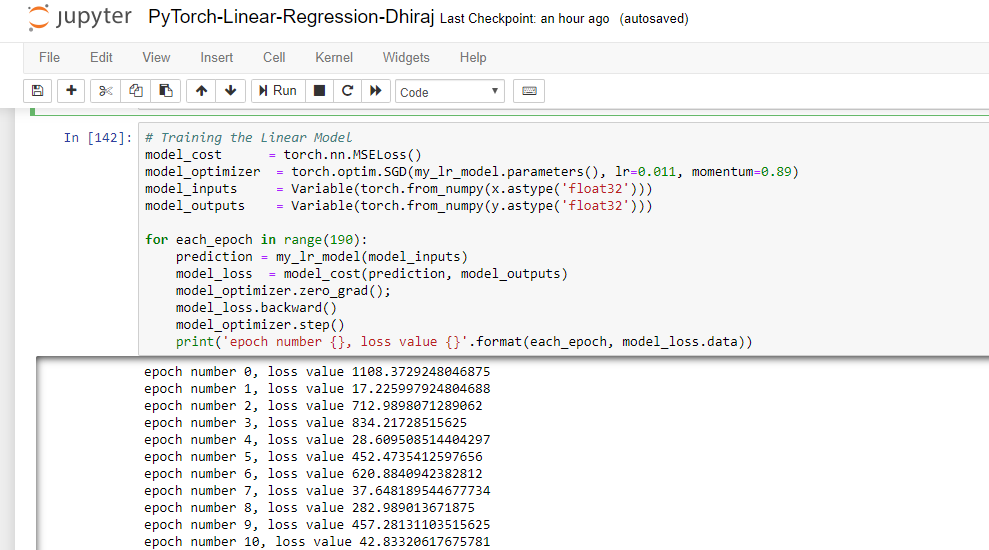
Training the Model
Now we are ready for training the model. Before we start the training we need to define loss function ( here MSELoss), optimizer (here SGD or stochastic gradient descent), and then we have to assign learning rate (0.011 in this case) and momentum (0.89).
The learning rate also called step size is a hyper-parameter which decides how much to change the machine learning model with respect to the calculated error every time the model weights are changed.
Momentum is a hyper-parameter which accelerate the model training and learning rate which results in faster model convergence. By default momentum is set to zero.
In PyTorch a Variable is a wrapper around a Tensor. Thus Variable supports nearly all the API’s defined by a Tensor.
Once these parameters are defined we need to start the epochs using for loop. Note how the loss value is changing with each epoch.
Prediction
After the model is trained, the next step is to predict the value of a test input. Here we consider an input value of 4.0, and we get a prediction (output) of 21.75.
Note that for feeding the input value to the model we need to convert the float value in tensor format using the torch.Tensor method. Hence we tested that our model is working and giving the output as well.

In Summary
In this tutorial we learned what PyTorch is, what its advantages are, and how it compares to TensorFlow and Sklearn. We also discussed tensors in PyTorch, and looked at how to build a simple linear regression model.
Thanks for reading! If you have any questions or points for discussion, check out Paperspace Community.










