

Introduction
In data science and especially Natural Language Processing, summarization is, and always has been, a subject of intense interest. While text summarization methods have been around for some time, recent years have seen significant developments in natural language processing and deep learning. There is a flurry of papers being published on the topic by internet giants, like the recent ChatGPT. While a great deal of work is being done on this topic of study, there is very little written on practical implementations of AI-driven summarization. The difficulty of parsing broad, sweeping statements is an obstacle to effective summarization.
Summarizing a news article and a financial profits report are two different tasks. When dealing with text features that vary in length or subject matter (tech, sports, finance, travel, etc.), summarizing becomes a challenging data science job. It's essential to cover some groundwork in summarizing theory before delving into an overview of applications.
Extractive Summarization
The process of extractive summarizing involves picking the most relevant sentences from an article and systematically organizing them. The sentences making up the summary are taken verbatim from the source material.
Extractive summarization systems, as we know them now, revolve around three fundamental operations:
1) Construction of an intermediate representation of the input text
Topic representation and indicator representation are examples of representation-based methods. To understand the subject(s) mentioned in the text, topic representation converts the text into an intermediate representation.
2) Scoring the sentences based on the representation
At the time of the generation of the intermediate representation, each sentence is given a significance score. When using a method that relies on topic representation, a sentence's score reflects how effectively it elucidates critical concepts in the text. In indicator representation, the score is computed by aggregating the evidence from different weighted indicators.
3) Selection of a summary comprising several sentences
To generate a summary, the summarizer software picks the top k sentences. For example, some methods use greedy algorithms to pick and choose which sentences are most relevant, while others may transform sentence selection into an optimization problem in which a set of sentences is selected under the stipulation that it must maximize overall importance and coherence while minimizing the quantity of redundant information.
Let's take a deeper dive into the methods we stated:
Topic Representation Approaches
Topic words: Using this method, you can find terms related to the topic in an input document. A sentence's significance can be calculated in two ways: first, as a function of the number of topic signatures it includes; second, as a fraction of the topic signatures it contains.
While the first method gives higher scores to longer sentences with more words, the second one measures the density of the topic words.
Frequency-driven approaches: Through this method, words are given relative importance. If the term fits the topic, it gets 1 point; otherwise, it reaches zero. Depending on how they are implemented, the weights might be continuous. Topic representations may be achieved using one of two methods:
- Word Probability: It only takes a word's frequency to indicate its significance. To calculate the likelihood of a word w, we divide the frequency with which it occurs, f (w), by the total number of words, N.
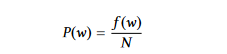
The average significance of the words in a sentence gives the importance of the sentence when using word probabilities.
- TFIDF.(Term Frequency Inverse Document Frequency): This method is an improvement upon the word probability approach. Here, the weights are determined by using the TF-IDF approach. The Term Frequency Inverse Document Frequency (TFIDF) technique gives less importance to terms that often appear in most documents. The weight of each word w in document d is computed as follows:
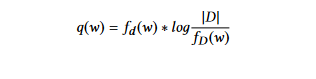
where fd (w) is the term frequency of word w in document d,
fD (w) is the number of documents that contain the word w, and |D| is the number of documents in the collection D.
Latent Semantic Analysis: Latent semantic analysis (LSA) is an unsupervised method for extracting a representation of text semantics based on observed words. The LSA process starts with the construction of a term-sentence matrix (n by m), where each row represents a word from the input (n-words), and each column represents a sentence(m sentences). In the matrix, the weight of the word i in sentence j is defined by the entry aij. According to the TFIDF technique, each word in a sentence is given a certain weight, with zero being assigned to terms that aren't included in the sentence.
Indicator Representation Approaches
Graph-Based methods
Graph methods, influenced by the PageRank algorithm, represent the documents as a connected graph. Sentences form the graph's vertices, and the edges connecting sentences show the degree to which two sentences are related to one another. One method often used to link two vertices is to assess the degree to which two sentences are similar, and if the degree of similarity is higher than a certain threshold, the vertices are connected. Both outcomes are possible with this graph representation. First, the graph's partitions (sub-graphs) define individual categories of information covered by the documents. The second result is that the document's key sentences have been highlighted. Sentences connected to many other sentences in the partition are possibly the center of the graph and are more likely to be included in the summary. Both single- and multi-document Summarization can benefit from using graph-based techniques.
Machine Learning
Machine learning techniques see the summarization problem as a classification challenge. Models attempt to categorize sentences into summary and non-summary categories based on their features. We have a training set consisting of documents and human-reviewed extracted summaries from which to train our algorithms. It is often done using Naive Bayes, Decision Tree, or Support Vector Machine.
Abstractive Summarization
In contrast to extractive summarizing, abstractive Summarization is a more effective method. The capacity to create unique sentences that convey vital information from text sources has contributed to this rising appeal.
An abstractive summarizer presents the material in a logical, well-organized, and grammatically sound form. A summary's quality can be significantly enhanced by making it more readable or improving its linguistic quality. (include image).
There are two approaches: The Structured based approach and the Semantic-Based approach.
STRUCTURE-BASED APPROACH
In a structured firstly based method, the most important information from the document(s) is encoded using psychological feature schemas like templates, extraction rules, and alternative structures, including tree, ontology, lead and body, rule, and graph-based structure. In the following, we'll read about some of the several methods that are integrated into this strategy.
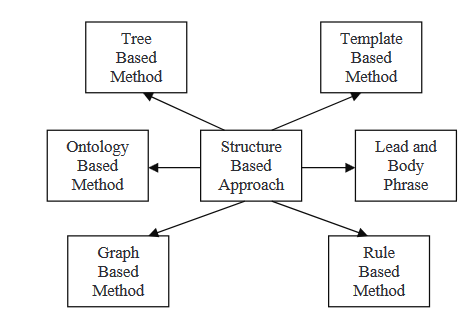
Tree-based methods
In this method, the content of a document is represented as a dependency tree. Content selection for an outline can be performed via several other techniques, such as a topic intersection algorithmic program or one that makes use of native alignment try across parsed sentences. This approach employs either a language generator or an associate degree algorithm for outline generation. In this paper, the authors offer a sentence fusion method that uses bottom-up local multi-sequence alignment to find the common information phrases. Multigene summarization systems use a technique called sentence fusion.
In this method, a set of documents is used as inputs, processed using a topic selection algorithm to extract the central theme, and then a clustering algorithm is used to rank the phrases in order of importance. After the sentences have been arranged, they are fused using sentence fusion, and a statistical summary is generated. The structured method encodes the most important data from the document(s) using psychological feature schemas such as templates, extraction rules, and alternative structures such as tree, ontology, lead and body, rule, and graph-based structure.
Template-based methods
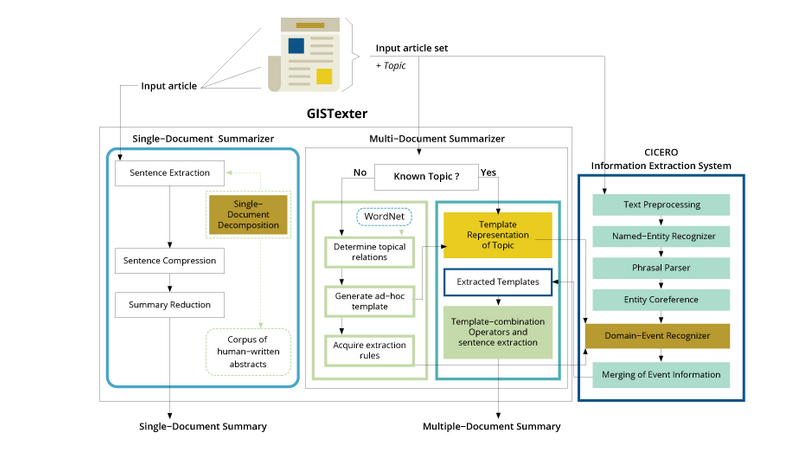
A guide is used in this method to represent an entire document. Linguistic patterns or extraction criteria are compared to identify text snippets that can be mapped into guide slots. These text snippets are the outline content's area unit indicators. This paper suggested two methods(single and multi-document Summarization) for document summarizing. To create extracts and abstracts from the documents, they followed the methods described in GISTEXTER.
Implemented for information extraction, GISTEXTER is a summarizing system that identifies topic-related information in the input text and converts it into database entries; the sentences are then added to the summary depending on user requests.
Ontology-based methods
Many researchers have attempted to improve summary effectiveness using ontology (knowledge base). Most internet documents have a common domain, meaning they all deal with the same general subject. Ontology is a powerful representation of the unique information structure of each domain.
This paper proposes using the fuzzy ontology, which models uncertainty and accurately describes domain knowledge, to summarize Chinese news. In this method, domain experts first define the domain ontology for news events, and then the Document preparation phase extracts semantic words from the news corpus and the Chinese news dictionary.
Lead and body phrase method
This approach involves rewriting the lead sentence by performing operations on phrases (insertion and substitution) with the same syntactic head chunk in the lead and body of the sentence. Using syntactic analysis of phrase pieces, Tanaka suggested a technique for summarizing broadcast news. Sentence fusion methods are used to infer the foundation of this concept.
Summarizing news broadcasts entails locating phrases shared by the lead and body chunks, then inserting and replacing those phrases to produce a summary via sentence revision. First, a syntactic parser is applied to the lead and body chunks. Next, trigger search pairs are identified, and finally, phrases are aligned using various similarity and alignment criteria. The last stage might be either an insertion or substitution or both.
The insertion process entails choosing an insertion point, checking for redundancy, and checking the discourse for internal coherence to ensure coherency and elimination of redundancy. The substitution step provides increased information by substituting the body phrase in the lead chunk.
Rule-based method
In this technique, the documents to be summarized
are depicted in terms of classes and listing of aspects. The content choice module selects the most effective candidate among those generated by data extraction rules to answer one or many aspects of a category. Finally, generation patterns are used for the generation of outline sentences.
To identify nouns and verbs that are semantically related, Pierre-Etienne et al. proposed a set of criteria for information extraction. Once extracted, the data is sent on to the content selection step that makes an effort to filter out mixing candidates. It is used for sentence structure and words in straight forward generation pattern. After generating, content-guided Summarization is performed.
Graph-based methods
Many researchers use a graph data structure to represent language document. Graphs are a popular choice for representing document in the linguistics study community. Each node in the system stands for a word unit that, along with directed edges, defines the structure of a sentence. To enhance the performance of the Summarization, Dingding Wang et al. proposed Multi-document summarization systems that use a wide range of strategies, such as the centroid-based method, the graph-based method, etc., to evaluate various baseline combination methods, such as average score, average rank, borda count, median aggregation, etc.
A unique weighted consensus methodology is developed to collect the results of different summarization strategies. In a semantic-based approach, a linguistic illustration of a document or documents is used to feed a natural language generation (NLG) system. This technique specializes in identifying noun phrases and verb phrases by linguistic data.
SEMANTIC-BASED APPROACH
Semantic-based approaches use a document's linguistic illustration to feed a natural language generation (NLG) system. This method processes linguistic data to identify noun phrases and verb phrases.
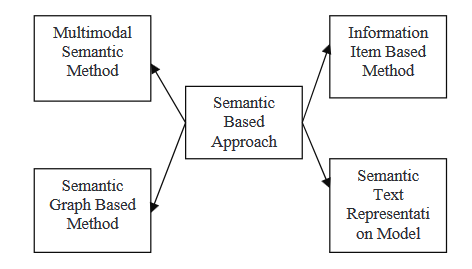
- Multimodal semantic model: In this method, a linguistics model that captures concepts and relationships between ideas is created to describe the contents of multimodal documents such as text and images. The key ideas are rated using several criteria, and the selected concepts are then expressed as sentences to form a summary.
- Information item-based method: In this approach, rather than using sentences from the supply documents, an abstract representation of those documents is used to generate the summary's content. The abstract illustration is an Information item, the smallest part of coherent information in a text.
- Semantic Graph Model: This technique aims to summarize a document by building a rich semantic graph (RSG) for the initial document, then reducing the created linguistics graph and generating the final abstractive outline from the reduced linguistics graph.
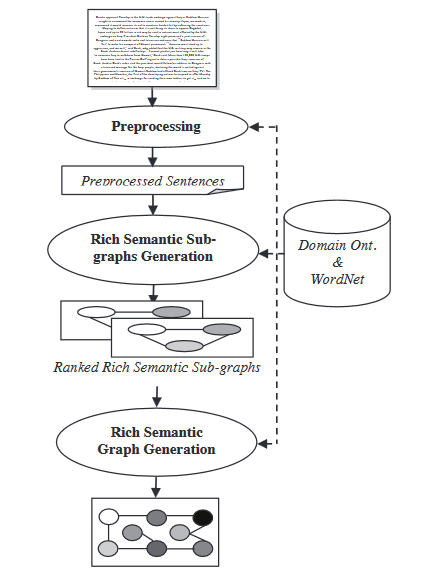
During Rich semantic graph generation module, a set of heuristic rules are applied to the generated rich semantic graph to reduce it by merging, deleting or consolidating the graph nodes.
- Semantic Text Representation Model: This technique analyzes input text using words' semantics rather than the syntax/Structure of text.
Case studies in business
- Computer language programming: Multiple efforts have been made to develop AI technology capable of independently writing code and developing websites. In the future, programmers may be able to rely on specialized "code summarizers" to extract the essentials from novel projects.
- Assisting those who are physically impaired: People who have trouble hearing may find that summary helps them better follow along with content as voice-to-text technology advances.
- Conferencing and other video meetings: With the expansion of teleworking, the ability to record significant ideas and content from interactions is increasingly required. It would be fantastic if your team sessions could be summarized using a voice-to-text method.
- The Search for Patents: Finding relevant patent information might be time-consuming. A patent summary generator might save you time whether you're doing market intelligence research or preparing to register a new patent.
- Books and literature: Summaries are helpful because they give readers a concise overview of the content they may expect from a book before deciding whether to purchase it.
- Advertising through social media: Organizations that create white papers, electronic books, and company blogs might use summarizing to make their work more digestible and shareable on platforms like Twitter and Facebook.
- Economy research: The investment banking industry invests vast sums of money on data acquisition for use in making decisions, such as computerized stock trading. Any financial analyst who spends all day poring through market data and news will eventually reach information overload. Financial documents, such as earnings reports and financial news, might benefit from summary systems that allow analysts to extract market signals from content swiftly.
- Promoting your business using Search Engine Optimization: Search engine optimization (SEO) evaluations need a thorough familiarity with the topics discussed in the content of one's competitors. It is of paramount importance considering Google's recent algorithm modification and subsequent emphasis on subject authority. The ability to swiftly summarize several documents, identify commonalities, and scan for crucial information may be a powerful research tool.
Conclusion
Although abstractive summarizing is less reliable than extractive approaches, it holds more incredible promise for producing summaries that align with how humans would write them. As a result, a plethora of fresh computational, cognitive, and linguistic techniques are likely to emerge in this area.
References
https://www.researchgate.net/publication/305912913_A_survey_on_abstractive_text_summarization
Towards Automatic Summarization. Part 2. Abstractive Methods: https://medium.com/sciforce/towards-automatic-summarization-part-2-abstractive-methods-c424386a65ea
20 Applications of Automatic Summarization in the Enterprise: https://www.frase.io/blog/20-applications-of-automatic-summarization-in-the-enterprise/











