
Since Ian Goodfellow gives machines the gift of imagination by creating a powerful AI concept GANs, researchers start to improve the generation images both when it comes to fidelity and diversity. Yet much of the work focused on improving the discriminator, and the generators continue to operate as black boxes until researchers from NVIDIA AI released StyleGAN from the paper A Style-Based Generator Architecture for Generative Adversarial Networks, which is based on ProGAN from the paper Progressive Growing of GANs for Improved Quality, Stability, and Variation.
This article is about one of the best GANs today, StyleGAN, We will break down its components and understand what's made it beat most GANs out of the water on quantitative and qualitative evaluation metrics, both when it comes to fidelity and diversity. One striking thing is that styleGAN can actually change finer grain aspects of the outputting image, for example, if you want to generate faces you can add some noise to have a wisp of hair tucked back, or falling over.
StyleGAN Overview
In this section, we will learn about StyleGAN's relatively new architecture that's considered an inflection point improvement in GAN, particularly in its ability to generate extremely realistic images.
We will start by going over StyleGAN, primary goals, then we will talk about what the style in StyleGAN means, and finally, we will get an introduction to its architecture in individual components.
StyleGAN goals
- Produce high-quality, high-resolution images.
- Greater diversity of images in the output.
- Increased control over image features. And this can be by adding features like hats or sunglasses when it comes to generating faces, or mixing styles from two different generated images together
Style in StyleGANs
The StyleGAN generator views an image as a collection of "styles," where each style regulates the effects on a specific scale. When it comes to generating faces:
- Coarse styles control the effects of a pose, hair, and face shape.
- Middles styles control the effects of facial features, and eyes.
- Fine styles control the effects of color schemes.

Main components of StyleGAN
Now let's see how the StyleGAN generator differs from a traditional GAN generator that we might be more familiar with.
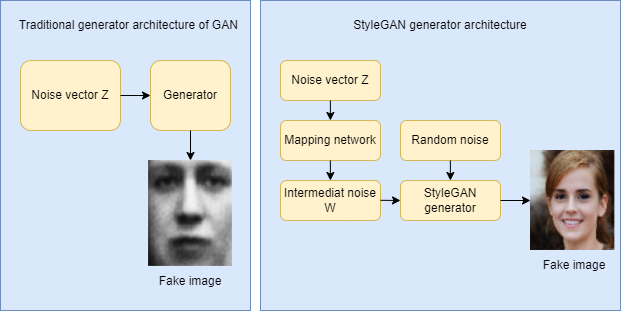
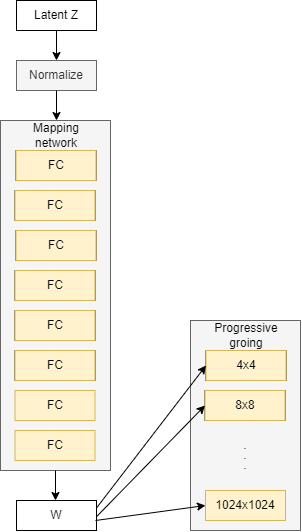
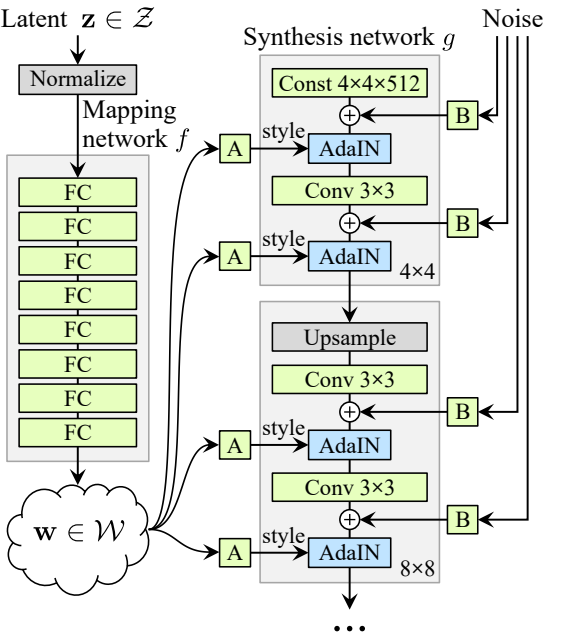
In a traditional GAN generator, we take a noise vector (let's name it z) into the generator and the generator then outputs an image. Now in StyleGAN, instead of feeding the noise vector z directly into the generator, it goes through a mapping network to get an intermediate noise vector (let's name it W) and extract styles from it. That then gets injected through an operation called adaptive instance normalization(AdaIN for short) into the StyleGAN generator multiple times to produce a fake image. And also there's an extra random noise that's passed in to add some features to the fake image (such as moving a wisp of hair in different ways).
The final important component of StyleGAN is progressive growing. Which slowly grows the image resolution being generated by the generator and evaluated by the discriminator over the process of training. And progressive growing originated with ProGAN.
So this was just a high-level introduction to StyleGAN, now let's get dive deeper into each of the StyleGAN components (Progressive growing, Noice mapping network, and adaptive instance normalization) and how they really work
Progressive growing
In traditional GANs we ask the generator to generate immediately a fixed resolution like 256 by 256. If you think about it's a kind of a challenging task to directly output high-quality images.
For progressive growing we first ask the generator to output a very low-resolution image like four by four, and we train the discriminator to also be able to distinguish on the same resolution, and then when the generator succeded with this task we up the level and we ask it to output the double of the resolution (eight by eight), and so on until we reach a really high resolution 1024 by 1024 for example.
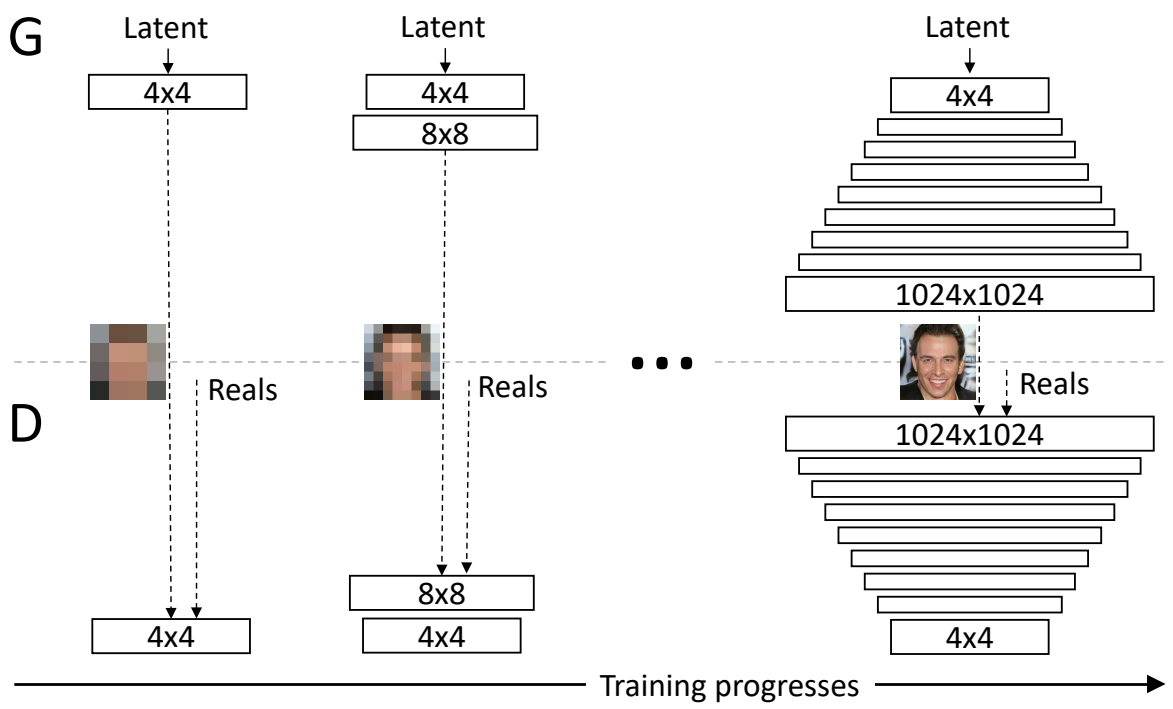
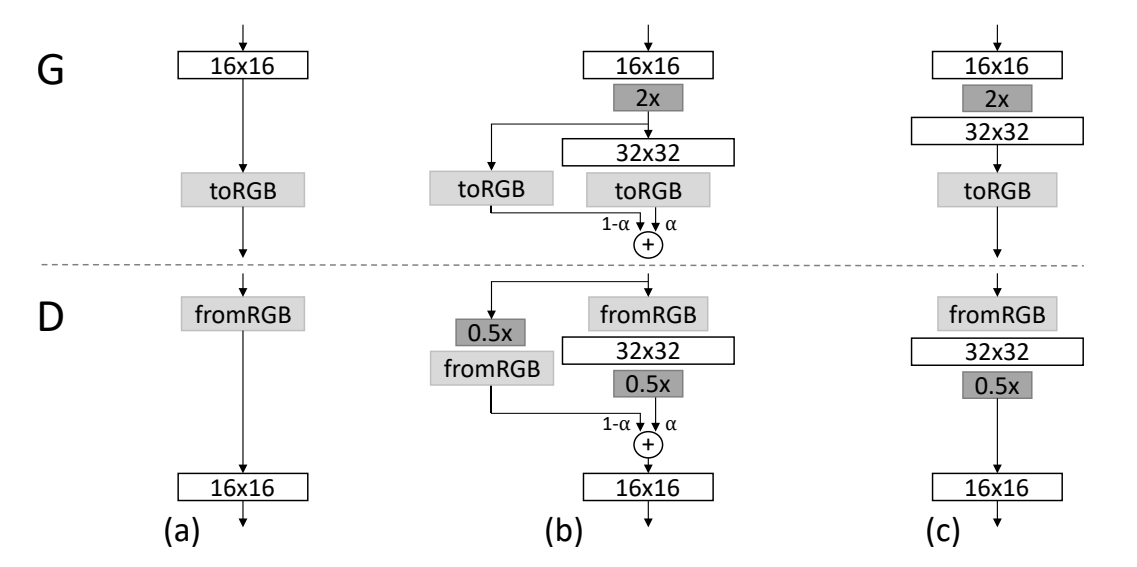
Progressive growing is more gradual than straightforward doubling in size immediately, when we want to generate a double-size image, the new layers are smoothly faded in. This fading in is controlled by a parameter α, which is linearly interpolated from 0 to 1 over the course of many training iterations. As you can see in the figure below, the final generated image is calculated with this formula [(1−α)×UpsampledLayer+(α)×ConvLayer]
Noise Mapping Network
Now we will learn about the Noise Mapping Network, which is a unique component of StyleGAN and helps to control styles. First, we will take a look at the structure of the noise mapping network. Then the reasons why it exists, and finally where its output the intermediate vector actually goes.
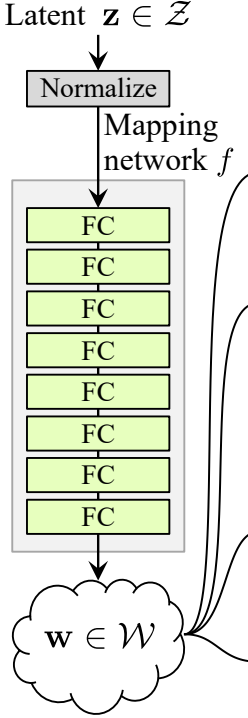
The noise mapping network actually takes the noise vector Z and maps it into an intermediate noise vector W. And this noise mapping network is composed of eight fully connected layers with activations in between, also known as a multilayer perceptron or MLP (The authors found that increasing the depth of the mapping network tends to make the training unstable). So it's a pretty simple neural network that takes the Z noise vector, which is 512 in size. And maps it into W intermediate noise factor, which is still 512 in size, so it just changes the values.
The motivation behind this is that mapping the noise vector will actually get us a more disentangled representation. In traditional GANs when the noise vector Z goes into the generator. Where we change one of these Z vector values we can actually change a lot of different features in our output. And this is not what the authors of StyleGANs want, because one of their main goals is to increase control over image features, so they come up with the Noise Mapping Network that allows for a lot of fine-grained control or feature-level control, and thanks to that we can now, for example, change the eyes of a generated person, add glasses, accessories, and much more things.
Now let's discover where the noise mapping network actually goes. So we see before progressive growing, where the output starts from low-resolution and doubles in size until reach the resolution that we want. And the noise mapping network injects into different blocks that progressively grow.
Adaptive Instance Normalization (AdaIN)
Now we will look at adaptive instance normalization or AdaIN for short and take a bit closer at how the intermediate noise vector is actually integrated into the network. So first, We will talk about instance normalization and we will compare it to batch normalization, which we are more familiar with. Then we will talk about what adaptive instance normalization means, and also where and why AdaIN or Adaptive Instance Normalization is used.
So we already talk about progressive growing, and we also learn about the noise mapping network, where it injects W into different blocks that progressively grow. Well, if you are familiar with ProGAN you know that in each block we up-sample and do two convolution layers to help learn additional features, but this is not all in the StyleGAN generator, we add AdaIN after each convolutional layer.
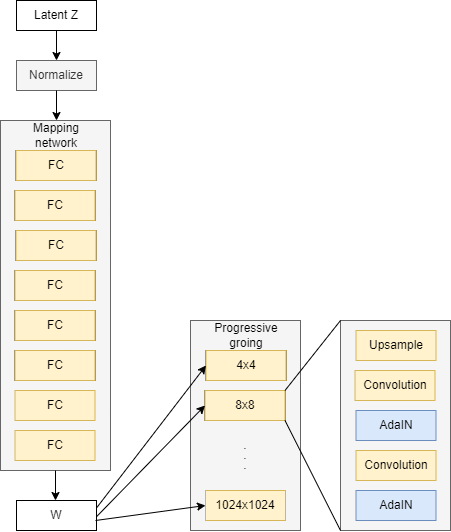
The first step of adaptive instance normalization(AdaIN) will be the instance normalization part. if you remember normalization is it takes the outputs from the convolutional layers X and puts it at a mean of 0 and a standard deviation of 1. But that's not it, because it's actually not based on the batch necessarily, which we might be more familiar with. Where batch norm we look across the height and width of the image, we look at one channel, so among RGB, we only look at R for example, and we look at all examples in the mini-batch. And then, we get the mean and standard deviation based on one channel in one batch. And then we also do it for the next batch. But instance normalization is a little bit different. we actually only look at one example or one instance(an example is also known as an instance). So if we had an image with channels RGB, we only look at B for example and get the mean and standard deviation only from that blue channel. Nothing else, no additional images at all, just getting the statistics from just that one channel, one instance. And normalizing those values based on their mean and standard deviation. The equation below represents that.
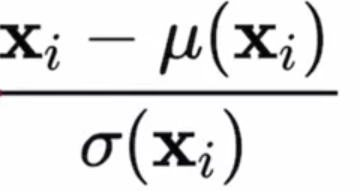
where:
Xi: Instance i from the outputs from the convolutional layers X.
µ(Xi): mean of instance Xi.
𝜎(Xi): Standard deviation of instance Xi.
So that's the instance normalization part. And where the adaptive part comes in is to apply adaptive styles to the normalized set of values. And the instance normalization probably makes a little bit more sense than nationalization, because it really is about every single sample we are generating, as opposed to necessarily the batch.
The adaptive styles are coming from the intermediate noise vector W which is inputted into multiple areas of the network. And so adaptive instance normalization is where W will come in, but actually not directly inputting there. Instead, it goes through learned parameters, such as two fully connected layers, and produces two parameters for us. One is ys which stands for scale, and the other is yb, which stands for bias, and these statistics are then imported into the AdaIN layers. See the formula below.
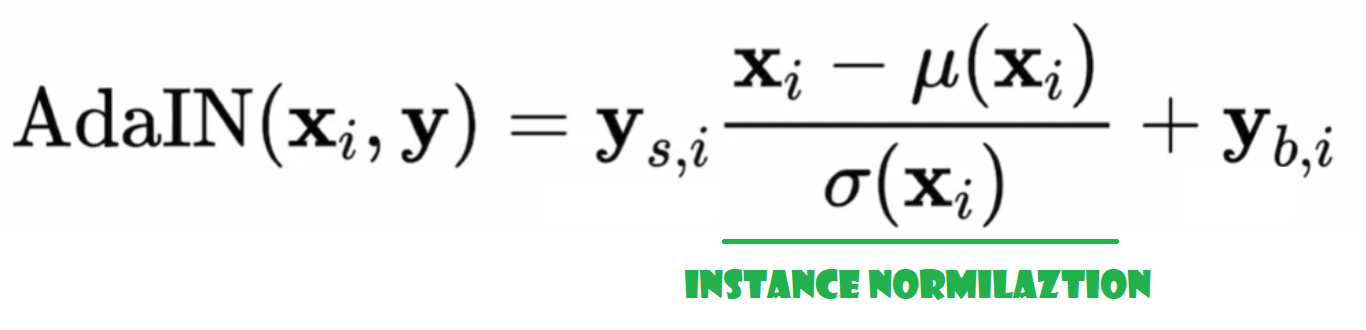
All the components that we see are fairly important to StyleGAN. Authors did ablation studies to several of them to understand essentially how useful they are by taking them out and seeing how the model does without them. And they found that every component is more or less necessary up.
Style mixing and Stochastic variation
In this section, we will learn about controlling coarse and fine styles with StyleGAN, using two different methods. The first is style mixing for increased diversity during training and inference, and this is mixing two different noise vectors that get inputted into the model. The second is adding stochastic noise for additional variation in our images. Adding small finer details, such as where a wisp of hair grows.
Style mixing
Although W is injected in multiple places in the network, it doesn't actually have to be the same W each time we can have multiple W's. We can sample a Z that goes through the mapping network, we get a W, its associated W1, and we injected that into the first half of the network for example. Remember that goes in through AdaIN. Then we sample another Z, let's name it Z2, and that gets us W2, and then we put that into the second half of the network for example. The switch-off between W1 and W2 can actually be at any point, it doesn't have to be exactly the middle for half and half the network. This can help us control what variation we like. The later the switch, the finer the features that we get from W2. This improves our diversity as well since our model is trained like this, so that is constantly mixing different styles and it can get more diverse outputs. The figure below is an example using generated human faces from StyleGAN.

Stochastic variation
Stochastic variations are used to output different generated images with one picture generated by adding an additional noise to the model.
In order to do that there are two simple steps:
- Sample noise from a normal distribution.
- Concatenate noise to the output of conv layer X before AdaIN.
The figure below is an example using generated human faces from StyleGAN. The author of StyleGAN generates two faces on the left(the baby at the bottom doesn't look very real. Not all outputs look super real) then they use stochastic variations to generate multiple different images from them, you can see the zoom-in into the person's pair that's generated, it's just so slight in terms of the arrangement of the person's hair.

Results



The images generated by StyleGAN have greater diversity, they are high-quality, high-resolution, and look so realistic that you would think they are real.
Conclusion
In this article, we go through the StyleGAN paper, which is based on ProGAN (They have the same discriminator architecture and different generator architecture).
The basic blocks of the generator are the progressive growing which essentially grows the generated output over time from smaller outputs to larger outputs. And then we have the noise mapping network which takes Z. That's sampled from a normal distribution and puts it through eight fully connected layers separated by sigmoids or some kind of activation. And to get the intermediate W noise vector that is then inputted into every single block of the generator twice. And then we learned about AdaIN, or adaptive instance normalization, which is used to take W and apply styles at various points in the network. We also learned about style mixing, which samples different Zs to get different Ws, which then puts different Ws at different points in the network. So we can have a W1 in the first half and a W2 in the second half. And then the generated output will be a mix of the two images that were generated by just W1 or just W2. And finally, we learned about stochastic noise, which informs small detail variations to the output.
Hopefully, you will be able to follow all of the steps and get a good understanding of StyleGAN, and you are ready to tackle the implementation, you can find it in this article where I make a clean, simple, and readable implementation of it to generate some fashion.










