
The best ML platform is typically a function of the platform's IDE, hardware, and cost. With these factors in mind, we'll be comparing Kaggle Notebooks and Paperspace's Gradient Notebooks.
In this guide our goal is to demonstrate where each platform excels and present clear arguments for when to use either product.
Paperspace Gradient Notebooks
Gradient is an MLOps platform designed to help users scale-up real world machine learning applications. Gradient Notebooks features a notebook workspace backed by Jupyter in which users can execute code cells. Notebooks are useful to process and run deep learning tasks on data uploaded directly to the working directory, uploaded to a Team Datasets volume and mounted in the notebook, or sourced from a mounted volume from one of the provided Public Datasets.
Kaggle Notebooks
Kaggle is a popular platform for users to find and publish data sets, create and test models in a data science environment, collaborate and communicate with other users through social media features, and enter competitions to solve data science challenges. Users can operate on IPython notebooks that run on the web-based platform and use Kaggle notebooks to execute code and markdown cells to work with the data uploaded by users to the platform. Kaggle notebooks also feature a console window if any commands need to be run outside of a notebook.
How are they similar overall?
Gradient Notebooks and Kaggle Notebooks share a number of functionalities. Users who are familiar with Jupyter Notebooks will be comfortable in both environments.
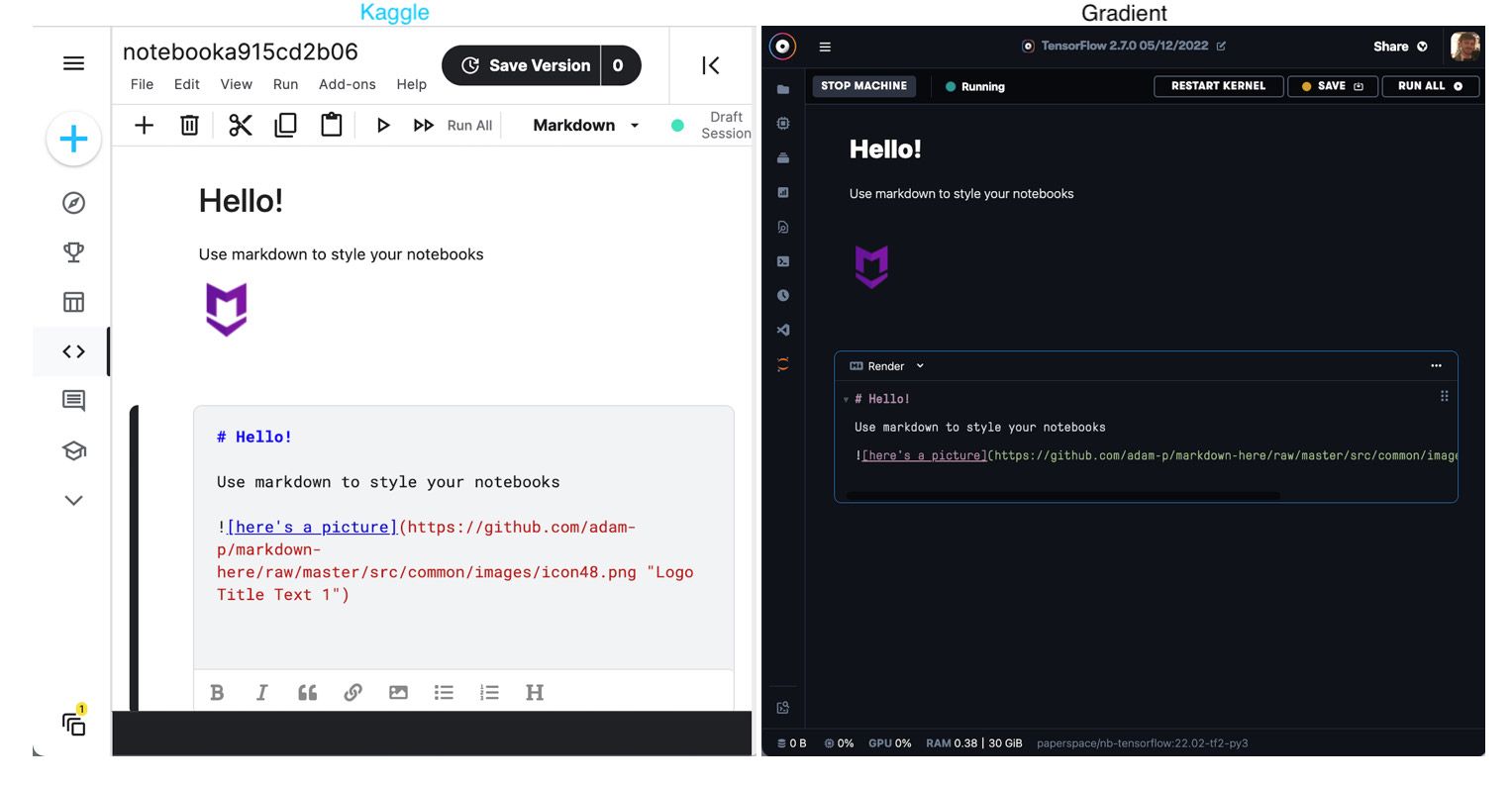
First, both IDEs allow the user to execute code and markdown cells. Markdown cells make it easy to provide contextual prose, labels, descriptive statements, and comments within notebooks while code cells enable execution of code within the notebook. This Jupyter-like behavior makes either platform ideal for exploration of data or experimentation with new models in a descriptive and repeatable manner.
Both platforms feature access to an interactive session running in a Docker container with pre-installed packages. This containerized session run allows users to start up a session with the desired packages. However the scope of customization of the container in use varies widely between the two IDEs. We will cover this in more detail below.
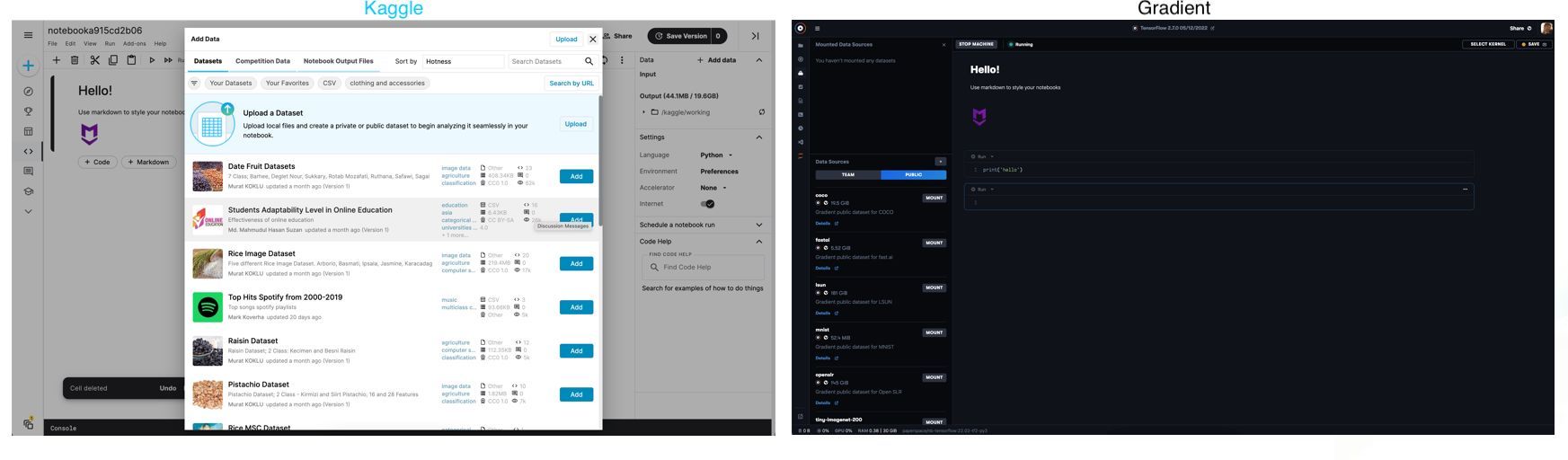
Each platform leverages the ability to mount versioned data sources and access them within the platform. This enables users to work with files uploaded to the host platform in a notebook via mounted volumes. Once again, the scope of capability varies widely here, but both platforms are capable of executing code on top of imported data.
Finally, each platform enables the user to access customizable compute resources like GPUs – however Kaggle and Gradient handle GPU hardware allocation and availability differently, with Gradient providing more options and higher-end hardware. We'll cover these and other differences in detail below.
Contrasting Kaggle Notebooks and Gradient Notebooks
Hardware
| Kaggle | Gradient | |
|---|---|---|
| GPU | Yes, P100 | Yes, M4000, P4000, RTX4000, A4000, P5000, RTX5000, A5000, A6000, V100 - 16GB, V100 - 32GB, A100 - 40GB, A100 - 80GB |
| TPU | Yes | No |
| CPU | Yes | Yes |
Machine variety & capability
Kaggle Notebooks have the ability to run with either a CPU, GPU, or TPU-powered instance, whereas Gradient only has options with CPU or GPU machines. If you value TPUs, Kaggle is a better choice. However, if you value having more choices for CPU and GPU hardware, Gradient is a better choice.
Kaggle offers only the P100 GPU which is a Pascal series GPU that is now two generations old. The P100 will pale in efficacy compared to the V100 and A100 instances offered on Gradient, although these GPUs are not available except via subscription on Gradient.
TPUs are an AI ASIC developed by Google to accelerate computation with tensors for deep learning applications. This is primarily meant to be used in tandem with the deep learning library TensorFlow, and the software and hardware were developed to optimize use with one another.
Gradient's full list of available GPUs and their benchmarks can be found in these links.
Machine selection
One of the biggest factors working against Kaggle is machine selection. As we all know, the ability to complete deep learning tasks within a given timeframe is dependent on the hardware as well as the operator.
With Kaggle there is no option to select a different machine type. This is not a problem in for most hobbyists, students, and enthusiasts on the platform. The P100 is adequate for many deep learning tasks. However the P100 is not capable of dealing with many of the larger data problems that are becoming more prevalent as the field of deep learning grows. Enterprise-level users will quickly find the P100 is insufficient, and this effect is only compounded by the 30-hour limit on GPU notebooks on Kaggle.
Gradient does not have this problem. On all Paperspace Core and Gradient instances, users have access to a wide variety of Maxwell, Pascal, Volta, Turing, and Ampere GPUs at varying costs. This enables users to have far more control over how much data is being used and how quickly a deep learning algorithm can process that data on Gradient.
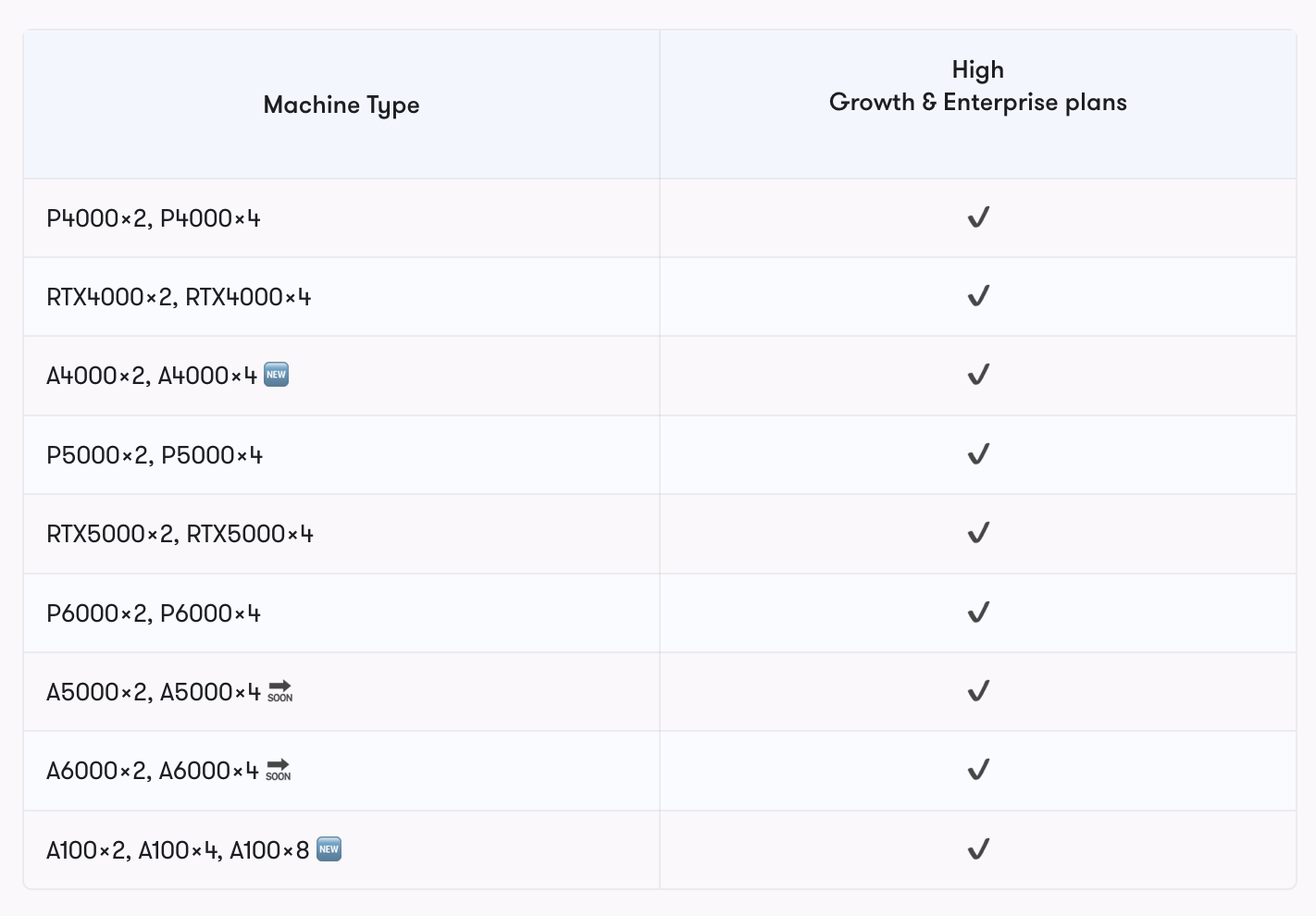
Furthermore, Gradient has multi-GPU instances that can enable entire libraries and parallelization paradigms unavailable to Kaggle users, like Arise or DeepMind.
Interface
The Gradient Notebooks IDE and Kaggle Notebook interface are more similar than they are different thanks to a shared heritage with Jupyter, but there are notable differences.
Both platforms are excellent environments to compile Python or R code, have a full editor and console available, and can run code via .ipynb files and .py scripts. While they are both robust environments for coding, their main differences are actually related to quality of experience for the user. These differences namely lie in terms of additional features: metrics, logging, and customization.
In Kaggle, it can be difficult to surface information about what's happening in your code. This is a two-fold problem for logging and getting various metrics about your instance. You would need to set up your own proprietary logging application to record the actions being taken on the notebook or find error code, and it often requires third-party applications to discern metrics about the machine itself like memory consumption or temperature. Fortunately, these things are made easy with Gradient. Simply use the buttons on the lefthand side of any notebook to access logging, metrics, version history and a lot more.
Other Features
In this section we will look at a number of other features that differentiate the two platforms.
Github integration
While Kaggle has an API and a popular Github action to push dataset kernels, it currently lacks any further integration with Github. This is reasonable; Kaggle notebooks are largely designed for quick experimentation on a toy dataset, and not a workspace for iterating on a Github repo.
Gradient, however, features robust integration with Github in order to give users the ability to manage their Notebook workspace and update repos with Workflows. By integrating the Gradient account with the Github Gradient application, Gradient can be used to iteratively update repositories as work is done with Gradient Workflows. This, in effect, allows the user to version-control code during the application development process, and ensure that any colleagues and collaborators will have the best possible experience. On a lower level of integration, Gradient also features the ability to use a Github URL as the workspace URL for Notebook creation. By doing so, users can customize the starting files available in their Notebook.
S3 datasets
Access to different storage locations and types can be situationally important to ML ops platform users. On Kaggle, this is handled entirely within the Kaggle ecosystem, and this cannot be changed. On Gradient however, users have the option of storing data on Gradient Managed or connecting to an S3 bucket. Through a few steps of configuration, any Gradient user can connect an S3 bucket directly to their account. This will allow the user to set their own limits for data storage, and overcome any limitations or overage fees that a user may incur over the limit of Gradient Managed storage. For any user who desires to work with Big Data, this can be a must.
Runtime limits
Kaggle Notebook can only be used to execute code for 12 hours execution time for CPU and GPU notebook sessions and 9 hours for TPU notebook sessions. Furthermore, there is a limitation of 30 hours of total GPU and 20 hours of total TPU time allowed per week, per user. This limitation cannot be overcome, and all users must follow it.
In Gradient Notebooks on the other hand, the only Notebooks with set time limitations are the free GPU Notebooks. These can only be run for a maximum of 6 hours on the free tier. Users can, however, pay for access to GPUs for Gradient Notebooks that range from multiple hours to days to no set time limit to run. This makes Gradient far more preferable whenever you have a computationally expensive or long training task to complete.
Public & Team Datasets
Kaggle's greatest feature is the access it gives to the massive store of user submitted and curated datasets. Within Kaggle Notebooks, users can easily access immutable versions of these datasets for use with their code, and these can be updated with the Kaggle API. For this reason, the Kaggle catalog is also a very common place for new data scientists to visit to begin work on toy projects.
Gradient also give the user access to a selection of Public Datasets, which contain a growing repository of popular machine and deep learning datasets. These are much more limited than Kaggle datasets at the moment, but they allow the user to near instantly mount the data onto a Notebook, and includes popular large datasets like MS-COCO. Users also have the ability to upload and use their own data through Team Datasets.
All in all, while Kaggle is currently the superior option for quick access to data within the platform, Gradient is rapidly approaching the same level of viability of users through its datasets features. The advantage of Kaggle datasets is also heavily hindered by their API, as it makes it easy for any user to download any Kaggle dataset in a very short time on Paperspace data center internet speeds.
Conclusion
In this blogpost, we attempted to breakdown the differences between Kaggle and Gradient. We've attempted to show how Kaggle is an ideal starting spot for students and hobbyists thanks to its simplistic IDE, data sharing tools, and lack of jargony customization options. Meanwhile, we have also shown that Gradient offers much of that same functionality with the additions of enterprise level scalability, quality of life improvements over Jupyter, and deployment capability.
For these reasons, we recommend only earliest career users and those with a need to use a TPU work with Kaggle Notebooks. Gradient should be the first choice for enterprise level users, and also has strong arguments as the first choice for any user seeking to conduct deep learning.











