
Bring this project to life

Introduction
The Segment Anything task involves image segmentation by generating a segmentation mask effectively based on diverse prompts. These prompts can take various forms, including foreground/background point sets, approximate boxes or masks, free-form text, or any information indicating the content to be segmented within an image. Image segmentation stands as a crucial task in computer vision, playing a pivotal role in extracting valuable information from images. One of the key benefits of image segmentation is extracting crucial information from an image which consists of multiple objects. Dividing an image into multiple segments makes it easier to analyze each segment individually. This helps computer vision algorithms analyze individual segments of an image, allowing the identification and tracking of specific objects in image or video streams. Image segmentation finds its applications in diverse fields, such as medical imaging, autonomous vehicles, robotics, agriculture, and gaming.
The Segment Anything Model (SAM) has had a notable impact on various computer vision tasks, serving as a new, foundational model for tasks such as image segmentation, captioning, and editing. Despite its significance, the model requires substantial computation costs, particularly because of the Vision Transformer architecture (ViT) at high resolutions. The recent paper Fast Segment Anything by Xu Zhao et al., 2023 introduces an alternative method aimed at achieving this crucial task while maintaining low computation cost.
In this blog post we will discuss this revolutionary method: FastSAM, a real-time CNN-based solution for the Segment Anything task. The main objective of this method is to segment any object within an image using various potential prompts initiated by user interaction.
Fast Segment Anything Model (FastSAM)
In contrast to convolutional counterparts, Vision Transformers (ViTs) are notable for their high demands on computational resources. This poses a challenge to their practical deployment, particularly in real-time applications, limiting their potential impact on advancing the segment anything task. SAM has been regarded as the milestone vision foundation model. The model has been trained on the SA-1B dataset, which gives the ability to handle a wide range of scenes and objects. However, due to the transformer architecture causes a limitation to its usage.
FastSAM makes use of the computational efficiency of Convolutional Neural Networks (CNNs), to illustrate that it is possible to achieve a real-time model for segmenting anything without significantly compromising performance quality.
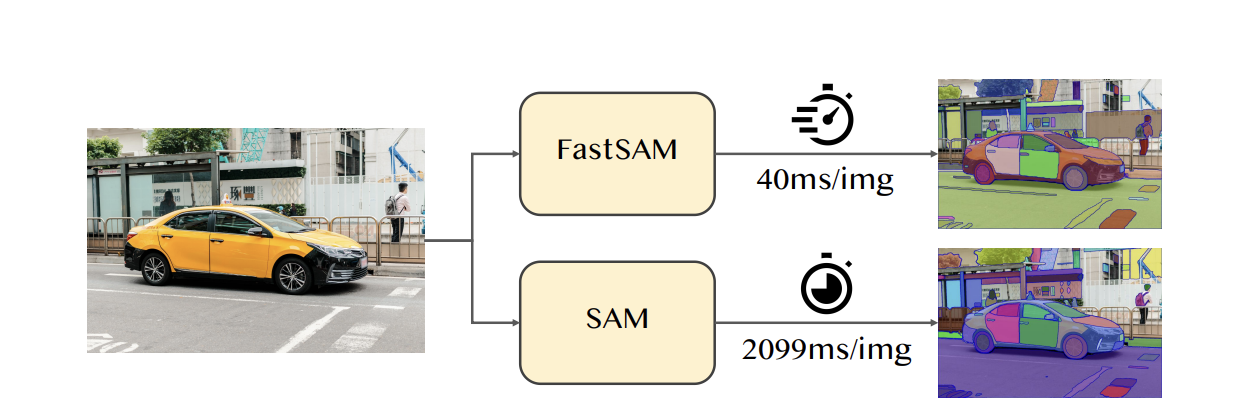
FastSAM is built upon YOLOv8-seg, from longtime Paperspace friend Ultralytics, an object detector with an instance segmentation branch based on the YOLACT method. By utilizing only 2% of the SA-1B dataset, FastSAM has achieved a comparable performance to SAM at significantly lower computational demands, allowing for applications to run in real-time. The model is applied to various segmentation tasks, demonstrating its generalization.
FastSAM aims to overcome the constraints of the SAM, known for its demanding computational resources due to its extensive Transformer architecture. FastSAM takes a different approach by breaking down the segment anything task into two consecutive stages: the first stage employs YOLOv8-seg to generate segmentation masks for all instances in the image, and the second stage outputs the region-of-interest corresponding to the given prompt through prompt-guided selection.
Overview
The approach comprises of two stages: the All-instance Segmentation serves as the foundation, while the Prompt-guided Selection is essentially task-oriented post-processing.
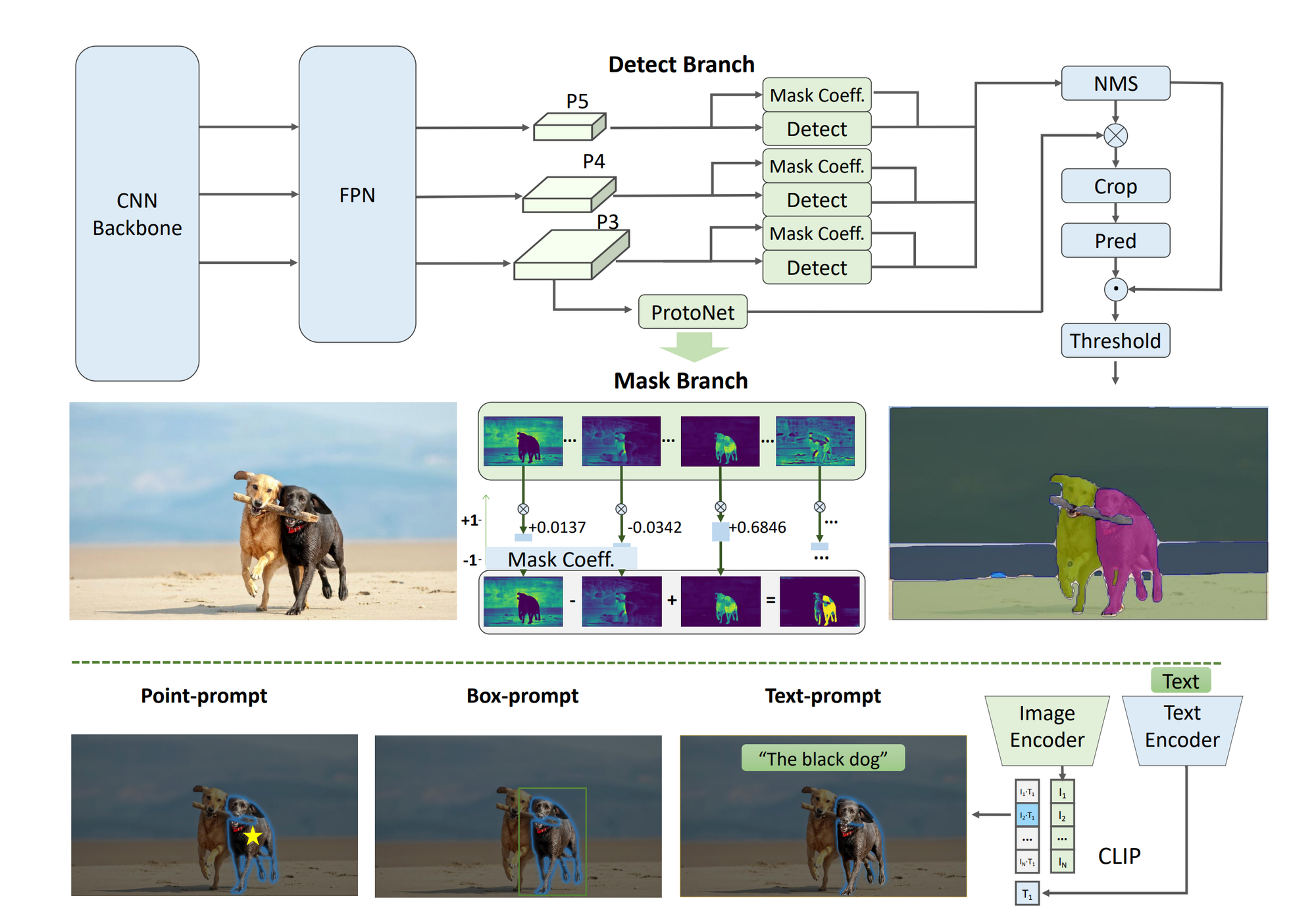
All-instance Segmentation
The output comprises of the detection and segmentation branches. The detection branch of the model produces category labels and bounding boxes, while the segmentation branch generates k prototypes (defaulted to 32 in FastSAM) along with corresponding mask coefficients. Both segmentation and detection tasks are executed simultaneously. The segmentation branch takes a high-resolution feature map, maintaining spatial details and semantic information. After processing through convolution layers, upscaling, and additional convolution layers, it outputs the masks. Mask coefficients, similar to the detection branch's classification branch, range from -1 to 1. The final instance segmentation result is obtained by multiplying the mask coefficients with the prototypes and summing them up. In FastSAM, YOLOv8-seg method is used for the all-instance segmentation.

Prompt-guided Selection
With the successful segmentation of all objects or regions in an image with YOLOv8, the second stage of the segment anything task involves employing different prompts to pinpoint the specific object(s) of interest.

The point prompt method involves matching selected points to masks obtained in the initial phase, aiming to identify the mask containing the given point.
In the box prompt method, Intersection over Union (IoU) matching is performed between the selected box and bounding boxes associated with masks from the initial phase. The objective is to identify the mask with the highest IoU score relative to the selected box, effectively choosing the object of interest.
In the case of text prompt, the text embeddings of the text are extracted using the CLIP model. The image embeddings are individually determined and compared to the intrinsic features of each mask using a similarity metric. The mask exhibiting the highest similarity score to the image embeddings of the text prompt is subsequently chosen.
By carefully implementing these techniques, the FastSAM can efficiently select specific objects or regions of interest from a segmented image.
Paperspace Demo
Bring this project to life
To run this demo on Paperspace we will first start, Paperspace Notebook with a GPU of your choice. We can use the link above or at the top of this article to quickly open the project up on Paperspace. Please note this link will spin up a free GPU (M4000). However, the Growth and Pro plan users may want to consider switching to a more powerful machine type. We can edit the machine choice in the URL where it says "Free-GPU" by replacing that value with another GPU code from our machine selection. Once the web page has loaded, click "Start Machine" to begin launching the Notebook.
- Clone the repo using the below code:
!git clone https://github.com/CASIA-IVA-Lab/FastSAM.git- Once the repo is successfully cloned use pip to install the necessary libraries and install CLIP:
!pip install -r FastSAM/requirements.txt
!pip install git+https://github.com/openai/CLIP.git- Download the image from web to use it for image segmentation. Please feel free to use any image url.
!wget -P images https://mediaproxy.salon.com/width/1200/https://media.salon.com/2021/01/cat-and-person-0111211.jpg- Next, lines of code will help display the image in the notebook:
import matplotlib.pyplot as plt
import cv2
image = cv2.imread('images/cat-and-person-0111211.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
original_h = image.shape[0]
original_w = image.shape[1]
print(original_w, original_h)
plt.figure(figsize=(10, 10))
plt.imshow(image)- Next, run the scripts to try the everything mode and three prompt modes.
# Everything mode
!python FastSAM/Inference.py --model_path FastSAM.pt --img_path ./images/dog.jpg
# Text prompt
!python FastSAM/Inference.py --model_path FastSAM.pt --img_path ./images/cat-and-person-0111211.jpg --text_prompt "the cat"!# Box prompt(xywh)
!python FastSAM/Inference.py --model_path FastSAM.pt --img_path ./images/cat-and-person-0111211.jpg --box_prompt "[[570,200,230,400]]"
# points prompt
!python FastSAM/Inference.py --model_path FastSAM.pt --img_path ./images/cat-and-person-0111211.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
A user interface using Gradio for testing the method is also provided. Users can upload their own images, choose the mode, adjust parameters, click the segment button, and receive a satisfactory segmentation result.
# gradio demo
!python app_gradio.pyKey Points
- FastSAM achieves 63.7 at AR1000, that is 1.2 points higher than SAM with 32× 32 point-prompt inputs. Can run on consumer graphics cards.
- The model has proven to be valuable for many industrial applications. This approach is versatile and applicable across numerous scenarios. It not only offers a novel and effective solution for various vision tasks but does so at an exceptional speed, surpassing current methods by tens or hundreds of times.
- The model also offers a new view for the large model architecture for the general vision tasks.
- FastSAM significantly reduce the computational power required for SAM while maintaining competitive performance. A comparative assessment across various benchmarks between the FastSAM and SAM offers valuable insights into the strengths and weaknesses of each approach within the segment anything domain.
- This research marks the novel exploration of employing a CNN detector for the segment anything task, providing valuable insights into the capabilities of lightweight CNN models in handling intricate vision tasks.
- FastSAM outperforms SAM across all prompt numbers, and notably, the running speed of FastSAM remains consistent regardless of the number of prompts. This characteristic makes it a preferable choice, especially for the Everything mode.
Concluding Thoughts
This article assesses FastSAM's performance in object segmentation, presenting visualizations of its segmentation using point-prompt, box-prompt, and everything modes. We strongly encourage our readers to refer to the research paper for a detailed examination of the comparison between FastSAM and SAM.
FastSAM effectively segments objects using text prompts, but the text-to-mask segmentation speed is unsatisfactory due to the need to input each mask region into the CLIP feature extractor, as mentioned in the research paper. Integrating the CLIP embedding extractor into FastSAM's backbone network is still a challenging task related to model compression. There are still some drawbacks with FastSAM which can be improved further.
Nevertheless, FastSAM has proven to achieve comparable performance with SAM, making it an amazing choice for real-world applications. We recommend our readers to try this model on Paperspace platform and explore more.
Thanks for reading, we hope you enjoy the model with Paperspace!










