
In this article, you will read about the relevance of sentence embeddings in the NLP world, and learn how to use it with PyTorch's lightning-flash; a fast and efficient tool that helps you to easily build and scale AI models.
In this article we'll briefly cover the following:
- Cosine Similarity between two vectors
- Word Embeddings vs Sentence Embeddings
- The sentence transformers API
- The PyTorch Lightning framework
Cosine Similarity between two vectors
Imagine that you have two vectors, each with a distinct direction and a magnitude. You would easily be able to compute the similarity between the vectors by taking the cosine of the angle between the vectors if this was real-world physics. In the context of computer science, the vectors would be a representation that consists of an array, of integer or float values. To compute the similarity between such an array, we can use the cosine similarity metric.
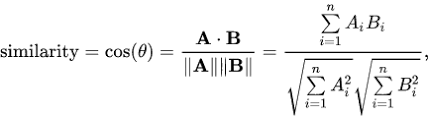
The output is a similarity score ranging between 0 and 1. Here is a sample python function where you have two vectors x and y as input that returns the cosine similarity score of the input as a result.
import numpy as np
def cos_sim(x, y):
"""
input: Two numpy arrays, x and y
output: similarity score range between 0 and 1
""""
#Taking dot product for obtaining the numerator
numerator = np.dot(x, y)
#Taking root of squared sum of x and y
x_normalised = np.sqrt(np.sum(x**2))
y_normalised = np.sqrt(np.sum(y**2))
denominator = x_normalised * y_normalised
cosine_similarity = numerator / denominator
return cosine_similarity
Word Embeddings vs Sentence Embeddings
The domain of NLP has benefitted a lot from the advent of word-embeddings. The usage of word-embeddings in solving NLP problems has helped better contextual understanding of the natural language and facilitated its use for various supervised and unsupervised tasks.
A word embedding is defined as a fixed size vector for a word, so that each word in a language can be better represented according to the semantic context in a natural language space. This representation allows word embeddings to be used for tasks like mathematical computations, training a neural network, etc. Word2Vec and Glove are two of the most popular early word embedding models.
Later, when BERT-based models got popular along with the Huggingface API, the standard for contextual understanding rose even higher. But this also led to another issue in the form of scaling. The speed of computation changed drastically as BERT-based models provided more complex vectors. Also, a wider understanding of the whole sentence in the form of vector representation was proven more useful in tasks where the understanding of intention of a sentence was necessary. An example of one such task is sentence similarity (STS), where the goal is to predict if two sentences are semantically similar to each other. When the two sentences are fed into the complex neural network model that BERT provides, there is an immense computational overload. It was found that one such task with a dataset of 10,000 sentence pairs would require close to 65 hours of time, due to it requiring approximately 50 million inference computations (Source). This would be a major drawback when scaling deep learning models for STS and other unsupervised tasks like clustering. Let's see an example code as to how a BERT-based word embedding model from Huggingface can solve an STS task:
from transformers import BertTokenizer, TFBertModel
model_name="prajjwal1/bert-small"
tokenizer=BertTokenizer.from_pretrained(model_name)
model = TFBertModel.from_pretrained(model_name,from_pt=True)
def encode_sentences(sentences):
encoded = tokenizer.batch_encode_plus(
[sentences],
max_length=512,
pad_to_max_length=False,
return_tensors="tf",
)
input_ids = np.array(encoded["input_ids"], dtype="int32")
output = model(
input_ids
)
sequence_output, pooled_output = output[:2]
return pooled_output[0]
sentence1="There is a cat playing with a ball"
sentence2="Can you see a cat with a ball over the fence?"
embed1=encode_sentences(sentence1)
embed2=encode_sentences(sentence2)
cosine_similarity= cos_sim(embed1,embed2)
print("Cosine similarity Score {}".format(cosine_similarity))Sentence Transformers comes to the rescue here by providing an easy-to-use API for generating meaningful sentence embeddings for the input, in such a way that the relationship between two sentence pairs can be easily computed by common metrics such as cosine similarity. A Sentence Transformers-based BERT embedding can bring down the time for the similar task mentioned above from 65 hours to just 5 seconds. Apart from STS tasks, these embeddings have also proven useful for other tasks, such as natural language inference(NLI), next sentence prediction, etc.
Bring this project to life
The Sentence Transformers API
Sentence Transformers is a Python API where sentence embeddings from over 100 languages are available. The code is well optimized for fast computation. Different metrics are also available in the API to compute and find similar sentences, do paraphrase mining, and also help in semantic search.
Let's take a look at how encoding sentences in sentence transformers API looks, and also calculate the cosine similarity between pairs of sentences using its built-in API to calculate such metrics.
Before we begin, we need to install the package from pip:
pip install sentence_transformers
Now let's code:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2') #using a relatively smaller size model from the api
#two columns with indexes corresponding to pairs
col1=["I like to watch tv","The cat was running after the butterfly"]
col2=["Watching Television is my favorite time pass","It is so windy today"]
#Compute encodings for both lists
vectors1 = model.encode(col1, convert_to_tensor=True)
vectors2 = model.encode(col2, convert_to_tensor=True)
#Computing the cosine similarity for every pair
cosine_scores = util.cos_sim(vectors1, vectors2)
#Display cosine similarity score for the computed embeddings
for i,(sent1,sent2) in enumerate(zip(col1,col2)):
if cosine_scores[i][i]>=0.5:
label="Similar"
else:
label="Not Similar"
print("sentence 1:{} | sentence 2:{}| prediction: {}".format(sent1,sent2,label))
Output:
sentence 1:I like to watch tv | sentence 2:Watching Television is my favorite time pass| prediction: Similar
sentence1:The cat was running after the butterfly | sentence 2:It is so windy today| prediction: Not Similar
As you can see from the output, the sentence transformers API is capable of quickly and accurately assessing the similarity between the example strings, with the first, rightly, being declared similar and the second correctly being declared not similar.
The Pytorch-lightning Framework
So far, we've been looked at how to write code to compute sentence similarity. But when it comes to scaling a model or using it in production, writing notebook-style code is often not enough. If you're using PyTorch, you will be handling a training loop, a validation loop, a test loop, optimizers, and other configurations. Pytorch-lightning saves all that hassle for you by simply providing a framework that can easily wrap all such modules in a scalable, easy-to-use way.
Let's familiarize ourselves with a few more concepts and toolkits used on top of the lightning module, to understand further how to play with our text data.
Datamodule
The Datamodule fetches the data from a cloud/local storage, applies other preprocessing/transforms like cleaning, tokenizing, etc, and wraps it inside a DataLoader object. This helps create organized management for the data, rather than reading and preprocessing data spread across several files or locations. The Dataloader also helps split the data into train test and validation.
Trainer
The Trainer helps you automate the pipeline with the necessary features required for training. This means handling the entire training loop, managing the hyperparameters, loading the models and dataloaders, handling batches and callbacks, predicting from the given test data, and finally saving the model checkpoint. The trainer abstracts all these aspects for you without any additional PyTorch code.
Bring this project to life
Lightning-flash
As AI rises to the challenge of working in each domain, and different frameworks are popping up every day, at some point in time we might have wished for it all to be together available in one framework. That is essentially what lightning-flash aims to do.
Flash is a sub-project delivered to you by the PyTorch Lightning team, as a one-stop toolkit for most of your machine learning problems. Flash wraps its task in a lightning module, with the appropriate usage of Trainer and Datamodule to leverage every feature PyTorch has to offer. A few popular domains and tasks that can be analyzed in this way include audio, text, images, graphs, structured data, etc.
Let's try out a text classification example from lightning-flash to review the above concepts, Trainer and Dataloader, and their implementation. The training data is obtained from the Spam text message classification task from Kaggle.
It will come pre-uploaded to your Gradient instance, along with the notebook and Python scripts needed to run this demo, if you input this Github link as your Workspace URL while creating the Notebook. You can also access and fork the public version of this notebook through that link.
import torch
import flash
from flash.text import TextClassificationData, TextClassifier
#using the SPAM text message classification from kaggle: https://www.kaggle.com/team-ai/spam-text-message-classification
datamodule = TextClassificationData.from_csv(
"Message", #source column
"Category", #target column : The data does not even need to be integer encoded!
train_file="/content/SPAM text message 20170820 - Data.csv",
batch_size=8,
)
# The Model is loaded with a huggingface backbone
model = TextClassifier(backbone="prajjwal1/bert-small", num_classes=datamodule.num_classes)
# A trainer object is created with the help of pytorch-lightning module and the task is finetuned
trainer = flash.Trainer(max_epochs=2, gpus = 1)
trainer.finetune(model, datamodule=datamodule, strategy="freeze")
# few data for predictions
datamodule = TextClassificationData.from_lists(
predict_data=[
"Can you spill the secret?",
"Camera - You are awarded a SiPix Digital Camera! call 09061221066 fromm landline. Delivery within 28 days.",
"How are you? We have reached India.",
],
batch_size=8,
)
predictions = trainer.predict(model, datamodule=datamodule)
print(predictions)
# >>>[['ham', 'spam', 'ham']]
# Finally, we save the model
trainer.save_checkpoint("spam_classification.pt")The above example shows a downstream task where the model is fine-tuned on the given spam vs. ham data. When it comes to using sentence embeddings, we do not require fine-tuning when it comes to tasks related to sentence similarity, i.e the sentence embeddings generated can be directly used with the metrics from the sentence transformers API to easily compute the similarity.
Let's look at an example of how lightning-flash helps us compute sentence embeddings, and attempt to solve a sentence similarity task without actually needing to fine-tune on a downstream task and use unsupervised methods.
import torch
import flash
from flash.text import TextClassificationData, TextEmbedder
from sentence_transformers import util
predict_data=["I like to watch tv","Watching Television is my favorite time pass","The cat was running after the butterfly","It is so windy today"]
# Wrapping the prediction data inside a datamodule
datamodule = TextClassificationData.from_lists(
predict_data=predict_data,
batch_size=8,
)
# We are loading a pre-trained SentenceEmbedder
model = TextEmbedder(backbone="sentence-transformers/all-MiniLM-L6-v2")
trainer = flash.Trainer(gpus=1)
#Since this task is tackled unsupervised, the predict method generates sentence embeddings using the prediction input
embeddings = trainer.predict(model, datamodule=datamodule)
for i in range(0,len(predict_data),2):
embed1,embed2=embeddings[0][i],embeddings[0][i+1]
# we are using cosine similarity to compute the similarity score
cosine_scores = util.cos_sim(embed1, embed2)
if cosine_scores>=0.5:
label="Similar"
else:
label="Not Similar"
print("sentence 1:{} | sentence 2:{}| prediction: {}".format(predict_data[i],predict_data[i+1],label))
As you can see, we do not need to fine-tune like in the previous text classification task. Lightning-flash's capabilities will help input the data through the Datamodule and generate the embeddings with the help of the predict method from the Trainer object.
Conclusion
In this article, we've covered the basics of Sentence transformers and solving sentence similarity problems using sentence transformers. We also evaluated the advantage of sentence embeddings over word embeddings for such tasks. By going through examples of pytorch-lightning's implementation of sentence transformers, we learned to scale the code for production-ready applications, and we can now simplify the pipeline required to write a PyTorch training loop by avoiding the boilerplate code.











