PyGAD is an open-source Python library for building the genetic algorithm and training machine learning algorithms. It offers a wide range of parameters to customize the genetic algorithm to work with different types of problems.
PyGAD has its own modules that support building and training neural networks (NNs) and convolutional neural networks (CNNs). Despite these modules working well, they are implemented in Python without any additional optimization measures. This leads to comparatively high computational times for even simple problems.
The latest PyGAD version, 2.8.0 (released on 20 September 2020), supports a new module to train Keras models. Even though Keras is built in Python, it's fast. The reason is that Keras uses TensorFlow as a backend, and TensorFlow is highly optimized.
This tutorial discusses how to train Keras models using PyGAD. The discussion includes building Keras models using either the Sequential Model or the Functional API, building an initial population of Keras model parameters, creating an appropriate fitness function, and more.
You can also follow along with the code in this tutorial and run it for free on a Gradient Community Notebook from the ML Showcase. The full tutorial outline is as follows:
- Getting started with PyGAD
pygad.kerasgamodule- Steps to train a Keras model using PyGAD
- Determining the problem type
- Creating a Keras model
- Instantiating the
pygad.kerasga.KerasGAclass - Preparing the training data
- Loss function
- Fitness function
- Generation callback function (optional)
- Creating an instance of the
pygad.GAclass - Running the genetic algorithm
- Fitness vs. generation plot
- Statistics about the trained model
- Complete code for regression
- Complete code for classification using a CNN
Let's get started.
Bring this project to life
Getting Started With PyGAD
To start this tutorial, it is essential to install PyGAD. If you already have PyGAD installed, check the __version__ attribute to make sure that at least PyGAD 2.8.0 is installed.
import pygad
print(pygad.__version__)PyGAD is available on PyPI (Python Package Index), and can be installed using the pip installer. If you don't already have PyGAD installed make sure to install PyGAD 2.8.0 or higher.
pip install pygad>=2.8.0You can find the PyGAD documentation on Read the Docs, including some sample problems. Below is an example of how to solve a simple problem, namely optimizing the parameters of a linear model.
import pygad
import numpy
function_inputs = [4,-2,3.5,5,-11,-4.7]
desired_output = 44
def fitness_func(solution, solution_idx):
output = numpy.sum(solution*function_inputs)
fitness = 1.0 / (numpy.abs(output - desired_output) + 0.000001)
return fitness
num_generations = 100
num_parents_mating = 10
sol_per_pop = 20
num_genes = len(function_inputs)
ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
fitness_func=fitness_func,
sol_per_pop=sol_per_pop,
num_genes=num_genes)
ga_instance.run()
ga_instance.plot_result()pygad.kerasga Module
Starting from PyGAD 2.8.0, a new module named kerasga was introduced. Its name is short for Keras Genetic Algorithm. The module offers the following functions:
- Build the initial population of solutions using the
KerasGAclass. Each solution holds all the parameters for the Keras model. - Represent the Keras model's parameters as a chromosome (i.e. 1-D vector) using the
model_weights_as_vector()function. - Restore the Keras model's parameters from the chromosome using the
model_weights_as_matrix()function.
The pygad.kerasga module has a class named KerasGA. The constructor of this class accepts two parameters:
model: The Keras model.num_solutions: The number of solutions in the population.
Based on these two parameters, the pygad.kerasga.KerasGA class creates 3 instance attributes:
model: A reference to the Keras model.num_solutions: Number of solutions in the population.population_weights: A nested list holding the model parameters. This list is updated after each generation.
Assuming the Keras model is saved into the model variable, the code below creates an instance of the KerasGA class and saves it into the keras_ga variable. The num_solutions argument is assigned the value 10, which means the population has 10 solutions.
The constructor creates a list of length equal to the value of the num_solutions argument. Each element in the list holds different values for the model's parameters after being converted into a 1-D vector using the model_weights_as_vector() function.
Based on the instance of the KerasGA class, the initial population can be returned from the population_weights attribute. Assuming the model has 60 parameters and there are 10 solutions, then the shape of the initial population is 10x60.
import pygad.kerasga
keras_ga = pygad.kerasga.KerasGA(model=model,
num_solutions=10)
initial_population = keras_ga.population_weightsThe next section summarizes the steps to train a Keras model using PyGAD. Each of these steps will be discussed in more detail further on.
Steps to Train a Keras Model Using PyGAD
The steps to train a Keras model using PyGAD are summarized as follows:
- Determining the Problem Type
- Creating a Keras Model
- Instantiating the
pygad.kerasga.KerasGAClass - Preparing the Training Data
- Loss Function
- Fitness Function
- Generation Callback Function (Optional)
- Creating an Instance of the
pygad.GAClass - Running the Genetic Algorithm
The next sections discuss each of these steps.
Determining the Problem Type
The problem type (either classification or regression) helps to determine the following:
- Loss function (which is used to build the fitness function)
- Output layer in the Keras model
- Training data
For a regression problem, the loss function could be the mean absolute error, mean squared error, or another function as listed here.
For a classification problem, the loss function can be binary cross-entropy (for binary classification), categorical cross-entropy (for multi-class problems), or another function as listed on this page.
The activation function in the output layer differs based on whether the problem is classification or regression. For a classification problem it might be softmax, compared to linear for regression.
As for the output, for a regression problem the output will be a continuous function, compared to a class label for classification problems.
In summary, it's critical to determine the type of problem beforehand so that the training data and loss function are selected properly.
Creating a Keras Model
There are 3 ways to build a Keras model:
PyGAD supports building a Keras model using both the Sequential Model and Functional API.
Sequential Model
To create a Sequential Model using Keras, simply create each layer using the tensorflow.keras.layers module. Then create an instance of the tensorflow.keras.Sequential class. Finally, use the add() method to add the layers to the model.
import tensorflow.keras
input_layer = tensorflow.keras.layers.Input(3)
dense_layer1 = tensorflow.keras.layers.Dense(5, activation="relu")
output_layer = tensorflow.keras.layers.Dense(1, activation="linear")
model = tensorflow.keras.Sequential()
model.add(input_layer)
model.add(dense_layer1)
model.add(output_layer)Note that the output layer's activation function is linear, which means that this is for a regression problem. For a classification problem the activation function could be softmax. In the next line the output layer has 2 neurons (1 for each class) and uses the softmax activation function.
output_layer = tensorflow.keras.layers.Dense(2, activation="linear")Functional API
For the Functional API case, each layer is created normally (the same way we saw above, when creating a Sequential Model). Except for the input layer, each subsequent layer is used as a function that accepts the preceding layer as an argument. Finally an instance of the tensorflow.keras.Model class is created, which accepts the input and output layers as arguments.
input_layer = tensorflow.keras.layers.Input(3)
dense_layer1 = tensorflow.keras.layers.Dense(5, activation="relu")(input_layer)
output_layer = tensorflow.keras.layers.Dense(1, activation="linear")(dense_layer1)
model = tensorflow.keras.Model(inputs=input_layer, outputs=output_layer)After the Keras model is created, the next step is to create an initial population of Keras model parameters using the KerasGA class.
Instantiate The pygad.kerasga.KerasGA Class
By creating an instance of the pygad.kerasga.KerasGA class, an initial population of the Keras model's parameters is created. The next code passes the Keras model created in the previous section to the model argument of the KerasGA class constructor.
import pygad.kerasga
keras_ga = pygad.kerasga.KerasGA(model=model,
num_solutions=10)The next section creates the training data used to train the Keras model.
Prepare The Training Data
Based on the type of problem (classification or regression), the training data is prepared.
For a regression problem with 1 output, here is some randomly generated training data where each sample has 3 inputs.
# Data inputs
data_inputs = numpy.array([[0.02, 0.1, 0.15],
[0.7, 0.6, 0.8],
[1.5, 1.2, 1.7],
[3.2, 2.9, 3.1]])
# Data outputs
data_outputs = numpy.array([[0.1],
[0.6],
[1.3],
[2.5]])Below is sample training data with 2 inputs for a binary classification problem like XOR. The outputs are prepared so that the output layer has 2 neurons; 1 for each class.
# XOR problem inputs
data_inputs = numpy.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
# XOR problem outputs
data_outputs = numpy.array([[1, 0],
[0, 1],
[0, 1],
[1, 0]])The next section discusses the loss function for regression and classification problems.
Loss Function
The loss function differs based on the problem type. This section discusses some loss functions in the tensorflow.keras.losses module of Keras for regression and classification problems.
Regression
For a regression problem, the loss functions include:
tensorflow.keras.losses.MeanAbsoluteError()tensorflow.keras.losses.MeanSquaredError()
Check out this page for more information.
Here is an example that calculates the mean absolute error where y_true and y_pred represent the true and predicted outputs.
mae = tensorflow.keras.losses.MeanAbsoluteError()
loss = mae(y_true, y_pred).numpy()Classification
For a classification problem, the loss functions include:
tensorflow.keras.losses.BinaryCrossentropy()for binary classification.tensorflow.keras.losses.CategoricalCrossentropy()for multi-class classification.
Check out this page for more information.
Here is an example for calculating the binary class entropy:
bce = tensorflow.keras.losses.BinaryCrossentropy()
loss = bce(y_true, y_pred).numpy()Based on the loss function, the fitness function is prepared according to the next section.
Fitness Function
The loss functions for either classification or regression problems are minimization functions, whereas the fitness functions for the genetic algorithm are maximization functions. So, the fitness value is calculated as the reciprocal of the loss value.
fitness_value = 1.0 / lossThe steps used to calculate the fitness value of the model are as follows:
- Restore the model parameters from the 1-D vector.
- Set the model parameters.
- Make predictions.
- Calculate the loss value.
- Calculate the fitness value.
- Return the fitness value.
Fitness for Regression
The code below builds the complete fitness function that works with PyGAD for a regression problem. The fitness function in PyGAD is a regular Python function that takes 2 arguments. The first represents the solution to which the fitness value is to be calculated. The second argument is the index of the solution within the population, which may be useful in some cases.
The solution passed to the fitness function is a 1-D vector. To restore the Keras model's parameters from this vector, the pygad.kerasga.model_weights_as_matrix() is used.
model_weights_matrix = pygad.kerasga.model_weights_as_matrix(model=model, weights_vector=solution)Once the parameters are restored, they are used as the model's current parameters by the set_weights() method.
model.set_weights(weights=model_weights_matrix)Based on the current parameters, the model predicts the outputs using the predict() method.
predictions = model.predict(data_inputs)The predicted outputs are used to calculate the loss value. The mean absolute error is used as a loss function.
mae = tensorflow.keras.losses.MeanAbsoluteError()Because the loss value may be 0.0, it is preferable to add a small value to it like 0.00000001 to avoid dividing by zero while calculating the fitness value.
solution_fitness = 1.0 / (mae(data_outputs, predictions).numpy() + 0.00000001)Finally, the fitness value is returned.
def fitness_func(solution, sol_idx):
global data_inputs, data_outputs, keras_ga, model
model_weights_matrix = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(weights=model_weights_matrix)
predictions = model.predict(data_inputs)
mae = tensorflow.keras.losses.MeanAbsoluteError()
solution_fitness = 1.0 / (mae(data_outputs, predictions).numpy() + 0.00000001)
return solution_fitnessFitness for Binary Classification
For a binary classification problem, below is a fitness function that works with PyGAD. It calculates the binary cross-entropy loss, assuming that the classification problem is binary.
def fitness_func(solution, sol_idx):
global data_inputs, data_outputs, keras_ga, model
model_weights_matrix = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(weights=model_weights_matrix)
predictions = model.predict(data_inputs)
bce = tensorflow.keras.losses.BinaryCrossentropy()
solution_fitness = 1.0 / (bce(data_outputs, predictions).numpy() + 0.00000001)
return solution_fitnessThe next section builds a callback function executed at the end of each generation.
Generation Callback Function (Optional)
A callback function can be called after each generation completes to calculate some statistics about the latest parameters reached. This step is optional, and for debugging purposes only.
The generation callback function is implemented below. In PyGAD, this callback function must accept a parameter referring to the instance of the genetic algorithm, by which the current population can be fetched using the population attribute.
This function prints the current generation number and the fitness value of the best solution. Such information keeps the user updated on the progress of the genetic algorithm.
def callback_generation(ga_instance):
print("Generation = {generation}".format(generation=ga_instance.generations_completed))
print("Fitness = {fitness}".format(fitness=ga_instance.best_solution()[1]))Create an Instance of the pygad.GA Class
The next step towards training a Keras model using PyGAD is to create an instance of the pygad.GA class. The constructor of this class accepts many arguments that can be explored in the documentation.
The next code block instantiates the pygad.GA class by passing the minimum number of arguments for this application, which are:
num_generations: Number of generations.num_parents_mating: Number of parents to mate.initial_population: The initial population of Keras model's parameters.fitness_func: The fitness function.on_generation: The generation callback function.
Note that the number of solutions within the population was previously set to 10 in the constructor of the KerasGA class. Thus, the number of parents to mate must be less than 10.
num_generations = 250
num_parents_mating = 5
initial_population = keras_ga.population_weights
ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
initial_population=initial_population,
fitness_func=fitness_func,
on_generation=callback_generation)The next section runs the genetic algorithm to start training the Keras model.
Run the Genetic Algorithm
The instance of the pygad.GA class runs by calling the run() method.
ga_instance.run()By executing this method, the lifecycle of PyGAD starts according to the next figure.
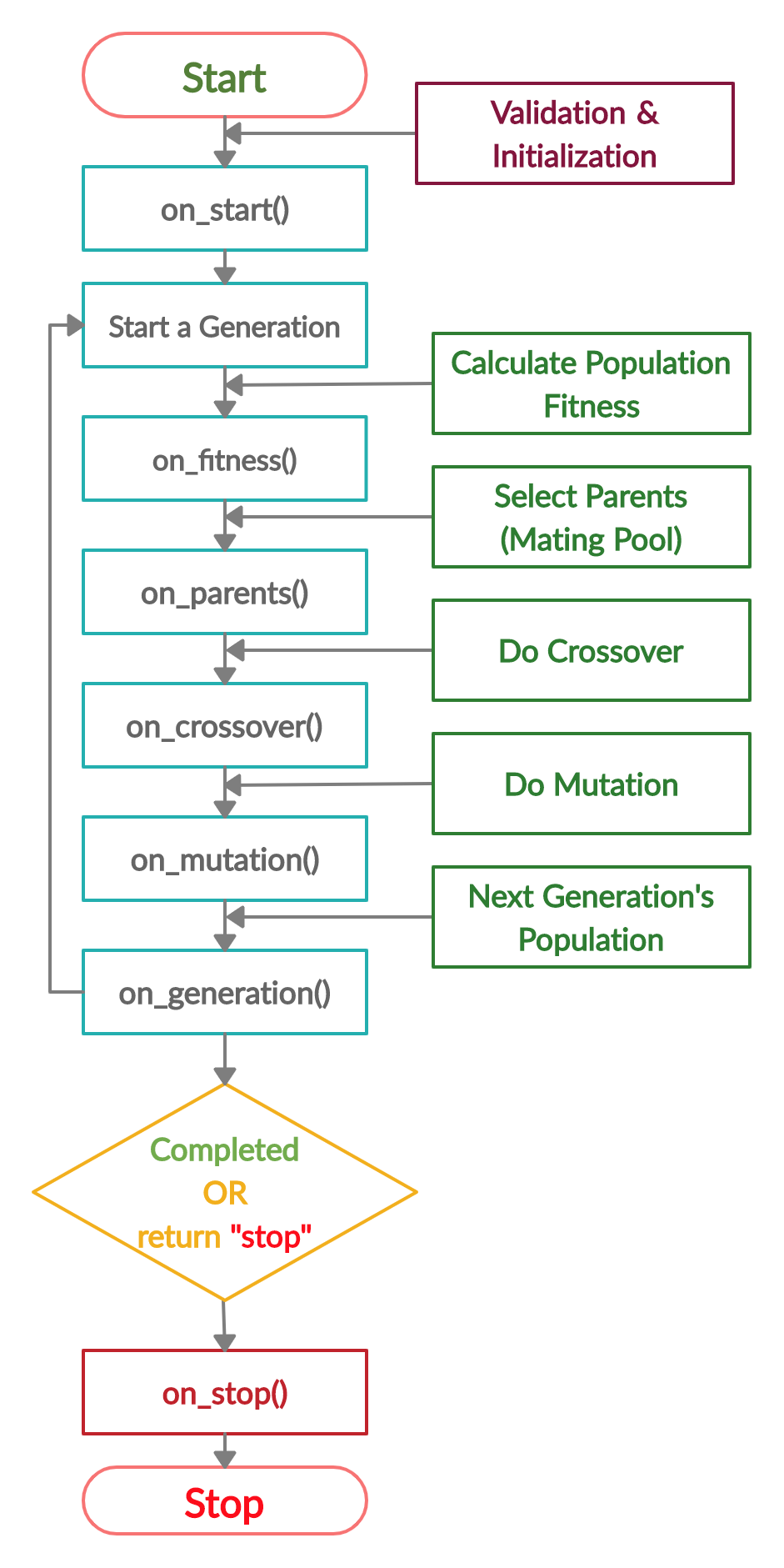
The next section discusses how to draw some conclusions about the trained model.
Fitness vs. Generation Plot
Using the plot_result() method in the pygad.GA class, PyGAD creates a figure that shows how the fitness value changes per generation.
ga_instance.plot_result(title="PyGAD & Keras - Iteration vs. Fitness", linewidth=4)Statistics About The Trained Model
The pygad.GA class has a method called best_solution() which returns 3 outputs:
- The best solution found.
- The fitness value of the best solution.
- The index of the best solution within the population.
The following code calls the best_solution() method and prints information about the best solution found.
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print("Fitness value of the best solution = {solution_fitness}".format(solution_fitness=solution_fitness))
print("Index of the best solution : {solution_idx}".format(solution_idx=solution_idx))Next, we'll restore the Keras model's weights from the best solution. Based on the restored weights, the model predicts the outputs of the training samples. You can also predict the outputs of new samples.
# Fetch the parameters of the best solution.
best_solution_weights = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(best_solution_weights)
predictions = model.predict(data_inputs)
print("Predictions : \n", predictions)The code below calculates the loss, namely the mean absolute error.
mae = tensorflow.keras.losses.MeanAbsoluteError()
abs_error = mae(data_outputs, predictions).numpy()
print("Absolute Error : ", abs_error)Complete Code for Regression
For a regression problem that uses the mean absolute error as a loss function, here is the complete code.
import tensorflow.keras
import pygad.kerasga
import numpy
import pygad
def fitness_func(solution, sol_idx):
global data_inputs, data_outputs, keras_ga, model
model_weights_matrix = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(weights=model_weights_matrix)
predictions = model.predict(data_inputs)
mae = tensorflow.keras.losses.MeanAbsoluteError()
abs_error = mae(data_outputs, predictions).numpy() + 0.00000001
solution_fitness = 1.0 / abs_error
return solution_fitness
def callback_generation(ga_instance):
print("Generation = {generation}".format(generation=ga_instance.generations_completed))
print("Fitness = {fitness}".format(fitness=ga_instance.best_solution()[1]))
input_layer = tensorflow.keras.layers.Input(3)
dense_layer1 = tensorflow.keras.layers.Dense(5, activation="relu")(input_layer)
output_layer = tensorflow.keras.layers.Dense(1, activation="linear")(dense_layer1)
model = tensorflow.keras.Model(inputs=input_layer, outputs=output_layer)
weights_vector = pygad.kerasga.model_weights_as_vector(model=model)
keras_ga = pygad.kerasga.KerasGA(model=model,
num_solutions=10)
# Data inputs
data_inputs = numpy.array([[0.02, 0.1, 0.15],
[0.7, 0.6, 0.8],
[1.5, 1.2, 1.7],
[3.2, 2.9, 3.1]])
# Data outputs
data_outputs = numpy.array([[0.1],
[0.6],
[1.3],
[2.5]])
num_generations = 250
num_parents_mating = 5
initial_population = keras_ga.population_weights
ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
initial_population=initial_population,
fitness_func=fitness_func,
on_generation=callback_generation)
ga_instance.run()
# After the generations complete, some plots are showed that summarize how the outputs/fitness values evolve over generations.
ga_instance.plot_result(title="PyGAD & Keras - Iteration vs. Fitness", linewidth=4)
# Returning the details of the best solution.
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print("Fitness value of the best solution = {solution_fitness}".format(solution_fitness=solution_fitness))
print("Index of the best solution : {solution_idx}".format(solution_idx=solution_idx))
# Fetch the parameters of the best solution.
best_solution_weights = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(best_solution_weights)
predictions = model.predict(data_inputs)
print("Predictions : \n", predictions)
mae = tensorflow.keras.losses.MeanAbsoluteError()
abs_error = mae(data_outputs, predictions).numpy()
print("Absolute Error : ", abs_error)After the code completes, the next figure shows how the fitness value is increasing. This shows that the Keras model is learning properly.
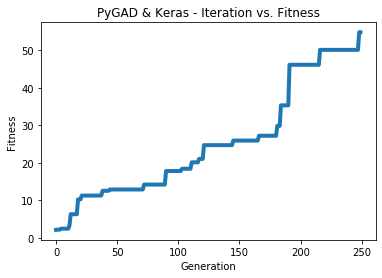
Here are more details about the trained model. Note that the predicted values are close to the real ones. The MAE is 0.018.
Fitness value of the best solution = 54.79189095217631
Index of the best solution : 0
Predictions :
[[0.11471477]
[0.6034051 ]
[1.3416876 ]
[2.486804 ]]
Absolute Error : 0.018250866Complete Code for Classification Using a CNN
The following code builds a convolutional neural network using Keras for classifying a dataset of 80 images, where the size of each image is 100x100x3. Note that the categorical cross-entropy loss is used because the dataset has 4 classes.
The training data can be downloaded from here (dataset inputs) and here (dataset outputs).
import tensorflow.keras
import pygad.kerasga
import numpy
import pygad
def fitness_func(solution, sol_idx):
global data_inputs, data_outputs, keras_ga, model
model_weights_matrix = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(weights=model_weights_matrix)
predictions = model.predict(data_inputs)
cce = tensorflow.keras.losses.CategoricalCrossentropy()
solution_fitness = 1.0 / (cce(data_outputs, predictions).numpy() + 0.00000001)
return solution_fitness
def callback_generation(ga_instance):
print("Generation = {generation}".format(generation=ga_instance.generations_completed))
print("Fitness = {fitness}".format(fitness=ga_instance.best_solution()[1]))
# Build the keras model using the functional API.
input_layer = tensorflow.keras.layers.Input(shape=(100, 100, 3))
conv_layer1 = tensorflow.keras.layers.Conv2D(filters=5,
kernel_size=7,
activation="relu")(input_layer)
max_pool1 = tensorflow.keras.layers.MaxPooling2D(pool_size=(5,5),
strides=5)(conv_layer1)
conv_layer2 = tensorflow.keras.layers.Conv2D(filters=3,
kernel_size=3,
activation="relu")(max_pool1)
flatten_layer = tensorflow.keras.layers.Flatten()(conv_layer2)
dense_layer = tensorflow.keras.layers.Dense(15, activation="relu")(flatten_layer)
output_layer = tensorflow.keras.layers.Dense(4, activation="softmax")(dense_layer)
model = tensorflow.keras.Model(inputs=input_layer, outputs=output_layer)
keras_ga = pygad.kerasga.KerasGA(model=model,
num_solutions=10)
# Data inputs
data_inputs = numpy.load("dataset_inputs.npy")
# Data outputs
data_outputs = numpy.load("dataset_outputs.npy")
data_outputs = tensorflow.keras.utils.to_categorical(data_outputs)
num_generations = 200
num_parents_mating = 5
initial_population = keras_ga.population_weights
ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
initial_population=initial_population,
fitness_func=fitness_func,
on_generation=callback_generation)
ga_instance.run()
ga_instance.plot_result(title="PyGAD & Keras - Iteration vs. Fitness", linewidth=4)
# Returning the details of the best solution.
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print("Fitness value of the best solution = {solution_fitness}".format(solution_fitness=solution_fitness))
print("Index of the best solution : {solution_idx}".format(solution_idx=solution_idx))
# Fetch the parameters of the best solution.
best_solution_weights = pygad.kerasga.model_weights_as_matrix(model=model,
weights_vector=solution)
model.set_weights(best_solution_weights)
predictions = model.predict(data_inputs)
# print("Predictions : \n", predictions)
# Calculate the categorical crossentropy for the trained model.
cce = tensorflow.keras.losses.CategoricalCrossentropy()
print("Categorical Crossentropy : ", cce(data_outputs, predictions).numpy())
# Calculate the classification accuracy for the trained model.
ca = tensorflow.keras.metrics.CategoricalAccuracy()
ca.update_state(data_outputs, predictions)
accuracy = ca.result().numpy()
print("Accuracy : ", accuracy)The next figure shows how the fitness value evolves per generation. As long as the fitness value increases, you can increase the number of generations to achieve better accuracy.
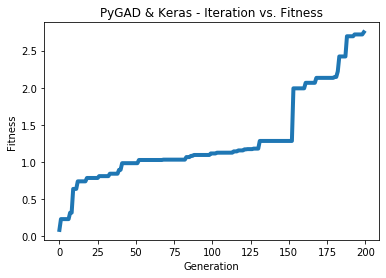
Here is some information about the trained model:
Fitness value of the best solution = 2.7462310258668805
Categorical Crossentropy : 0.3641354
Accuracy : 0.75Conclusion
In this tutorial we saw how to train Keras models using the genetic algorithm with the open source PyGAD library. The Keras models can be created using the Sequential Model or the Functional API.
Using the pygad.kerasga module an initial population of Keras model weights is created, where each solution holds a different set of weights for the model. This population is later evolved according to the lifecycle of PyGAD until all the generations are complete.
Due to the high-speed nature of TensorFlow, which is the backend of Keras, PyGAD can train complex architectures in an acceptable amount of time.











