
Bring this project to life
Text-To-Speech (TTS) synthesis is another one of the holy grails of ML and DL research: a technology that could prove so ubiquitous that it forever alters the relevant environment it is used in. There have been numerous attempts to develop such technology in recent years, with projects like Microsoft's NaturalSpeech or FastDiff making waves for their versatility and progress towards the lofty goal of true, fast TTS.
In this paper, we are going to discuss arguably one of the best and most impactful new frameworks to hit the TTS scene: VALL-E. Introduced by Wang et al. earlier this year in their paper "Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers", VALL-E represents a palpable step forwards in the task of imitating a natural speaker.
In this article, we will take a high level look at VALL-E, its model framework, and then jump into a coding demo showing how to use Enhuiz' unofficial implementation of VALL-E to train our own version of the ground breaking model within a Gradient Notebook.
Intro To VALL-E
VALL-E is a novel TTS framework based conceptually on a neural codec language model (the titular VALL-E) that uses discrete codes derived from an off-the-shelf neural audio codec model as an intermediate representation to replace the traditional mel spectrogram, and "regard[s] TTS as a conditional language modeling task rather than continuous signal regression as in previous work". (Source)

VALL-E has a significantly higher required amount of training data needed to train a working TTS model, but it also gives the ability to contextually learn audio codec codes as intermediate representations, leveraging large and diverse data, leading to strong in-context learning capabilities.
In practice, the creators of the model were able to show that VALL-E generates synthetic, natural-sounding speech with high degree of similarity to the speaker with zero-shot prompting, and their evaluation demonstrated that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system (YourTTS) on LibriSpeech and VCTK.
Model Architecture
Unlike previous TTS pipelines, which typically follow a pattern of converting phonemes first to a mel-spectrogram and then to waveform, the pipeline of VALL-E is to first get the phonemes instead represented as discrete codes before converting to waveform.

The model takes in text prompts as phonemes and 3 second enrolled recording samples of the inputted, corresponding audio sample from the target speaker. VALL-E generates the corresponding acoustic tokens conditioned on the acoustic tokens of the 3-second enrolled recording and the phoneme prompt, which constrain the speaker and content information respectively. Finally, the generated acoustic tokens are used to synthesize the final waveform with the corresponding neural codec decoder.
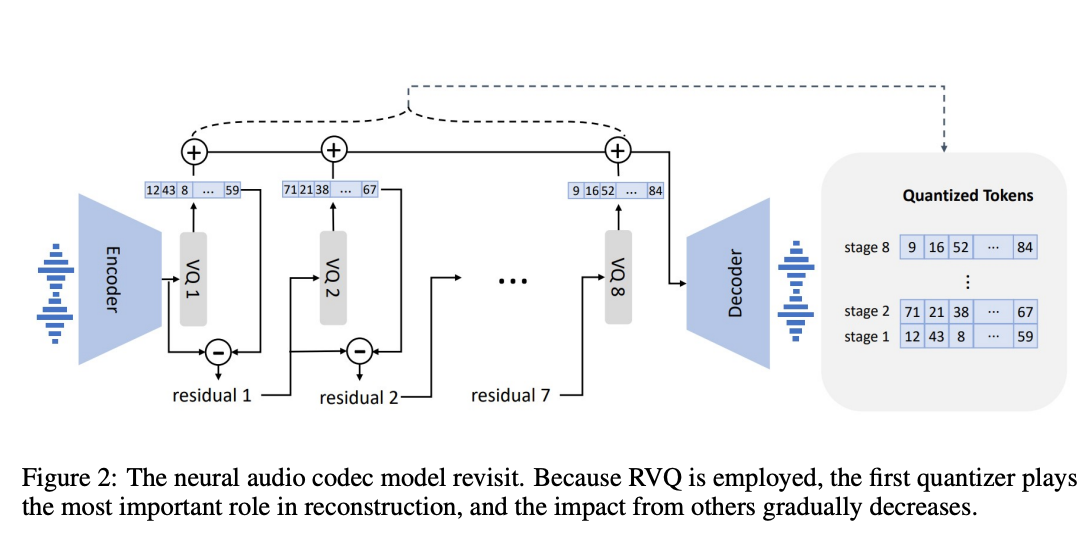
The neural speech codec model allows the model to perform operations on discrete audio representations. "Due to residual quantization in the neural codec model, the tokens have a hierarchical structure: tokens from previous quantizers recover acoustic properties like speaker identity, while the consecutive quantizers learn fine acoustic details." (source) Each quantizer is trained to model the residual from the previous quantizers. To handle these, the authors designed two conditional language models in a hierarchical manner.
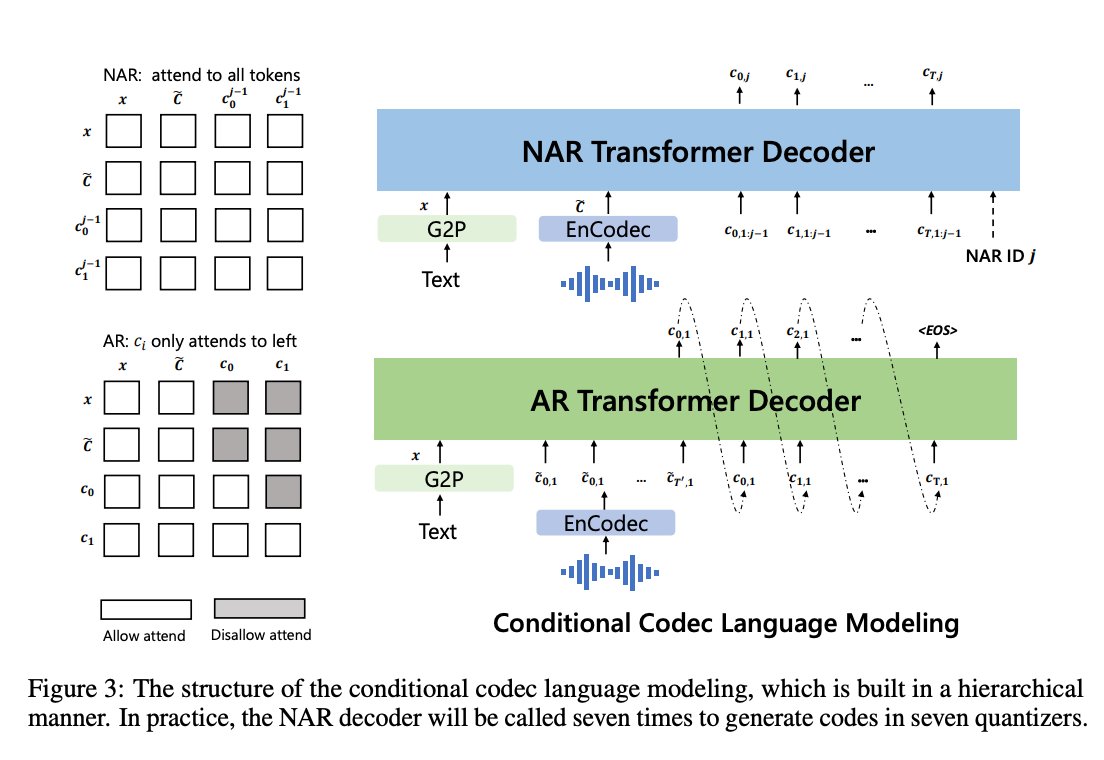
To perform the encoding, it trains both an autoregressive (AR) decoder-only language model and a non-autoregressive (NAR) decoder only language model. The combination of the AR model and the NAR model offers a good trade-off between speech quality and inference speed.
Demo
Now we will get into the demo. This was built on top of the work using einhuiz' unofficial implementation of VALL-E, as the official implementation has not been released. Be sure to give the original repo a star if you are working with this tech!
Bring this project to life
Setting up the Notebook
Installing VALL-E requires a small amount of setup work in a Gradient Notebook, as we need to upgrade the environment's python to 3.10. Run the cell below to install the required version of python.
!wget https://github.com/korakot/kora/releases/download/v0.10/py310.sh
!bash ./py310.sh -b -f -p /usr/local
!python -m ipykernel install --name "py310" --userOnce that is complete, we can install the actual VALL-E package and its requirements using the git repo.
%cd ~/../notebooks
!git clone https://github.com/enhuiz/vall-e
%cd vall-e
!pip install -e .
%cd ..Once we have completed setup, it's time to get our data in place for training. There are no currently available pretrained models, but Paperspace is currently training one to attach to this demo upon completion. Check back here in a few weeks for more details (updated Feb/10).
Setting up the data: Libri-Light
For this demo, we are going to use Libri-Light, "a benchmark for the training of automatic speech recognition (ASR) systems with limited or no supervision" (source) from Meta AI. It is comprised of a collection of 60K hours of unlabelled speech from audiobooks in English, and a series of small labelled datasets (of length 10 hours, 1 hour, and 10 minutes each) and metrics.
We are going to setup two paths in this demo: training on the 10 hour subset of labeled data, and training on a small sample of data using our own voice recordings. To go along with this, we are going to use QuickTime Player on our local machine, but you can use any audio recording device and application. If you are unable to create your own audio samples, there is an additional tutorial loop for overtraining on a piece of sample data from the original repo, as well.
To get the data set up, we will pull it from the internet into our notebook, and move around the files so that they comply with the methodology used by VALL-E. Run the cell below to download the data.
!wget https://dl.fbaipublicfiles.com/librilight/data/librispeech_finetuning.tgz
!unzip librispeech_finetuning.tgzThen, we are going to move around the data to fit in the format we need for VALL-E. This is pretty convoluted, but it quickly re-aligns all the files as needed. Run the cell below to reorganize the files.
import os
## setup Libri-Light
!mkdir vall-e/data/libri
import os
for k in os.listdir('librispeech_finetuning/9h/clean'):
for j in os.listdir('librispeech_finetuning/9h/'+'clean'):
for z in os.listdir('librispeech_finetuning/9h/clean/'+j):
for i in os.listdir('librispeech_finetuning/9h/clean/'+j+'/'+z):
os.rename('librispeech_finetuning/9h/clean/'+j+'/'+z+'/'+i, f'vall-e/data/libri/{i}')
break
lst = []
for i in os.listdir('vall-e/data/libri'):
try:
if 'trans' in i:
with open(f'vall-e/data/libri/{i}') as text_file:
for row in text_file:
z = row.split('-')
name = z[0]+'-'+z[1]+ '-' + z[2].split(' ')[0]
text = " ".join(z[2].split(' ')[1:])
# print(name, text)
lst.append([name, text])
except:
None
for i in lst:
try:
with open('vall-e/data/libri/'+i[0]+'.txt', 'x') as file:
# print(i[1])
file.write(i[1])
except:
with open('vall-e/data/libri/'+i[0]+'.txt', 'w+') as file:
# print(i[1])
file.write(i[1])
for i in sorted(os.listdir('vall-e/data/libri')):
if i.split('.')[1] == 'txt':
# print(i)
print('.'.join([i.split('.')[0],'normalized',i.split('.')[1]]))
os.rename('vall-e/data/libri/'+i, 'vall-e/data/libri/'+'.'.join([i.split('.')[0],'normalized',i.split('.')[1]]))Finally, we need to convert all the files to .wav format:
!pip install AudioConverter
!audioconvert convert vall-e/data/libri/ vall-e/data/libri --output-format .wav
Once our data is all ready, we use the built in VALL-E methods to set up our phonemes and quantize the data for training:
%cd vall-e
!python -m vall_e.emb.qnt data/libri
!python -m vall_e.emb.g2p data/libriFrom here, if we want to train on this dataset, we can move on to the Training section below. To train on your own data, continue on.
Setting up your own data
Now it's time for us to get our own data on here. Pick one of the sample folders from Libri-Light. We are going to use /248/130644. Take a look at the text file within, composed of lines of text corresponding to the original FLAC files.
Earlier, we split this file up into individual files to better fit within our VALL-E training paradigm. To set up our own data, we can facilitate this by copying each of the corresponding text files to a new folder, let's call it vall-e/data/libri2. These text files will be used to create completely novel data set using our own voice data and the original text files.
!mkdir vall-e/data/libri2import os
for i in sorted(os.listdir('vall-e/data/libri')):
if i.split('.')[1] == 'normalized' and i.split('-')[0] == '248' and i.split('-')[1] == '130644':
# print(i)
os.rename('vall-e/data/libri/'+i, 'vall-e/data/libri2/'+i)The more data we record, the better, but for this demo, we are just going to use a single folder with 26 recordings. Use the snippet above to move the data for the 248-130644 text files into a new folder, vall-e/data/libri2. Then, on your local machine, using your preferred audio recording application, record yourself reading each of the relevant text lines. Save each audio file in .wav format with the corresponding title. Then upload them to the Gradient Notebook directory, vall-e/data/libri2. Since we are using the same text files, the snippet above will move them to the new folder for us from the original Libri Light dataset.
%cd vall-e
!python -m vall_e.emb.qnt data/libri2
!python -m vall_e.emb.g2p data/libri2Once that is complete, we complete setup for the data by using VALL-E's in built quantizer and phoneme generator. Your final setup should look like the image below.
Train
We are finally ready to train! This part is fortunately very simply implemented. All we need to do is run the cell below, after hashing out whichever training we would like to avoid. If we are running on a Paperspace Free-GPU, we will need to use the single GPU setup.
%cd vall-e
# run on Libri Light multi-GPU
python -m torch.distributed.launch --nproc_per_node 4 -m vall_e.train yaml=config/libri/ar.yml
python -m torch.distributed.launch --nproc_per_node 4 -m vall_e.train yaml=config/libri/nar.yml
# run on Libri Light single-GPU
python -m vall_e.train yaml=config/libri/ar.yml
python -m vall_e.train yaml=config/libri/nar.yml
# run on your sample of librispeech rerecording
# Multi-GPU
python -m torch.distributed.launch --nproc_per_node 4 -m vall_e.train yaml=config/libri2/ar.yml
python -m torch.distributed.launch --nproc_per_node 4 -m vall_e.train yaml=config/libri2/nar.yml
# Single GPU
python -m vall_e.train yaml=config/libri2/ar.yml
python -m vall_e.train yaml=config/libri2/nar.yml
As training is ongoing, the model will report relevant training metrics in the outputs. These outputs will also be stored in the logs directory in the corresponding log.txt file, organized by which data source the training is conducted on. Below is an example of the information output after an epoch:
2023-02-08 03:24:56,848 - vall_e.utils.trainer - INFO -
{
"model.loss": 0.034698486328125,
"model.lr": 0.00019794095918367348,
"model.grad_norm": 0.420499324798584,
"model.elapsed_time": 5.772308349609375,
"model.engine_step": 1512,
"model.loss.nll": 0.034698486328125,
"elapsed_time": 5.772308349609375,
"wall_time": 1675826696.8483896,
"global_step": 1512
}Additionally, based on our settings in the config file, the model will regularly save checkpoints for use. When we are finished with training, we can export the models to the model zoo for sampling using the code in the cell below:
!python -m vall_e.export zoo/ar.pt yaml=config/libri2/ar.yml
!python -m vall_e.export zoo/nar.pt yaml=config/libri2/nar.ymlSampling the new model
Sampling with VALL-E requires three things: the pretrained model, a prompt, and a reference audio sample. The model uses the prompt to transform the audio into the desired voice.
In the cell below, we show how to query our now trained model to output a sample audio snippet in our voice. This first query uses the original voice data from the dataset.
!python -m vall_e "BUT WOULD MAKE THE VERY BEST OF THE CHANCES THAT LIFE OFFERED HER AND CONQUER CIRCUMSTANCES BY HER EXCEPTIONAL CLEVERNESS" data/libri/248-130644-0018.wav toy1.wav
!python -m vall_e "BUT WOULD MAKE THE VERY BEST OF THE CHANCES THAT LIFE OFFERED HER AND CONQUER CIRCUMSTANCES BY HER EXCEPTIONAL CLEVERNESS" data/libri2/248-130644-0018.wav toy1.wav
We can then use the ipywidgets module to quickly listen to our sample and see how it holds up:
from IPython.display import Audio
Audio('toy1.wav')
Libri Light
Here are the samples from our training on Libri Light. This sample has only been trained for 8000 steps for the AR model and 12500 for the NAR model, using a batch size of 8 on an A1000.
As we can hear, though bits of the original tone do break through, the current output is undertrained. This is a very computationally expensive task, so we recommend a multi GPU set up like Paperspace's A6000x4 for running this training.
We will update this section in the future after more training has had time to complete.
My Voice Sample
Here are the samples using one of the subfolders of Libri Light re-recorded in my own voice. Since I was training on a significantly smaller dataset, these models were able to fit well enough to the presented dataset. Using the reference files in this way, I was able to accurately recreate the voice sample inputs.
Closing thoughts
In this article, we looked at the novel VALL-E TTS model, and showed how to train it within a Gradient Notebook. Readers should be able to now run this entire process on their own to recreate their own voice samples with VALL-E. This is still the unofficial implementation, so it will be interesting to see if Microsoft will make the official version available open-source someday.
Check back to this article in the future for updates to the Libri Light model and, potentially, a free checkpoint trained on the full Libri Light dataset for easier fine-tuning.









