

One of the key technologies in the latest generation of GPU microarchitecture releases from Nvidia is the Tensor Core. These specialized processing subunits, which have advanced with each generation since their introduction in Volta, accelerate GPU performance with the help of automatic mixed precision training.
In this blogpost we'll summarize the capabilities of Tensor Cores in the Volta, Turing, and Ampere series of GPUs from NVIDIA. Readers should expect to finish this article with an understanding of what the different types of NVIDIA GPU cores do, how Tensor Cores work in practice to enable mixed precision training for deep learning, how to differentiate the performance capabilities of each microarchitecture's Tensor Cores, and the knowledge to identify Tensor Core-powered GPUs on Paperspace.
What are CUDA cores?
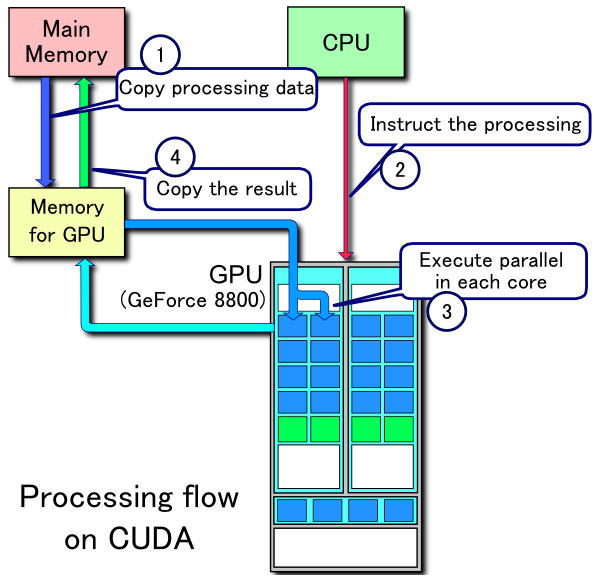
When discussing the architecture and utility of Tensor Cores, we first need to broach the topic of CUDA cores. CUDA (Compute Unified Device Architecture) is NVIDIA's proprietary parallel processing platform and API for GPUs, while CUDA cores are the standard floating point unit in an NVIDIA graphics card. These have been present in every NVIDIA GPU released in the last decade as a defining feature of NVIDIA GPU microarchitectures.
Each CUDA core is able to execute calculations and each CUDA core can execute one operation per clock cycle. Although less capable than a CPU core, when used together for deep learning, many CUDA cores can accelerate computation by executing processes in parallel.
Prior to the release of Tensor Cores, CUDA cores were the defining hardware for accelerating deep learning. Because they can only operate on a single computation per clock cycle, GPUs limited to the performance of CUDA cores are also limited by the number of available CUDA cores and the clock speed of each core. To overcome this limitation, NVIDIA developed the Tensor Core.
What are Tensor Cores?
Tensor Cores are specialized cores that enable mixed precision training. The first generation of these specialized cores do so through a fused multiply add computation. This allows two 4 x 4 FP16 matrices to be multiplied and added to a 4 x 4 FP16 or FP32 matrix.
Mixed precision computation is so named because while the inputted matrices can be low-precision FP16, the finalized output will be FP32 with only a minimal loss of precision in the output. In effect, this rapidly accelerates the calculations with a minimal negative impact on the ultimate efficacy of the model. Subsequent microarchitectures have expanded this capability to even less precise computer number formats!
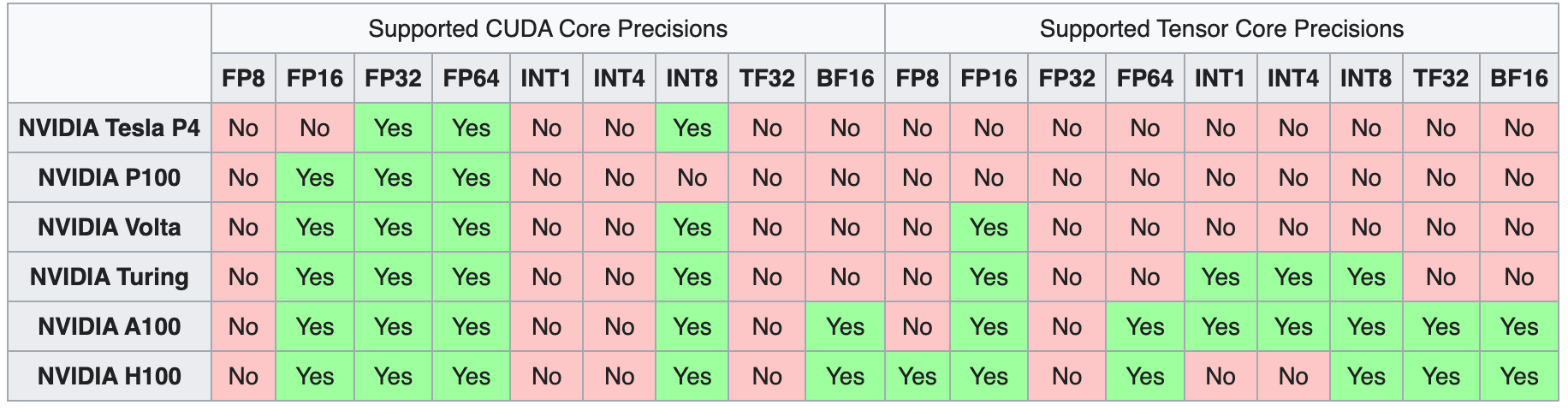
The first generation of Tensor Cores were introduced with the Volta microarchitecture, starting with the V100. (Source) With each subsequent generation, more computer number precision formats were enabled for computation with the new GPU microarchitectures. In the next section, we will discuss how each microarchitecture generation altered and improved the capability and functionality of Tensor Cores.
For more information about mixed information training, please check out our breakdown here to learn how to use mixed precision training with deep learning on Paperspace.
How do Tensor Cores work?
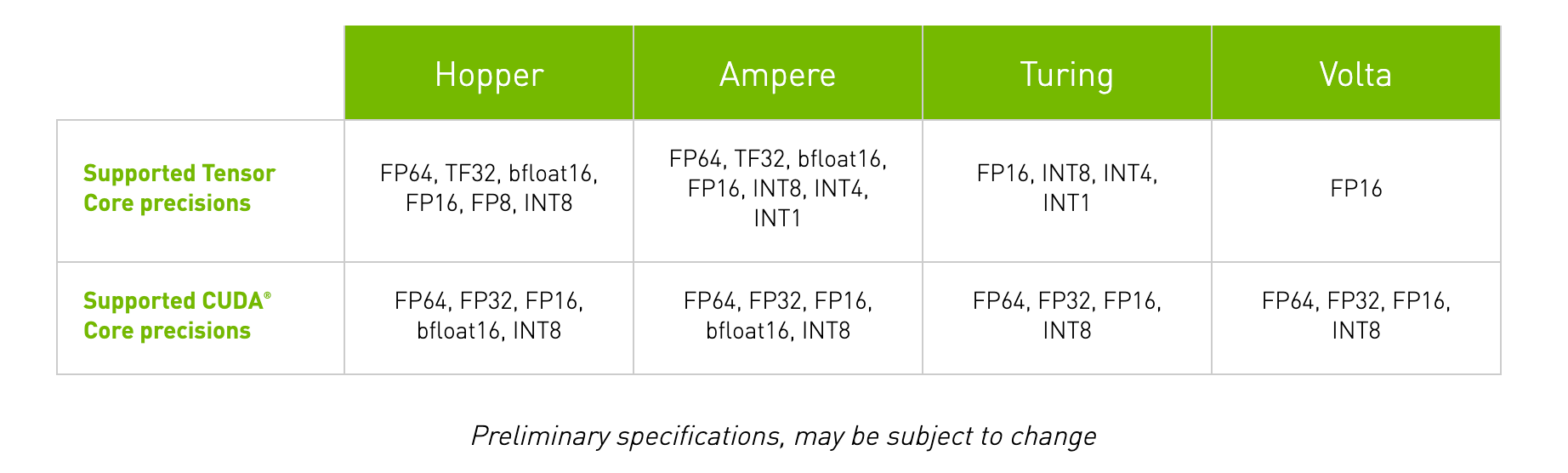
Each generation of GPU microarchitecture has introduced a novel methodology to improve performance among Tensor Core operations. These changes have extended the capabilities of the Tensor Cores to operate on different computer number formats. In effect, this massively boosts GPU throughput with each generation.
First Generation
The first generation of Tensor Cores came with the Volta GPU microarchitecture. These cores enabled mixed precision training with FP16 number format. This increased the potential throughput on these GPUs by up to 12x in terms of teraFLOPs. In comparison to the prior generation Pascal GPUs, the 640 cores of the flagship V100 offer up to a 5x increase in performance speed. (Source)
Second Generation
The second generation of Tensor Cores came with the release of Turing GPUs. The supported Tensor Core precisions were extended from FP16 to also include Int8, Int4, and Int1. This allowed for mixed precision training operations to accelerate the performance throughput of the GPU by up to 32x that of Pascal GPUs!
In addition to second generation GPUs, Turing GPUs also contain Ray Tracing cores, which are used to compute graphic visualization properties like light and sound in 3d environments. You can take advantage of these specialized cores to boost your game and video creation process to the next level with RTX Quadro GPUs on Paperspace Core.
Third Generation
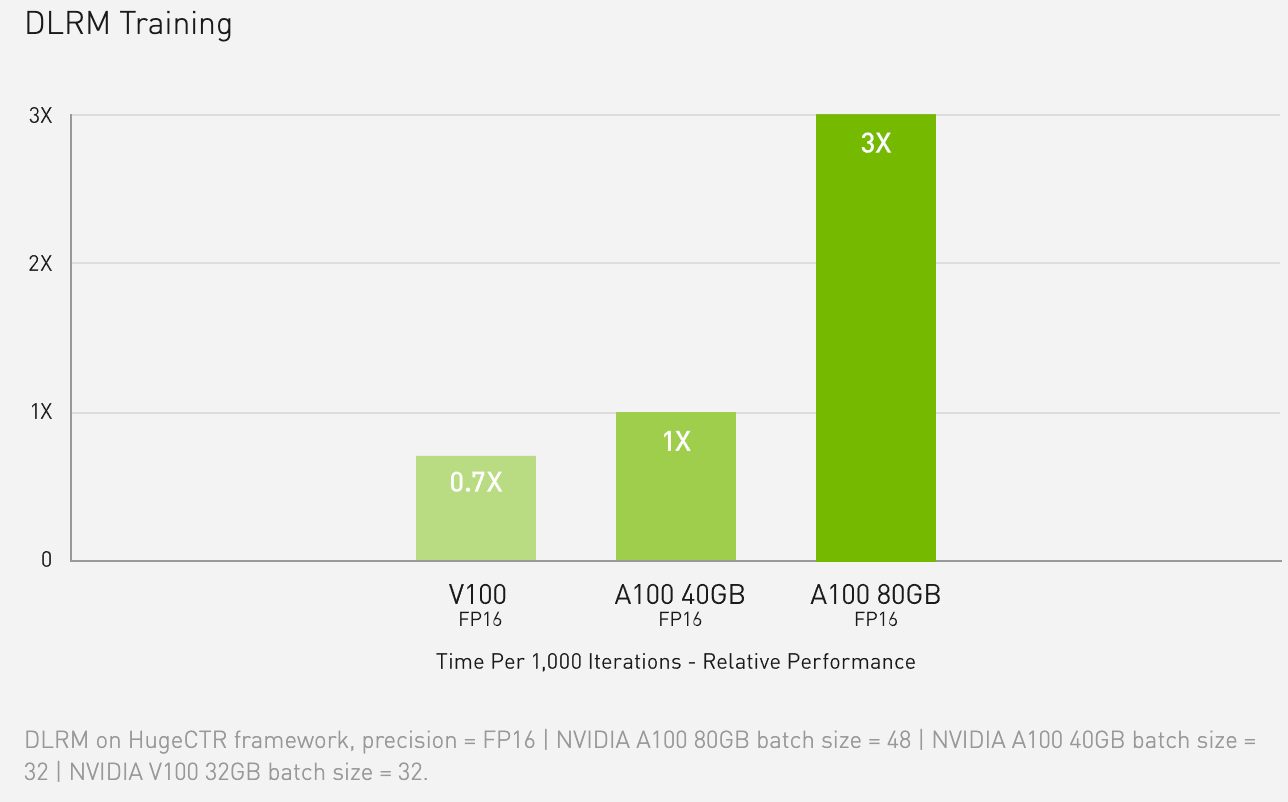
The Ampere line of GPUs introduced the third generation of Tensor Cores and the most powerful yet.
In an Ampere GPU, the architecture builds on the previous innovations of the Volta and Turing microarchitectures by extending computational capability to FP64, TF32, and bfloat16 precisions. These additional precision formats work to accelerate deep learning training and inference tasks even further. The TF32 format, for example, works similarly to FP32 while simultaneously ensuring up to 20x speedups without changing any code. From there, implementing automatic mixed precision will further accelerate training additional 2x with only a few lines of code. Furthermore, the Ampere microarchitecture has additional features like specialization with sparse matrix mathematics, third-generation NVLink to enable lightning fast multi-GPU interactions, and third-generation Ray Tracing cores.
With these advancements, Ampere GPUs -- specifically the data center A100 -- are currently the most powerful GPUs available on the market. When working with more of a budget, the workstation GPU line, such as the A4000, A5000, and A6000 also offer an excellent avenue to take advantage of the powerful Ampere microarchitecture and its third generation Tensor Cores at a lower price point.
Fourth Generation

The fourth generation of Tensor Cores will be released with the Hopper microarchitecture sometime in the future. Announced March 2022, the upcoming H100 will feature fourth generation Tensor Cores which will have extended capability to handling FP8 precision formats and which NVIDIA claims will speed up large language models "by an incredible 30X over the previous generation" (Source).
In addition to this, NVIDIA claims that their new NVLink technology will allow up to 256 H100 GPUs to connect. These will be huge boons for further raising the computational scale on which data workers can operate.
Which Paperspace GPUs have Tensor Cores?
The Paperspace GPU cloud offers a wide assortment of GPUs from the past five generations, including GPUs from the Maxwell, Pascal, Volta, Turing, and Ampere microarchitectures.
Maxwell and Pascal microarchitectures predate the development of Tensor Cores and Ray Tracing cores. The effect of this difference in composition is very clear when looking at deep learning benchmark data for these machines, as it clearly shows that more recent microarchitectures will outperform older microarchitectures when they have similar specifications like memory.
The V100 is the only GPU available on Paperspace with Tensor Cores but no Ray Tracing cores. While it remains an excellent deep learning machine overall, the V100 was the first data center GPU to feature Tensor Cores. Its older design means that it has fallen behind workstation GPUs like the A6000 in terms of performance for deep learning tasks.
The workstation GPUs RTX4000 and RTX5000 offer excellent budget options on the Paperspace platform for deep learning. For example, the second generation Tensor Cores boost in capability allow the RTX5000 to achieve nearly comparable performance in terms of batch size and time to completion on benchmarking tasks when compared with the V100.
The Ampere GPU line, which feature both third generation Tensor Cores and second generation Ray Tracing cores, boosts throughput to unprecedented levels over the previous generations. This technology enables the A100 to have a throughput of 1555 GB/s, up from the 900 GB/s of the V100.
In addition to the A100, the workstation line of Ampere GPUs on Paperspace include the A4000, A5000, and A6000. These offer excellent throughput and the powerful Ampere microarchitecture at a much lower price point.
When the Hopper microarchitecture ships, the H100 will again raise GPU performance by up to 6x the current peak offered by the A100. The H100 will not be available for purchase until at least the third quarter of 2022 according to the GTC 2022 Keynote with NVIDIA CEO Jensen Huang.
Concluding thoughts
Technological advancement from generation to generation of GPU can be partially characterized by the advancement in Tensor Core technology.
As we detailed in this blog post, these cores enable high performance mixed precision training paradigms that have allowed the Volta, Turing, and Ampere GPUs to become the dominant machines for AI development.
By understanding the difference between these Tensor Cores and their capabilities, we can understand more clearly how each subsequent generation has lead to massive increases in the amount of raw data that can be processed for deep learning tasks at any given moment.
If you have any questions about what GPUs to run on Paperspace whether you're running Ubuntu machines on Core or notebooks on Gradient, please don't hesitate to reach out!
We're always here to help optimize your GPU cloud spend and efficiency.
Resources
- Paperspace Docs and GPU lineup
- Nvidia - Tensor Cores
- Nvidia - Tensor Cores (2)
- Nvidia - Hopper Architecture
- Nvidia - Ampere Architecture
- Nvidia - Turing Architecture
- Nvidia - Volta Architecture
- H100 - Nvidia product page
- A100 - Nvidia product page
- V100 - Nvidia product page
- Full breakdown on Tensor Cores from TechSpot
- Succinct breakdown on Tensor Cores from TechCenturion
- TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x












.PNG?ref=blog.paperspace.com){kind=link}