
The race towards the optimal attention mechanism continues as this year's (arguably) largest computer vision conference CVPR 2021 had another attention mechanism added to the long list. This one is called Coordinate Attention, and was proposed in the paper Coordinate Attention for Efficient Mobile Network Design. At first glance the attention mechanism seems to be a hybrid between Triplet Attention and Strip Pooling, but more specifically targeted for lightweight mobile-deployed networks.
We will first take a look at the motivation behind the work and then follow up with a concise background of Triplet Attention (Rotate to Attend: Convolutional Triplet Attention Module) and Strip Pooling (Strip Pooling: Rethinking Spatial Pooling for Scene Parsing). We will then analyze the structure of the proposed mechanism and conclude this article with the results presented in the paper.
Table of Contents
- Motivation
- Coordinate Attention
- PyTorch Code
- Results
- Conclusion
- References
Bring this project to life
Abstract
Recent studies on mobile network design have demonstrated the remarkable effectiveness of channel attention (e.g., the Squeeze-and Excitation attention) for lifting model performance, but they generally neglect the positional information, which is important for generating spatially selective attention maps. In this paper, we propose a novel attention mechanism for mobile networks by embedding positional information into channel attention, which we call "coordinate attention". Unlike channel attention that transforms a feature tensor to a single feature vector via 2D global pooling, the coordinate attention factorizes channel attention into two 1D feature encoding processes that aggregate features along the two spatial directions, respectively. In this way, long range dependencies can be captured along one spatial direction and meanwhile precise positional information can be preserved along the other spatial direction. The resulting feature maps are then encoded separately into a pair of direction-aware and position-sensitive attention maps that can be complementarily applied to the input feature map to augment the representations of the objects of interest. Our coordinate attention is simple and can be flexibly plugged into classic mobile networks, such as MobileNetV2, MobileNeXt, and EfficientNet with nearly no computational overhead. Extensive experiments demonstrate that our coordinate attention is not only beneficial to ImageNet classification but more interestingly, behaves better in down-stream tasks, such as object detection and semantic segmentation.
Motivation
Architectural design has been a major area of recent research in the domain of Computer Vision. Many might argue that this direction of research is becoming saturated, but research is defying these arguments with several new advancements in the design of custom layers and attention mechanisms. The focus of this post is the latter – Attention Mechanisms. Attention mechanisms essentially provide additional information on 'where' and 'what' to focus on, based on the provided input data. Several attention methods like Squeeze and Excitation (SE), Convolutional Block Attention Module (CBAM), Triplet Attention, Global Context (GC), and many more have demonstrated the efficiency of such plug-in modules to significantly improve the performance of conventional baseline models at a minimal increase in computational complexity. Take the word "minimal" with a grain of salt however, as models have been striving to enforce the performance-increasing benefits of attention modules at the lowest overhead possible. However, the approach of designing these attention mechanisms has been primarily focused on large-scale networks, since the computational overhead introduced by these methods makes them unviable for mobile networks with a limited capacity. Additionally, most attention mechanisms are focused on channel information only, and lose out on expressivity due to negating the spatial information present.
Based on these shortcomings:
In this paper, beyond the first works, we propose a novel and efficient attention mechanism by embedding positional information into channel attention to enable mobile networks to attend over large regions while avoiding incurring significant computation overhead.
The authors call this novel attention mechanism Coordinate Attention, because its operation distinguishes spatial direction (i.e., coordinate) and generates coordinate-aware attention maps.
Coordinate attention offers the following advantages. First of all, it captures not only cross-channel but also direction-aware and position-sensitive information, which helps models to more accurately locate and recognize the objects of interest. Secondly, the method is flexible and light-weight, and can be easily plugged into classic building blocks of mobile networks, such as the inverted residual block proposed in MobileNetV2 and the sandglass block proposed in MobileNeXt, to augment the features by emphasizing informative representations. Thirdly, as a pretrained model, coordinate attention can bring significant performance gains to down-stream tasks with mobile networks, especially for those with dense predictions (e.g., semantic segmentation).
Coordinate Attention
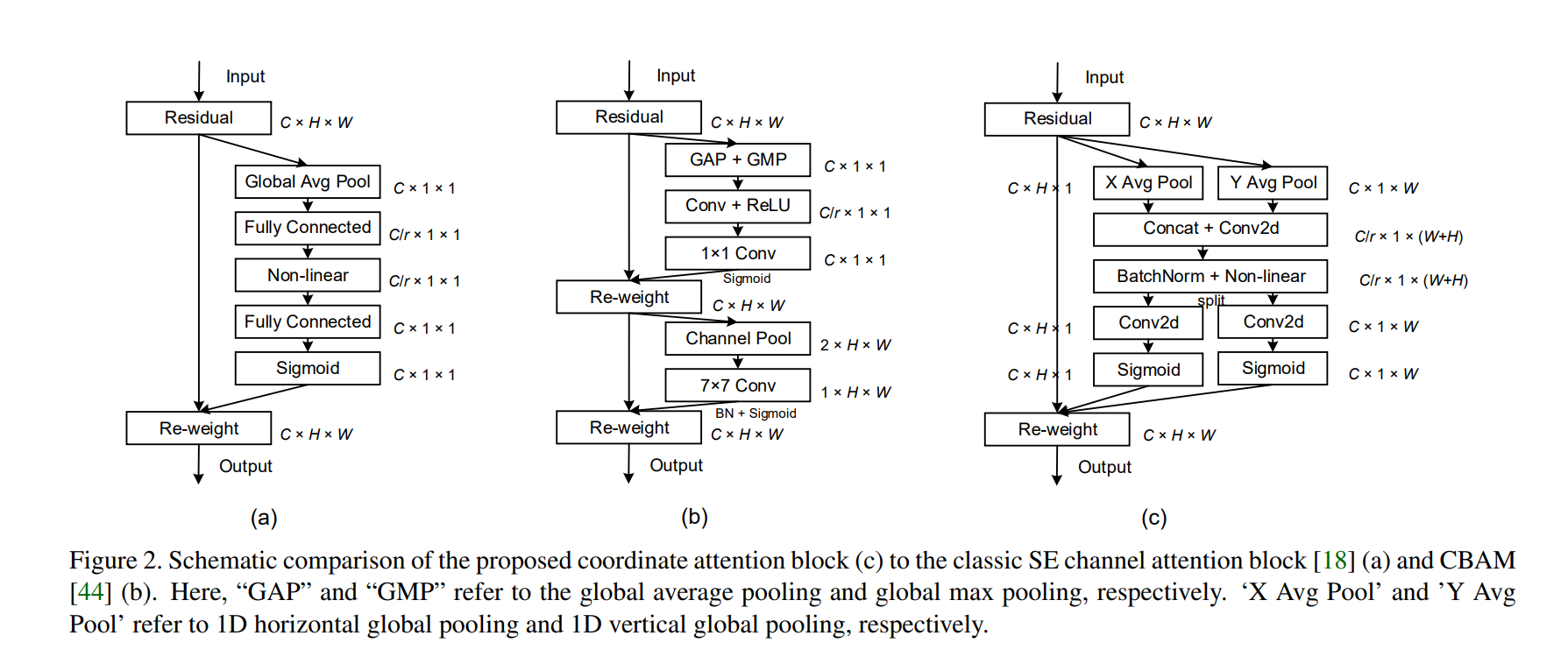
As hinted at in the preface of the article, Coordinate Attention as shown in the above figure (c) is somewhat similar to the structure of Triplet Attention and Strip Pooling published at WACV 2021 and CVPR 2020, respectively. (Spoiler: Both of these papers are also from the same author as that of Coordinate Attention).
Strip Pooling (CVPR 2020)
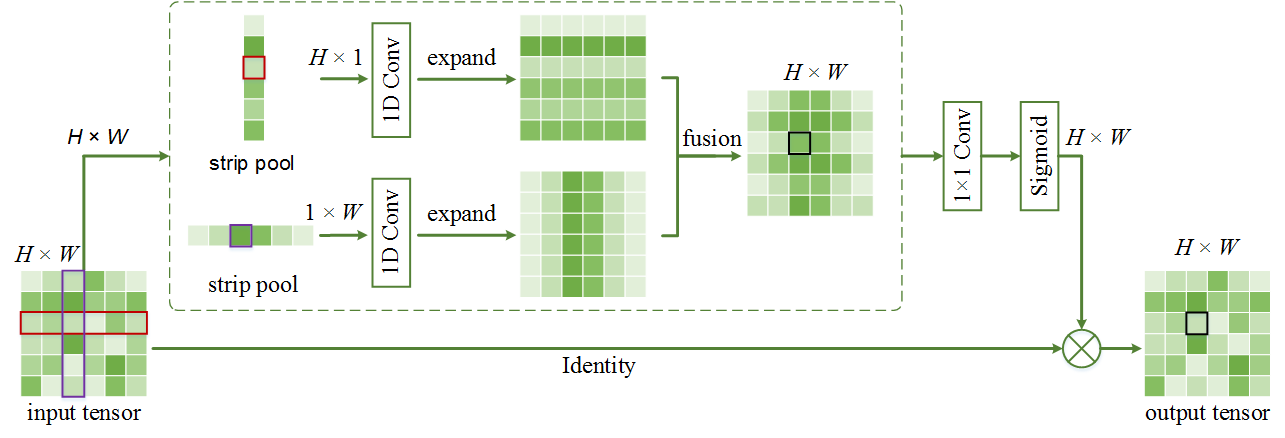
While the primary focus of the paper was scene parsing, looking at the structure we can notice similarities between the Strip Pooling and Coordinate Attention architectural designs. Strip Pooling essentially takes the input tensor $X \in \mathbb{R}^{C \ast H \ast W}$ and for every spatial feature map, it reduces it into two spatial vectors $H \ast 1$ and $W \ast 1$, respectively. These two vectors are then passed through two 1D convolution kernels followed by a bilinear interpolation process to the original $H \ast W$ shape, which are finally element-wise added. This map is then passed through a pointwise convolution and is element-wise multiplied to the original feature map by applying a sigmoid activation on it before the multiplication.
Triplet Attention (WACV 2021)
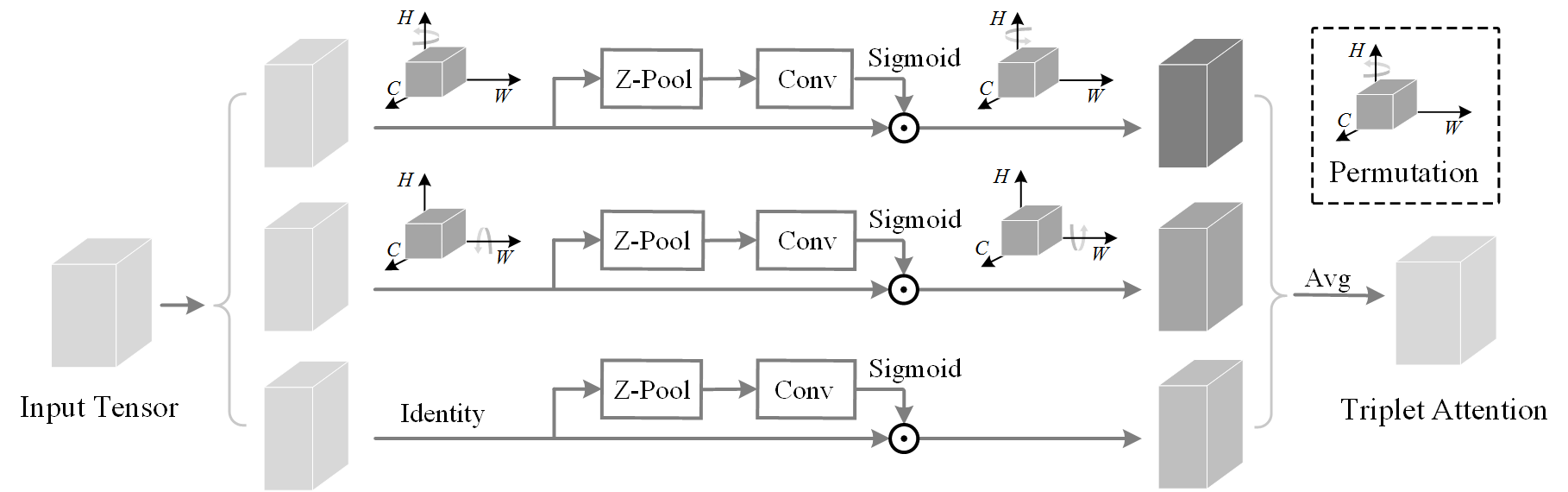
More related to Coordinate Attention in terms of domain, Triplet Attention offered a structure which essentially computes spatial attention in correspondence to channel information by isolating each spatial dimension using permutation operations. This concept was termed by the paper as "Cross Dimension Interaction (CDI)". For an in-depth analysis of Triplet Attention, please view my blogpost here.
Back to Coordinate Attention, let's dissect what's happening in the module. As shown in the figure at the start of this section, Coordinate Attention (Coord Att.) takes an input tensor $X \in \mathbb{R}^{C \ast H \ast W}$ and applies average pool across the two spatial dimensions $H$ and $W$ and obtains two tensors $X' \in \mathbb{R}^{C \ast H \ast 1}$ and $X'' \in \mathbb{R}^{C \ast 1 \ast W}$. Then these two tensors are concatenated to form $X''' \in \mathbb{R}^{C \ast 1 \ast (H + W)}$ which is subsequently passed through a 2D convolution kernel which reduces the channels from $C$ to $\frac{C}{r}$ based on a specified reduction ratio $r$. This is followed by a normalization layer (Batch Norm in this case) and then an activation function (Hard Swish in this case). Finally the tensor is split into $\hat{X} \in \mathbb{R}^{\frac{C}{r} \ast 1 \ast W}$ and $\tilde{X} \in \mathbb{R}^{\frac{C}{r} \ast H \ast 1}$. These two tensors are individually passed through two 2D convolution kernels, each of which increases the channels back to $C$ from $\frac{C}{r}$, and finally a sigmoid activation is applied on the resultant two tensors which are the attention maps. The attention maps are then sequentially element-wise multiplied with the original input tensor $X$.
PyTorch Code
The following snippet provides the PyTorch code for the Coordinate Attention module which can be plugged into any classic backbone.
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return outResults
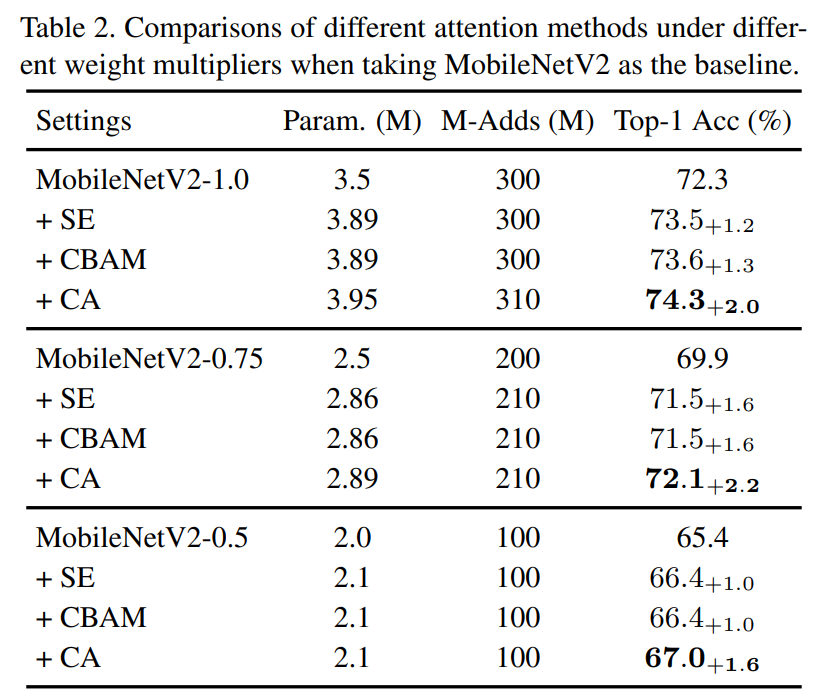
For complete set of extensive results on experiments conducted by the authors, I highly advise taking a look at the paper. Here we only show the prominent results on image classification on ImageNet using MobileNet and MobileNext, and on object detection on MS-COCO where Coordinate Attention showcases all round improvements in terms of performance.
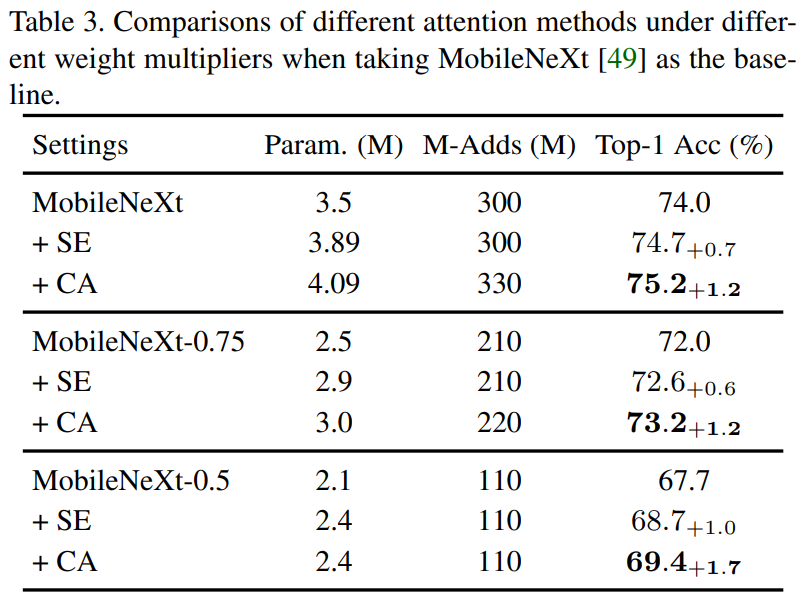
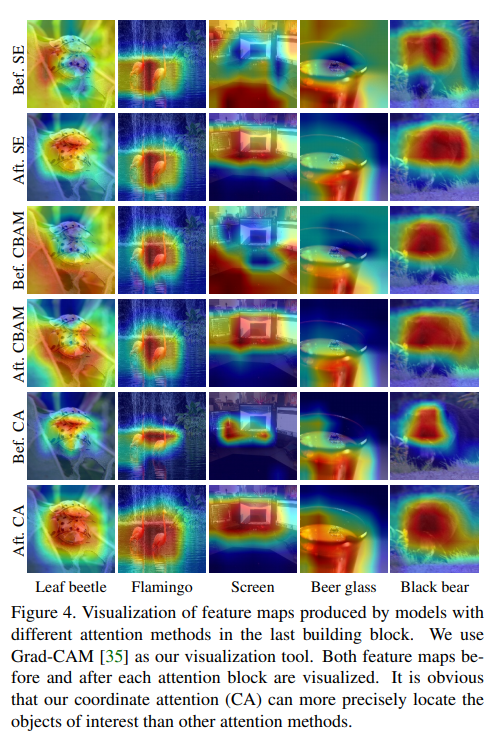
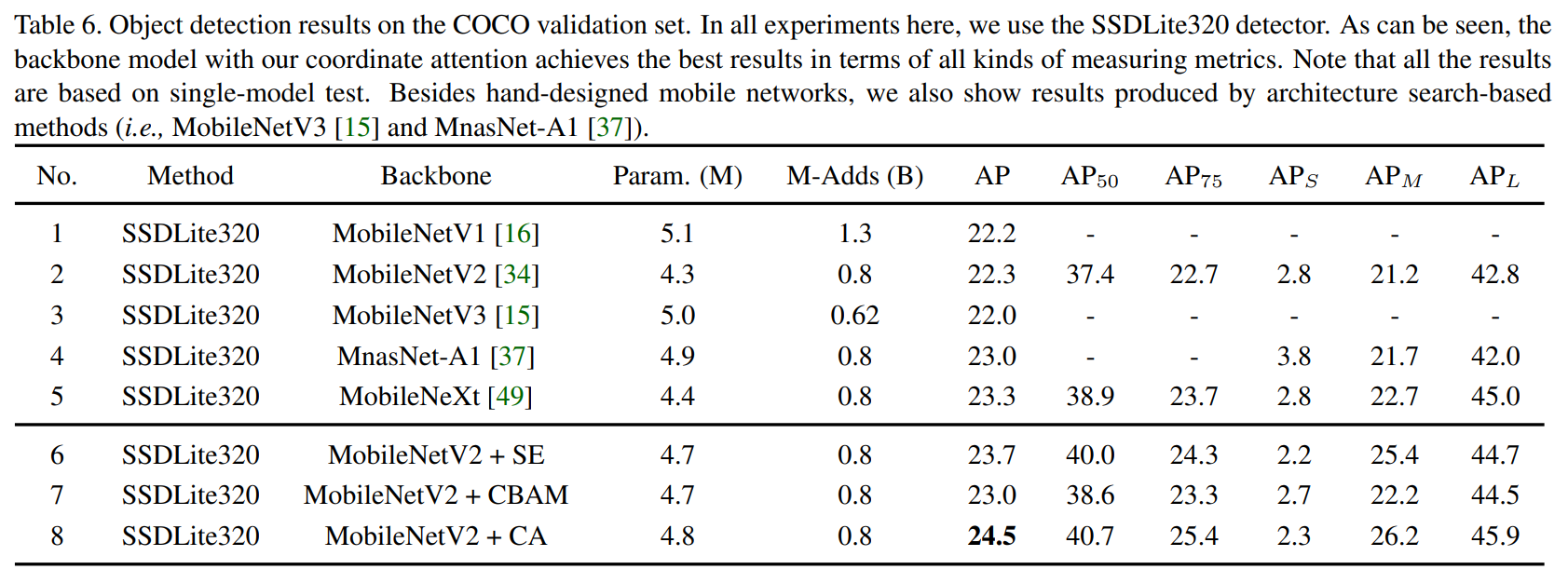
Conclusion
Although the results are impressive in their own right, the proposed method is counterintuitive to one of the main motivations of the paper: low-cost attention for mobile networks, since Coordinate Attention is, in fact, costlier both in terms of parameters and FLOPs compared to the two methods it was compared against (CBAM and SE). The second drawback is the limited number of comparisons. Although SE and CBAM are prominent attention methods, there have been many more advancements with better-performing and lower cost attention modules which the authors failed to compare against Triplet and ECA. Also, the Coordinate Attention module is not an apple-to-apple comparison against CBAM, since the former uses hard swish as its activation which provides a significant performance boost, however, it is compared to the latter which uses ReLU (which is inferior to hard swish).
However, it is up to the readers to decide whether the paper does justice and provides yet another effective attention module to try.











