

Artificial Intelligence (AI) is one of the most revolutionary developments in modern history. Tasks once deemed impossible for computers to achieve are now easily accomplished by artificial intelligence, in some cases, even surpassing humans for a particular task. With the rapid advancement of technology and the availability of large amounts of data, it is possible for us to develop AI models and algorithms to solve a variety of problems. AI is a humungous field of study, consisting of multiple sub-branches and subsets. These concepts include machine learning, deep learning, natural language processing, computer vision, mathematics, and the topic of focus for this article, reinforcement learning.
We will be looking at a 2-part series where we will gain an intuitive understanding of reinforcement learning in the first part, while we will construct a couple of projects with reinforcement learning in the next part. For this article, we will understand the major aspects of reinforcement learning after a brief introduction to this field of study. We will then have a discussion on some of the algorithms and policies that we can utilize for accomplishing tasks with the help of reinforcement learning. Finally, we will develop a basic starter project with deep reinforcement learning to ensure that we have all the essentials mastered perfectly.
Table of Contents:
- Introduction to Reinforcement Learning
- Understanding concepts of Reinforcement Learning
- Discussion on numerous Reinforcement Learning algorithms
- Starter Project with Deep Reinforcement Learning
1. Introduction to cart pole project
2. Installing and acquiring the required libraries
3. Activating the testing environment
4. Creating our deep learning model
5. Constructing our RL agent
6. Saving and reloading the RL agent - Conclusion
Introduction to Reinforcement Learning:
Humans often tend to learn from experiences about their abilities, constraints, and types of actions that they can perform. Babies, when they are growing up, start to learn how to walk. Usually, this process seems quite natural because most humans evolve from slowly crawling to standing up, and finally, walking in baby footsteps. But babies tend to fall quite a bit during the learning phases before eventually adapting to the entire walking simulation process. This hit-and-trial learning method from failures to achieve something and accomplish a particular task is a common practice for humans. However, a similar branch of study also exists in the world of artificial intelligence that deals with such methods called reinforcement learning.
Under this field of study, we utilize reinforcement learning algorithms to train the desired models to learn from their previous mistakes. Once the models gain an intuitive understanding of their working procedure, their results show to slowly improve accordingly. There are several algorithms for such learning from failure methods that have been proposed in recent years to combat numerous tasks, including self-driving AI cars, industrial automation, robotics simulation, conquering gaming, and so much more. The utility of these reinforcement algorithms continues to grow rapidly in the modern era due to the influence they have on practical applications in the real world. In the next section of the article, let us get accustomed to the various concepts in reinforcement learning.
Understanding concepts of Reinforcement Learning:
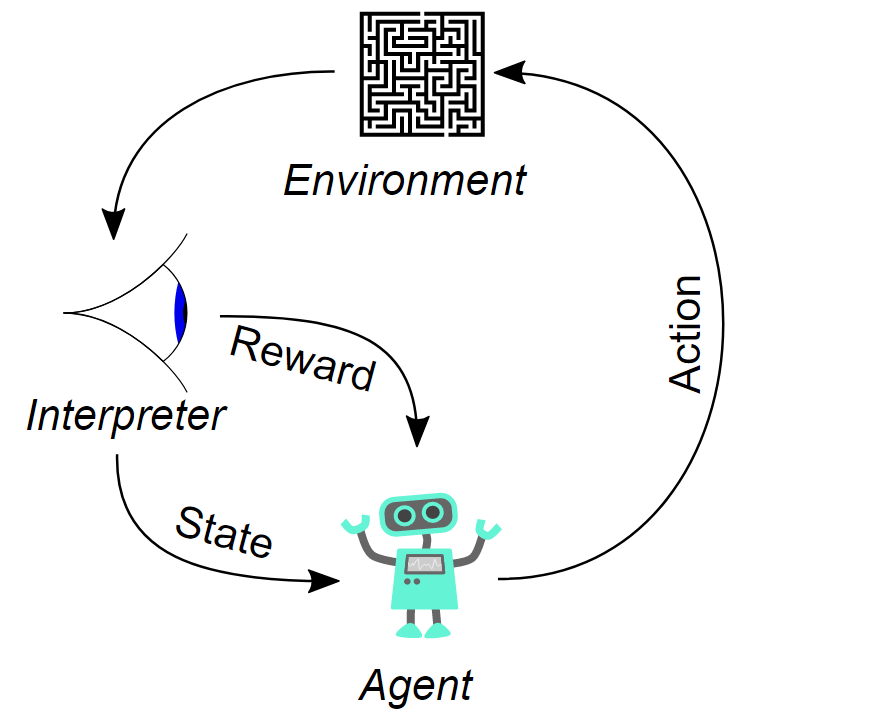
Reinforcement learning is one of the most unique techniques that we can train our models to learn as it utilizes a method of hit and trial to achieve the desired results. The five main concepts that constitute the core constitution of reinforcement learning are Agent, Action, Environment, Observations, and Rewards. Let us understand each of these individual elements separately and the significance they constitute in a reinforcement learning project.
The agent is the most significant component of the reinforcement learning model as it represents the core constituent that operates in the environment where it follows a certain set of rules governed by the principles of the particular task of operations and assigned policies. The rule given to the agent allows it to decide that path it needs to take to approach a particular problem.
On the other hand, we have an environment where the agent can operate and perform the specified tasks. For all of our reinforcement learning projects, we will utilize the OpenAI gym in which there are several pre-built environments allowing researchers to freely utilize and experiment with numerous reinforcement learning models and algorithms. We will learn more about OpenAI gym in the next article but let us learn some of the basic functions that we need to know.
In the OpenAI gym, some of the main functions that we will utilize are as follows:
- env.reset() – To reset the entire environment and obtain the initial values of observation.
- env.render() – Rendering the environment for displaying the visualization of the working setup.
- env.step() – To proceed with an action on the selected environment.
- env.close() – Close the particular render frame of the environment.
The action is what the agent can perform in the respective environment. It is better to understand this concept with a few examples. If you are trying to program a robotic arm simulation for lifting an object and placing it down, then there are two actions that you can perform, namely the up and down movements. On the other hand, if you are trying to teach a complex problem like training a reinforcement learning model in a game like Checkers, tic-tac-toe, or chess, there are several combinations and computations for each piece that the model can consider. In the example that we will discuss in a later section of this article, we have two actions of the cart pole, namely left and right. We will understand this concept further in the upcoming sections.
Finally, we have the concept of observation spaces or states and rewards. States represent the current position of the task that is being performed. These states include the type of action and position your agent is currently in relative to the environment of the task performed. A state s is a complete description of the state of the world. There is no information about the world which is hidden from the state. An observation o is a partial description of a state, which may omit information. Rewards are the bonus points that are awarded to the model upon the correct interpretation of the current problem. For every right action performed by the agent in the relative environment, the agent is awarded a bonus point or "reward." The principles of learning that the agent follows depend on the type of reinforcement learning algorithms and policies that are implemented by the user. In the next section of this article, we will try to gain a general overview of some of the reinforcement learning algorithms.
Bring this project to life
Discussion on numerous Reinforcement Learning algorithms:
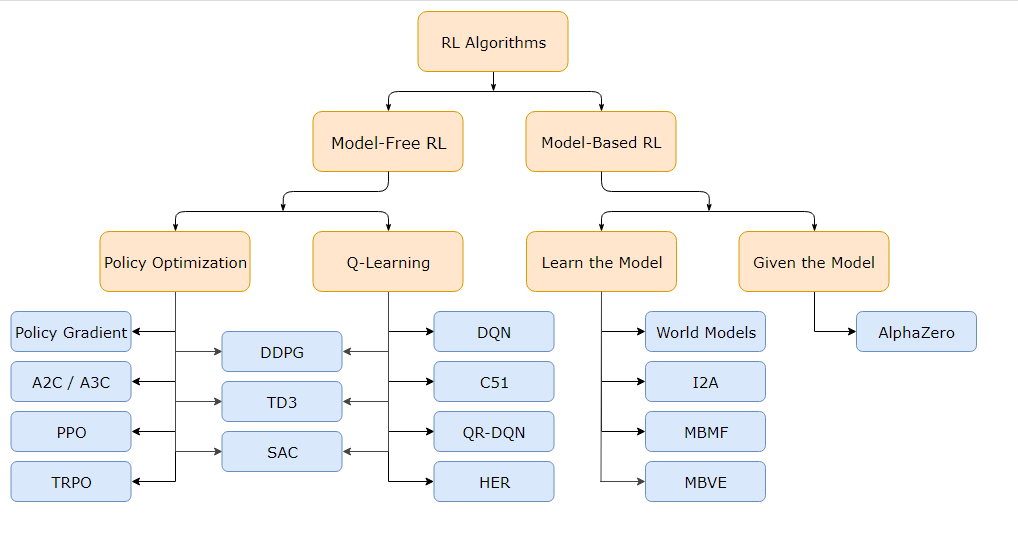
Reinforcement learning algorithms are the methods in which the agents gain feedback to perform the desired actions in the environment to achieve rewards and complete the task. There are tons of different types of reinforcement learning algorithms, and depending on the type of expert you choose to ask, the answers may vary. We will focus on the image representation shown above and discuss a few of the more useful algorithms that we need to know about. I would also recommend checking out some of the other algorithms that we don't cover in this article.
The two main classes for the classification of reinforcement learning algorithms include model-free RL and model-based RL. The key difference to note amongst the two is in model-free RL we make use of the current state values to make future predictions whereas the model-based RL approaches also consider future states to make their respective predictions. A problem such as a cart pole problem can utilize model-free approaches such as a PPO or DQN algorithm, while a problem such as chess or shogi would utilize the model-based approaches to predict the best possible outcomes.
In model-free reinforcement learning, we have primarily two major techniques that we utilize for solving numerous tasks namely, policy optimization-based approach and Q-learning approaches. Firstly, we will discuss the policy optimization technique, which makes use of a performance objective and accordingly adjusts and optimizes its values to suit the policy. In Proximal Policy Optimization (PPO) method, the updates indirectly maximize performance, by instead maximizing a surrogate objective function which gives a conservative estimate for how much the performance objective will change as a result of the update.
On the other hand, we have the Actor-Critic (A2C) reinforcement learning algorithm, which is another method of a model-free approach that performs gradient ascent to directly maximize performance. In the model-free approach, Q-learning is one of the other more popular techniques that is utilized to solve a variety of reinforcement learning projects such as tic-tac-toe. This technique utilizes the Bellman Equation and an off-policy approach to update the values regardless of the stage of training. The deep Q-network (DQN) algorithm is a major algorithm proposed by Deep Mind and one of the popular Q-learning algorithms to solve numerous problems.
On the other hand, for model-based reinforcement learning approaches, we have Alpha Zero. Alpha Zero is one of the most popular examples of the strength possessed by reinforcement learning algorithms. If you are an avid follower of chess, there are high chances that you would have encountered the term chess engines and Alpha Zero. The primary advantage of having a model for reinforcement learning is that it allows the agent to plan ahead. Hence, programs such as Alpha Zero are able to conquer complex problems such as shogi and chess while being able to achieve high-quality results. It has also been able to achieve superhuman performance in the game of Go by tabula rasa reinforcement learning from games of self-play.
There are also several policies that you can choose for your particular model to operate on. These policies dictate how your models are built and how exactly they will interact and operate in the environment you have created. The stable baselines module that we will utilize in the next article supports three primary policies, namely MLP Policy, CNN Policy, and Multi-Input Policy. We will learn more about stable-baselines3 in the next article. For now, we will note that policies are plans or strategies that will be utilized by the agent to perform the specific actions taking the function of the agent state and environment. Feel free to explore more on this topic and check out the following link for a more detailed explanation.
Starter Project with Deep Reinforcement Learning:
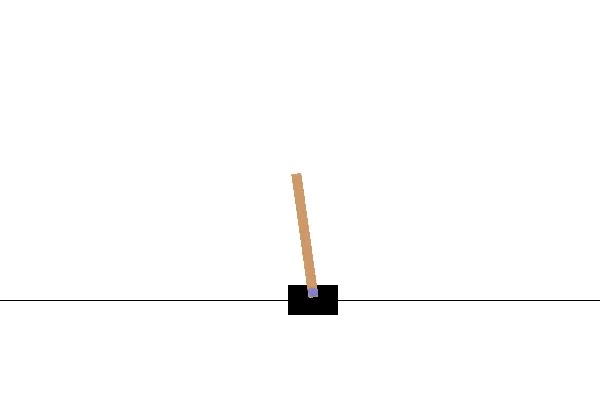
In this section of the article, we will focus on constructing a deep reinforcement learning project. We will work on a cart pole simulation for this particular deep reinforcement learning project. For those who are not familiar with the cart pole game, I would recommend checking out some online websites where you can try and play the game for yourself. One such website I could try out the following game was on the Flux website from this link.
The cart pole problem is basically a simulation of a stick or rod (referred to as the pole) attached by an un-actuated joint to a cart moving on a frictionless plane. The game depends on your ability to balance this pole on the cart accordingly. You can make use of the left and the right arrow keys to balance the positioning of the pole, which initially starts upright. A score of +1 is added for every move the player manages to keep the pole upright. In case the pole collapses to an angle below fifteen degrees, the game is over, and your total score is evaluated based on the calculated result.
We will try to achieve a solution to solve the above problem with the help of deep reinforcement learning. For solving this task, we will utilize the OpenAI gym for constructing the environment for the reinforcement learning model. We will discuss more on this utility in the next article, where we will cover this project and an0ther one in greater detail with the help of better libraries. The next couple of requirements for building this deep reinforcement learning model is to utilize a deep learning framework.
For this article, we will utilize the TensorFlow and Keras deep learning frameworks to achieve the desired result. Note that we will be using the PyTorch environment in the next article, where we will build a couple more projects with reinforcement learning. I have covered all the concepts related to these deep learning frameworks in my previous articles. If you haven't already checked them out or require a briefing on these concepts, look into the following - "The Absolute Guide to TensorFlow," "The Absolute Guide to Keras," and "The Ultimate Guide To PyTorch." I would also highly recommend checking out the following YouTube channel from this link. A majority of the inspiration and codes are referred to from the mentioned channel and this GitHub page. Let us now proceed to get started with the deep reinforcement learning project.
Installing and acquiring the required libraries:
The major requirements for constructing a deep reinforcement learning project are to make use of an environment to test our particular project and a deep learning framework to construct the model to solve the appropriate task. We will also require a reinforcement learning agent that will utilize an algorithm and policy that we desire to solve the task with the combination of all the discussed elements. The main requirements that you will need to install apart from the TensorFlow and Keras deep learning frameworks are the OpenAI gym library and Keras reinforcement learning library. Ensure that you are working in a virtual environment where you have the recent versions of TensorFlow and Keras installed. In the same virtual environment activated, run the below commands to have all the necessary requirements for this project satisfied.
pip install gym
pip install keras-rl2
To learn more about these two particular libraries, I would recommend checking out their official documentation, where a majority of the significant information is conveyed. We will also check out the OpenAI gym library in greater detail in the upcoming article, where we will construct a couple more projects with reinforcement learning. However, you can check out this link to learn more about OpenAI gym and this website for understanding more about Keras reinforcement learning.
Activating the testing environment:
In the next step of our project, we will construct the appropriate environment for testing the cart pole problem. Let us import a couple of essential libraries that we will utilize in this section of the article. The OpenAI gym is imported to create and develop our testing environment whereas the random library will help us to enter a random number of 0 or 1 for the sideways movement of the cart pole.
import gym
import randomOnce we have imported the required libraries, let us proceed to create our environment for creating and testing the reinforcement learning model. With the help of the make function, we will create the CartPole-v0 environment. We will now interpret the states, which is the number of observations possible and also interpret the number of actions possible. Note that there are four states, namely the position of the cart, the velocity of the cart, the angle of the cart, and angular velocity. The number of actions includes two, namely the left and right motions of the cart pole.
env = gym.make('CartPole-v0')
states = env.observation_space.shape[0]
actions = env.action_space.n
actionsIn the next code block, we will test the model in the environment for a total of ten episodes to see how it performs without any training. We will implement a random click of left or right with the assignment of the random choice for zero and one. For each step, we will calculate the score. For each right move, points are gained, whereas if the cart pole fails to remain upright at an angle of fifteen degrees, the game ends, and the final score calculated at the end of the episode is displayed. Check the code block below to understand the procedure for the following implementation.
episodes = 10
for episode in range(1, episodes+1):
state = env.reset()
done = False
score = 0
while not done:
env.render()
action = random.choice([0,1])
n_state, reward, done, info = env.step(action)
score+=reward
print('Episode:{} Score:{}'.format(episode, score))In the next sections, we will proceed to construct the deep learning model and the appropriate reinforcement learning agents for approaching this project. Our objective is to achieve a score of at least 200 for each episode.
Creating our deep learning model:
Let us now proceed to construct a simple deep learning architecture that we will utilize for constructing the model. The first step is to import all the necessary requirements for this procedure. We will import a Sequential model, along with the dense layer for a fully connected structure and a flatten layer. We will also make use of the Adam optimizer. I would suggest trying out different methods and approaches to test what type of model will suit your training model the best.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import AdamThe next step is to create a function in which we will build the model architecture. We will construct a Sequential model and flatten it to the four states from which we will pass it through a couple of hidden nodes of fully connected layers with the Dense layer of TensorFlow and Keras. In the final layer, we will utilize the linear activation function and interpret the two possible outputs, which are either the left or right-click. Once our model is constructed, we will continue to proceed to the next step to build the RL agent.
def build_model(states, actions):
model = Sequential()
model.add(Flatten(input_shape=(1,states)))
model.add(Dense(24, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(actions, activation='linear'))
return modelConstructing our RL agent:
Before constructing our RL agent for approaching this project, we will import all the required libraries for this task. We will make use of the DQN agent that you can check out from here and also utilize the Boltzmann Q Policy with the Sequential memory. All the necessary imports are as shown in the below code snippet.
from rl.agents import DQNAgent
from rl.policy import BoltzmannQPolicy
from rl.memory import SequentialMemoryIn the next code block, we will construct a function for building an RL agent similar to our model construction. We will define the essential parameters such as the policy, the memory, and the agent for approaching the problem. The below code block represents how to construct the desired function.
def build_agent(model, actions):
policy = BoltzmannQPolicy()
memory = SequentialMemory(limit=50000, window_length=1)
dqn = DQNAgent(model=model, memory=memory, policy=policy,
nb_actions=actions, nb_steps_warmup=10, target_model_update=1e-2)
return dqnWe can now call the model function that we have previously defined, as shown below.
model = build_model(states, actions)
model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 4) 0
_________________________________________________________________
dense_3 (Dense) (None, 24) 120
_________________________________________________________________
dense_4 (Dense) (None, 24) 600
_________________________________________________________________
dense_5 (Dense) (None, 2) 50
=================================================================
Total params: 770
Trainable params: 770
Non-trainable params: 0
_________________________________________________________________
Note:
AttributeError: 'Sequential' object has no attribute '_compile_time_distribution_strategy'
If you want to avoid the following error that is displayed in the above text box, ensure that the model is always constructed after the Keras RL imports. Otherwise, there is a possibility of a mixture of the Sequential memories that could cause the above error messages to be displayed, and you cannot continue to run the program as expected to achieve the desired results.
Similar to calling our model architecture, we will also build the desired agent with the respective deep learning model. Once we finish the process of building our agent with the model, we can proceed to compile and train the deep reinforcement learning model and test the performance of this model.
dqn = build_agent(model, actions)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
dqn.fit(env, nb_steps=50000, visualize=False, verbose=1)Once the training procedure is completed, we can load the scores for each episode and test the performance of this model. We should be able to achieve a score of at least 200 for each episode.
scores = dqn.test(env, nb_episodes=100, visualize=False)
print(np.mean(scores.history['episode_reward']))You can also visualize your result to check the performance of the cart pole by the deep reinforcement learning model.
_ = dqn.test(env, nb_episodes=15, visualize=True)Saving and reloading the RL agent:
The last section we will look at is the saving and reloading of the weights of the trained deep reinforcement learning model. Save the weights similar to a TensorFlow model with the desired name in h5 or h5f format, as shown below.
dqn.save_weights('dqn_weights.h5f', overwrite=True)If you are reloading the project and want to check the performance, it is quite simple. Reload the gym environment, the model structure, the actions and states possible, and finally, compile the model. Follow the below code block representation for achieving this task.
env = gym.make('CartPole-v0')
actions = env.action_space.n
states = env.observation_space.shape[0]
model = build_model(states, actions)
dqn = build_agent(model, actions)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])The last step is to load the saved weights for our trained model. This step is performed as shown below.
dqn.load_weights('dqn_weights.h5f')You can now proceed to test the loaded trained model and visually check the performance.
_ = dqn.test(env, nb_episodes=5, visualize=True)It is suggested to try out numerous combinations of agents, policies, and model architectures to see how your project can vary accordingly. In the upcoming article, we will look at another way to construct the cart pole project and also understand how to solve a self-driving car project with reinforcement learning.
Conclusion:

With the help of reinforcement learning, we can construct a wide variety of projects where an RL agent learns how to adapt to a particular scenario. With the help of the knowledge achieved on all the concepts of reinforcement learning, one can easily construct an algorithm to navigate around a task like a cart pole problem. Reinforcement learning algorithms learn with success or failure and keep updating with success. Such methods of implementation have a very high scope in the future for numerous applications, and it is worth learning them.
In this article, we had a brief introduction to reinforcement learning. We understood some of the essential and significant concepts related to this topic. We also briefly looked at some of the algorithms and policies that we can potentially utilize for constructing numerous projects and solving tasks related to reinforcement learning. Finally, we constructed a deep reinforcement learning project with the help of OpenAI gym environment, TensorFlow and Keras deep learning frameworks, and the Keras-RL library. I would recommend trying out different variations and checking out the performance of the models. We will learn about a couple more ways to solve RL projects in the next article.
In the upcoming article, we will look at a couple more projects that we can construct with reinforcement learning, allowing us to explore the endless possibilities of the different types of tasks that we can accomplish with this area of machine learning. Until then, keep working on new and unique projects!












{kind=link}