

Bring this project to life
Haze is a common atmospheric phenomenon that can impair daily life and machine vision systems. The presence of haze reduces the scene’s visibility and affects people’s judgment of the object, and thick haze can even affect daily activities like with traffic safety. For computer vision, haze degrades the quality of the captured image in most cases through partial or complete occlusion of objects. It can impact the model’s reliability in high-level vision tasks, further misleading machine systems, such as autonomous driving. All these make Image Dehazing a meaningful low-level vision task.

Therefore, many researchers try to recover high-quality clear scenes from hazy images. Before Deep Learning was widely used in Computer Vision tasks, Image Dehazing algorithms had mainly relied on various prior assumptions and atmospheric scattering models. The processing flow of these statistical rule-based methods has good interpretability, but they may exhibit shortcomings when faced with complex real-world scenarios. Thus most recent efforts in Image Dehazing have employed Deep Learning models.
In this article, we will cover the mathematical basis of Image Dehazing and discuss the different categories of Dehazing. We will take a look at the most popular Image Dehazing architectures proposed in the Deep Learning literature and discuss the applications of Image Dehazing in detail.
Mathematical Modeling of Image Dehazing
The atmospheric scattering model has been the classical description for the hazy image generation process, which can be mathematically defined as follows:

Here, I(x) is an observed hazy image, and J(x) is the scene radiance (“clean image”) to be recovered. There are two critical parameters: A denotes the global atmospheric light, and t(x) is the transmission matrix defined as the following, with scattering coefficient “β” and distance between the object and the camera d(x):

The idea behind this mathematical model is that light gets scattered by the suspended particles in the air (haze) before reaching the lens of the camera. The amount of light actually captured depends both on how much haze is present, which is reflected in β, and also how far the object is from the camera, reflected in d(x).
Deep Learning models try to learn the transmission matrix. The atmospheric light is calculated separately, and the clean image is recovered based on the atmospheric scattering model.
Evaluation Metrics for Image Dehazing
Visual cues are not enough to evaluate and compare the performance of different Dehazing methods since they are very subjective in nature. A universal quantitative measure of Dehazing performance is required to compare models in a fair way.
Peak Signal-to-Noise Ratio (PSNR) and Structural SIMilarity (SSIM) Index are the two most commonly used evaluation metrics for evaluating Dehazing performance. Generally, both the PSNR and SSIM metrics are used for a fair evaluation of dehazing methods compared to the state-of-the-art.
Let us discuss these metrics next.
PSNR
Peak Signal-to-Noise Ratio or PSNR is an objective metric that measures the degree of signal distortion between a haze-free image obtained by a dehazing algorithm and the ground truth image. Mathematically it is defined by the following, where “DH” represents the dehazed image obtained from the model, and “GT” represents the ground truth clean image:

Here, “MSE” represents the pixel-wise Mean Squared Error between the images, and “M” is the maximum possible value of a pixel in an image (for 8-bit RGB images, we are used to M=255). The higher the value of PSNR (in decibels/dB), the better the reconstruction quality. In Python3 PSNR can be coded like the following:
import numpy as np
from math import log10
def PSNR(img1, img2):
mse = np.mean((img1 - img2) ** 2)
if(mse == 0): # MSE is zero means no noise is present in the signal .
# Therefore PSNR have no importance.
return 100
max_pixel = 255.0
psnr = 10 * log10(max_pixel**2 / mse)
return psnrSSIM
Since PSNR is not effective in terms of human visual judgment, therefore, many researchers utilized the Structural SIMilarity index metric (SSIM), which is a subjective measure that evaluates the dehazing performance in terms of contrast, luminance, and structural coherence between ground truth and dehazed images.


SSIM ranges between 0 and 1, where a higher value indicates greater structural coherence and thus better Dehazing results. In Python3, the skimage package contains the SSIM function, which can be easily used:
from skimage.metrics import structural_similarity as ssim
similarity = ssim(img1, img2)Single vs. Multi Image Dehazing
Two types of Image Dehazing methods exist depending on the amount of input information available. In Single Image Dehazing, only one hazy image is available, which needs to be mapped to its dehazed counterpart. In Multi Image Dehazing, however, multiple hazy images of the same scene or object are available, which are all used to map to a single dehazed image.
In Single Image Dehazing methods, since the amount of input information available is less, fake patterns may emerge in the reconstructed dehazed image, which has no discernible link to the context of the original image. This can create ambiguity which in turn can lead to the misguidance of the final (human) decision-makers.
In fully supervised Multi Image Dehazing methods, typically, different degradation functions are used on the clean image (the ground truths) to obtain slightly different types of hazy images for the same scene. This helps the model make better generalizations due to the diversity of available information.
Intuitively, we can understand that Multi Image Dehazing performs better since it has more input information to work with. However, in such cases, the computational cost is also increased several times, making it infeasible in many application scenarios with a substantial resource constraint. Also, obtaining multiple hazy images of the same object is often tedious and not practical. Thus, Single Image Dehazing is more closely related to the real world in applications like surveillance, underwater exploration, etc., although it is a more challenging problem statement.
In some application areas, however, like in Remote Sensing, several hazy images for the same scene are often readily available since multiple satellites with multiple cameras (often at different exposure settings) capture images of the same location at the same time.
One method that uses Multi Image Dehazing is the CNN-based RSDehazeNet model to remove haze from multispectral remote sensing data. RSDehazeNet consists of three types of modules:
- Channel Refinement Block or CRB, to model the interdependencies among the channel features since the channels of multispectral images are highly correlated
- Residual Channel Refinement Block or RCRB, since CNN models with residual blocks are capable of capturing weak information, driving the network to converge much faster with superior performance.
- Feature Fusion Block (FFB) for the global fusion of the feature maps and dehazing of multispectral RS images.
The architecture of the RSDehazeNet model is shown below.

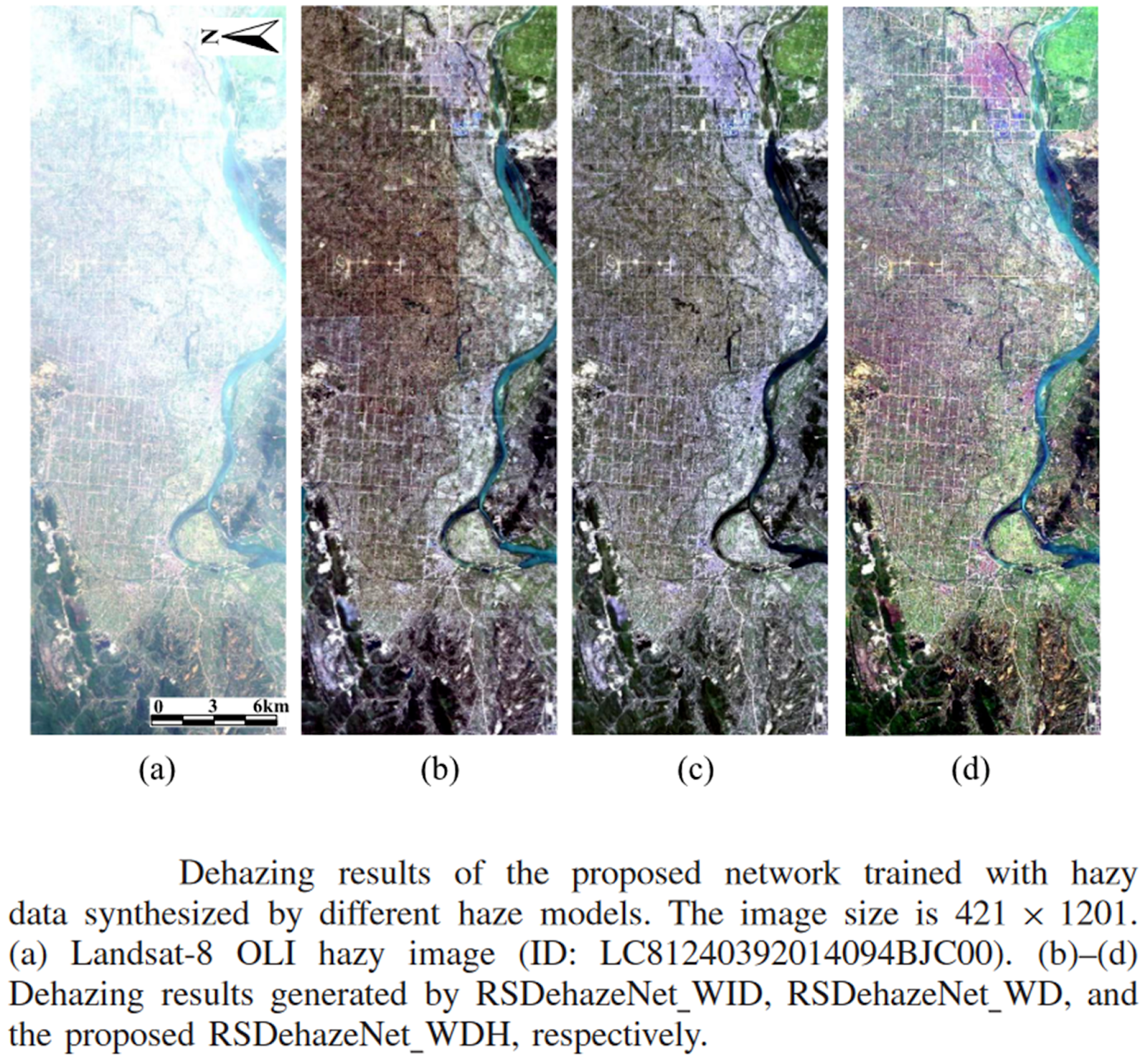
Some results obtained by the RSDehazeNet model are shown below.
Categorization of Dehazing Methods
Based on the availability of ground truth images for the hazy input images, Image Dehazing methods can be categorized into the following:
- Supervised Methods
- Semi-Supervised Methods
- Unsupervised Methods
Let us discuss these methods next.
Supervised Methods
In fully Supervised Methods, the dehazed images corresponding to the hazy images are all available for training the network. Supervised dehazing models usually require different types of supervision information to guide the training process, such as transmission map, atmospheric light, haze-free image label, etc.
FAMED-Net or Fast and Accurate Multi-Scale Dehazing Network is one such supervised method that addresses the Single Image Dehazing problem, where the aim was inference speed of the network. FAMED-Net consists of a fully convolutional end-to-end multi-scale network (with three differently scaled encoders) to efficiently process hazy images of arbitrary size. The architecture of the FAMED-Net model is shown below.

Semi-Supervised Methods
Semi-Supervised Learning is a Machine Learning paradigm where a small subset (say 5-10% of the data) of a large dataset contains ground truth labels. Thus, a model is subjected to a large quantity of unlabeled data along with a few labeled samples for network training. Compared to fully supervised methods, semi-supervised methods have received less attention in the context of Image Dehazing.
PSD or Principled Synthetic-to-Real Dehazing is a semi-supervised dehazing model that consists of two phases: supervised pre-training and unsupervised fine-tuning. For the pre-training, the authors used synthetic data and used the real hazy unlabeled data for the unsupervised fine-tuning, employing unsupervised Domain Adaptation for the synthetic to real image translation. The model framework is shown below.

Some visual results obtained by the PSD method compared to the state-of-the-art are shown below.

Supervised Methods
In Unsupervised Learning, data labels are entirely missing. A deep network will need to train entirely using unstructured data. This makes the Image Dehazing problem even more challenging.
For example, SkyGAN is an unsupervised dehazing model which utilizes a Generative Adversarial Network (GAN) architecture for the dehazing of a hyperspectral image. SkyGAN uses a conditional GAN (cGAN) framework with cycle consistency, i.e., a regularization parameter is added with the assumption that a dehazed image, when degraded, should again return the hazy input image. The architecture of the SkyGAN model is shown below.

Results obtained by the SkyGAN model are impressive, as they surpass even fully supervised methods. Some of the visual results obtained are shown below.

The most important part of the code for a Supervised Single Dehazing problem is curating the custom dataset to get both the hazy and clean images. A PyTorch code for the same is shown below:
import torch
import torch.utils.data as data
import torchvision.transforms as transforms
import numpy as np
from PIL import Image
import os
class DehazingDataset(data.Dataset):
def __init__(self, hazy_images_path, clean_images_path, transform=None):
#Get the images
self.hazy_images = [hazy_images_path + f for f in os.listdir(hazy_images_path) if f.endswith('.jpg') or f.endswith('.png') or f.endswith('.jpeg')]
self.clean_images = [clean_images_path + f for f in os.listdir(clean_images_path) if f.endswith('.jpg') or f.endswith('.png') or f.endswith('.jpeg')]
#Filter the images to ensure they are counterparts of the same scene
self.filter_files()
self.size = len(self.hazy_images)
self.transform=transform
def filter_files(self):
assert len(self.hazy_images) == len(self.clean_images)
hazy_ims = []
clean_ims = []
for hazy_img_path, clean_img_path in zip(self.hazy_images, self.clean_images):
hazy = Image.open(hazy_img_path)
clean = Image.open(clean_img_path)
if hazy.size == clean.size:
hazy_ims.append(hazy_img_path)
clean_ims.append(clean_img_path)
self.hazy_images = hazy_ims
self.clean_images = clean_ims
def __getitem__(self, index):
hazy_img = self.rgb_loader(self.hazy_images[index])
clean_img = self.rgb_loader(self.clean_images[index])
hazy_img = self.transform(hazy_img)
clean_img = self.transform(clean_img)
return hazy_img, clean_img
def rgb_loader(self, path):
with open(path, 'rb') as f:
img = Image.open(f)
return img.convert('RGB')
def __len__(self):
return self.size
#Main code for dataloader
hazy_path = "/path/to/train/hazy/images/"
clean_path = "/path/to/train/clean/images/"
transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])
])
dataset = DehazingDataset(hazy_path, clean_path, transform = transforms)
data_loader = data.DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)Once the dataset is ready, any image-to-image translation model code can be applied to it.
Popular Models
Several different Deep Learning-based model architectures have been proposed over the years to address the Image Dehazing problem. Let us discuss some of the major models that have served as stepping stones for future research directions. Most of these models also have their Python implementations available in their respective GitHub repositories.
If you want to use any of the following code with Gradient, simply open the link below and clone the repository into the Notebook. This Notebook comes pre-set up with the code used above.
Bring this project to life
MSCNN
MSCNN, or Multi-Scale Convolutional Neural Network, is one of the early attempts at the Single Image Dehazing problem. As the name suggests, MSCNN is multi-scale in nature to help learn effective features from hazy images for the estimation of the scene transmission map. The scene transmission map is first estimated by a coarse-scale network and then refined by a fine-scale network.
The coarse structure of the scene transmission map for each image is obtained from the coarse-scale network and then refined by the fine-scale network. Both coarse and fine-scale networks are applied to the original input hazy image. In addition, the output of the coarse network is passed to the fine network as additional information. Thus, the fine-scale network can refine the coarse prediction with details. The architecture of the MSCNN model is shown below.

Some examples of results obtained by the MSCNN results compared to some baseline methods at the time are shown below.

DehazeNet
DehazeNet is another early method that addresses the Single Image Dehazing problem. The code for DehazeNet may be found here. DehazeNet is a system that learns and estimates the mapping between the hazy patches in the input image and their medium transmissions. A simple CNN model is used for feature extraction, and a multi-scale mapping is used to achieve scale invariance.
DehazeNet is a fully supervised approach where clean natural scene images were degraded manually to model hazy input images by using the depth meta-data. The model architecture of DehazeNet is shown below.

Some results obtained by the DehazeNet model as compared to the then state-of-the-art methods are shown below.

AOD-Net
AOD-Net or All-in-One Dehazing Network is a popular end-to-end (fully supervised) CNN-based image dehazing model. An implementation of this code may be found here. The major novelty of AOD-Net is that it was the first model to optimize the end-to-end pipeline from hazy to clean images rather than an intermediate parameter estimation step. AOD-Net is designed based on a re-formulated atmospheric scattering model. The clean image is obtained from the atmospheric scattering model using the following equation:

Unlike DehazeNet, which uses end-to-end Learning from the hazy image to the transmission matrix, AOD-Net uses a deep end-to-end model for the image dehazing operation. The architecture diagram of the AOD-Net model is shown below.
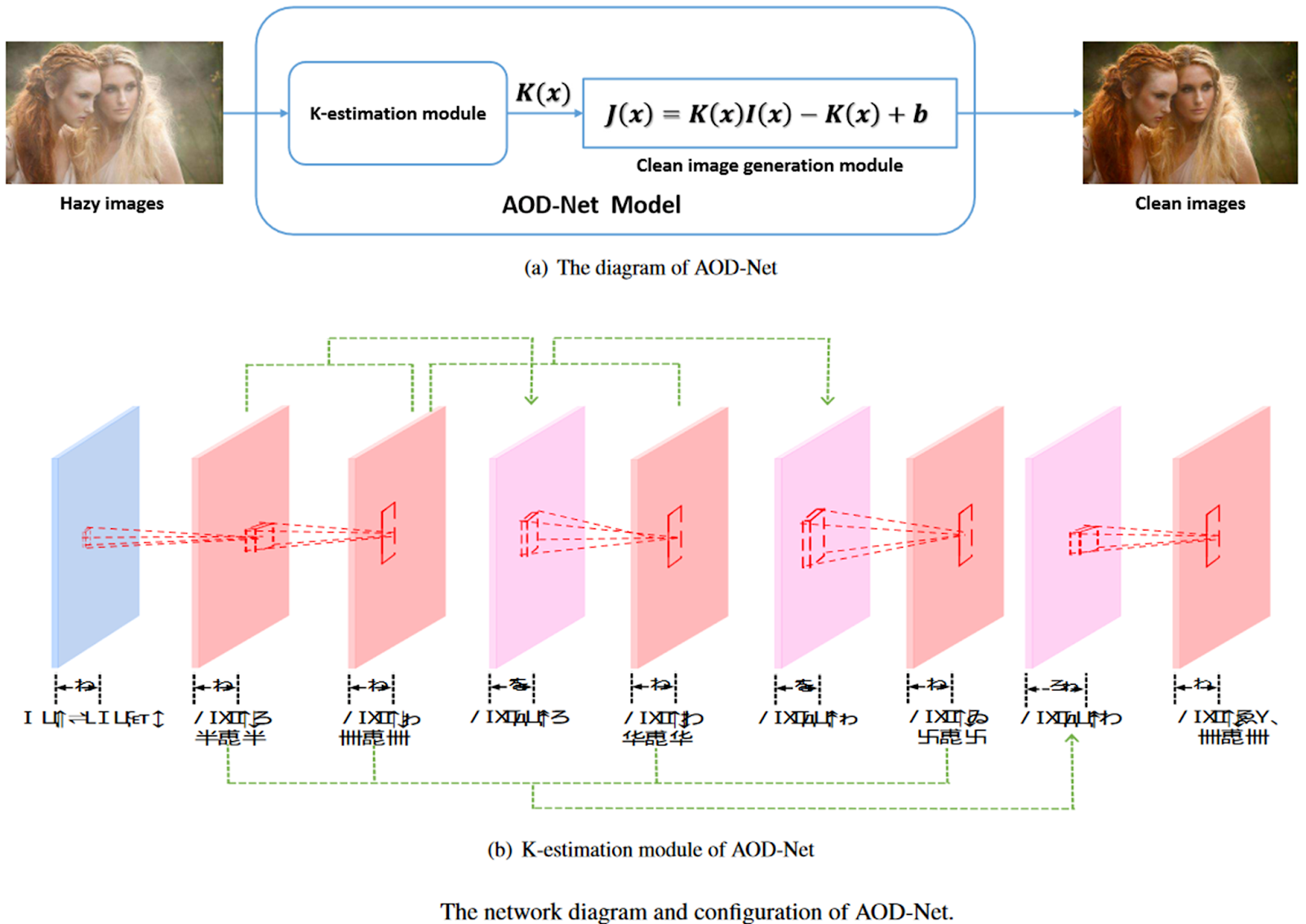
Some results obtained by the AOD-Net model are shown below.

DCPDN
DCPDN or Densely Connected Pyramid Dehazing Network is an image dehazing model that utilizes a Generative Adversarial Network architecture for haze removal. The code for this model may be found here. The DCPDN model learns structural relations from the images and consists of an encoder-decoder structure, which can be jointly optimized to estimate the transmission map, atmospheric light, and also image dehazing simultaneously. Along with this, the atmospheric model is included in the architecture for better optimization of the overall learning process.
However, training such a complex network (with three different tasks) is very computationally expensive. Thus, to ease the training process and accelerate network convergence, DCPDN leverages a stage-wise learning technique. First, each part of the network is progressively optimized, and then the entire network is jointly optimized. The main aim of the GAN architecture is to exploit the structural relationship between the transmission map and the dehazed image. The architecture of the DCPDN model is shown below.

The joint discriminator in the diagram shown above distinguishes whether a pair of estimated transmission maps and dehazed images is a real or fake pair. Further, to guarantee that the atmospheric light can also be optimized within the whole structure, a U-net is adopted to estimate the homogeneous atmospheric light map. Moreover, a multi-level pyramid pooling block is adopted to ensure that features from different scales are embedded efficiently in the final result.
Some results obtained by the DCPDN model as compared to the state-of-the-art models are shown below.

FFA-Net
FFA-Net or Feature Fusion Attention Network is a relatively new Single Image Dehazing network that uses an end-to-end architecture to directly restore the haze-free image. The code for this model can be found here. Most of the earlier models treated the channel-wise and pixel-wise features equally. However, haze is unevenly distributed across an image; the weight of the very thin haze should be significantly different from that of the thick haze region pixels.
The novelty of FFA-Net lies in the fact that it treats the thin haze and thick haze regions differently, thus saving resources by avoiding unnecessary computations for less important information. This way, the network is able to cover all the pixels and channels, and the representation of the network is not hindered.
FFA-Net attempts to retain shallow features and pass them into the deeper layers of the architecture. The model also gives different weights to different level features before feeding all features to the fusion module. The weights are obtained by adaptive Learning of the Feature Attention module (which consists of a cascade of Channel Attention and Pixel Attention modules). The architecture diagram of the FFA-Net model is shown below.

Some of the dehazing results obtained by the FFA-Net model are shown below. The python implementation for the FFA-Net model can be found here.

DehazeFormer
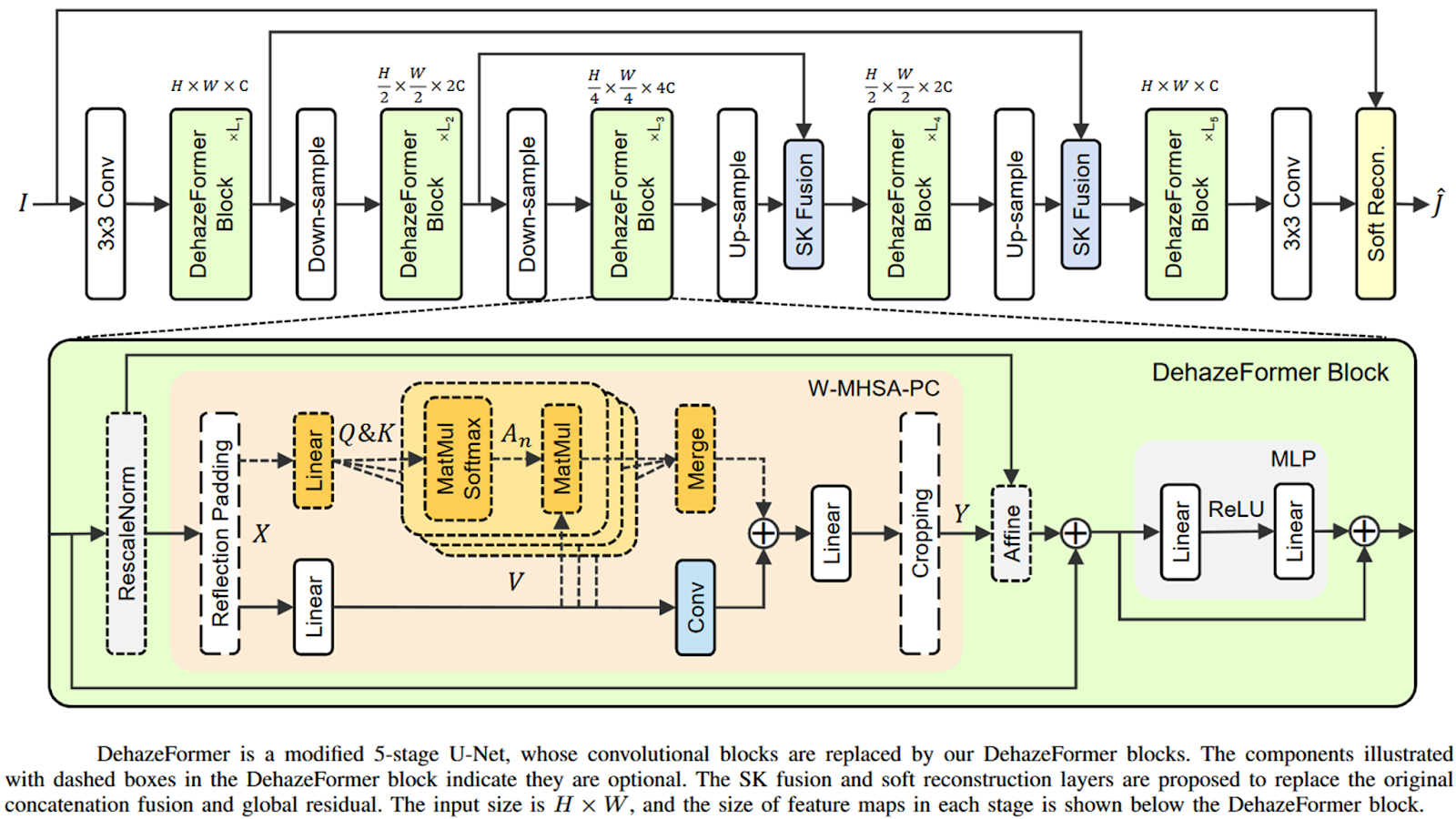
DehazeFormer is one of the latest Single Image Dehazing deep models proposed in the literature. The code for implementing this can be found here. It utilizes Vision Transformers (ViT) in its core, specifically the Swin Transformer. CNN has dominated most computer vision tasks for years, while recently, the ViT architectures show the capability of replacing CNNs. ViT pioneered the direct application of the Transformer architecture, which projects images into token sequences via patch-wise linear embedding.
DehazeFormer uses a U-Net type encoder-decoder architecture, but the convolution blocks are replaced by DehazeFormer blocks. The DehazeFormer uses the Swin Transformer model with several improvements on it, like replacing the LayerNorm normalization layer with a new “RescaleNorm” layer proposed in the same paper. RescaleNorm performs normalization on the entire feature map and reintroduces the mean and variance of the feature map lost after normalization.
Furthermore, the authors proposed a prior-based soft reconstruction module that outperforms global residual Learning and a multi-scale feature map fusion module (as used in the MSCNN and FFA-Net architectures) based on SKNet to replace concatenation fusion.
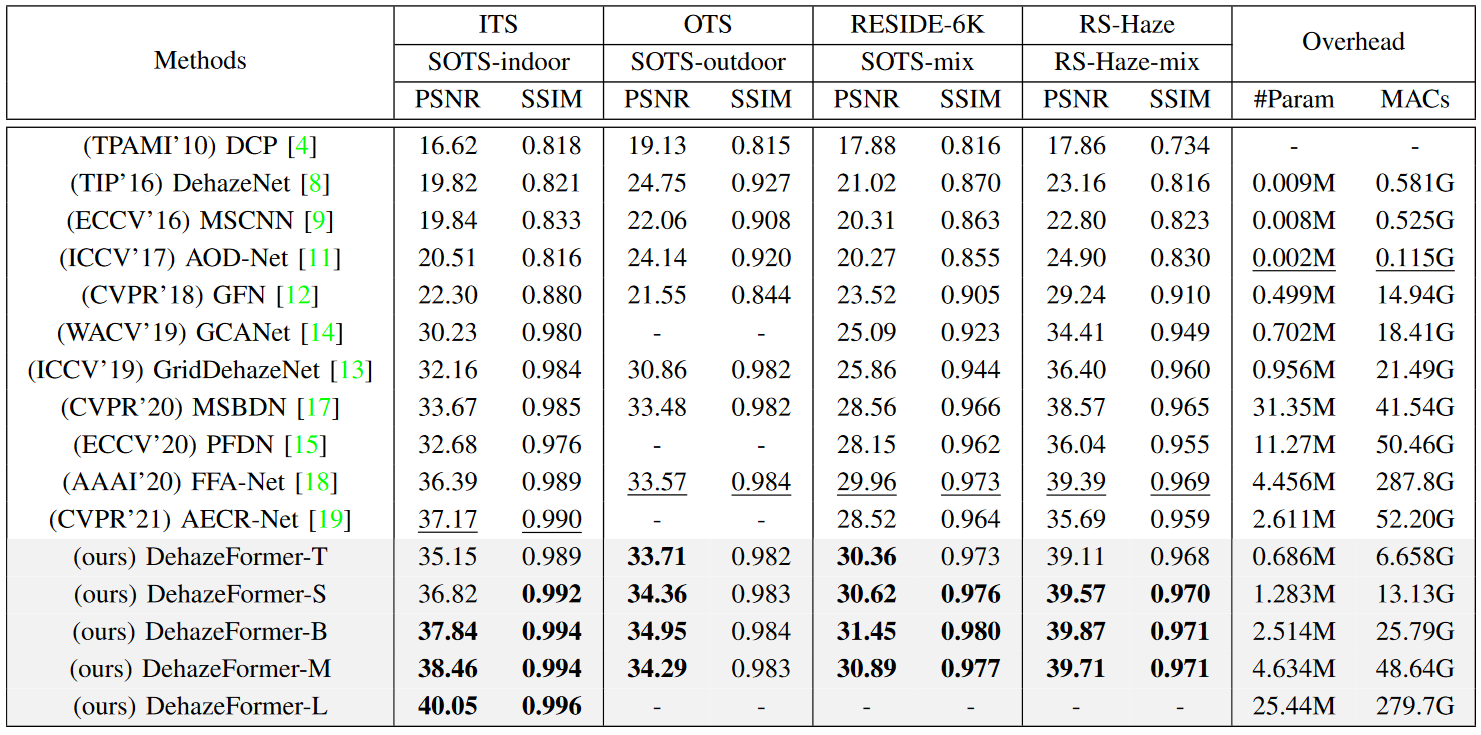
The DehazeFormer model substantially outperforms contemporary methods, most of which use Convolutional Networks with a lower overhead which is evident from the quantitative results shown below. Some qualitative results obtained by the DehazeFormer model are also shown below.

TransWeather
TransWeather is the most recent Deep Learning architecture in the Image Dehazing literature. You can access the code for this model here. It is a general-purpose model that uses a single encoder-single decoder transformer network to tackle all adverse weather removal problems (rain, fog, snow, etc.) at once. Instead of using multiple encoders, the authors introduced weather-type queries in the transformer decoder to learn the task.
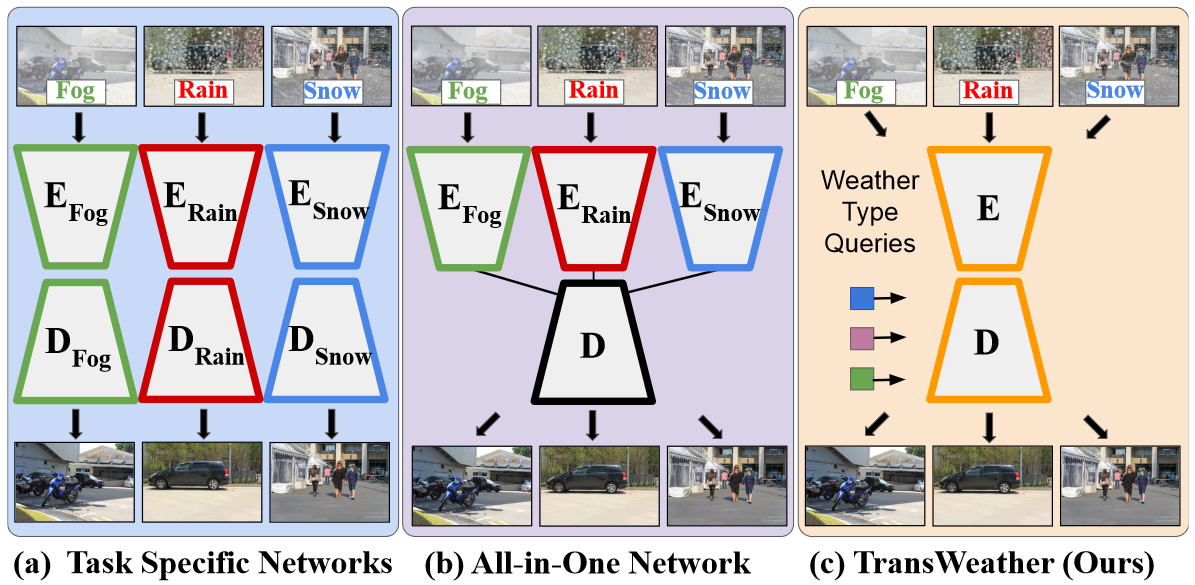
The TransWeather model consists of a novel transformer encoder with intra-patch transformer (Intra-PT) blocks. Intra-PT works on sub-patches created from the original patches and excavates features and details of smaller patches. Intra-PT thus focuses on the attention inside the main patches to remove weather degradations effectively. The authors also use efficient self-attention mechanisms to calculate the attention between sub-patches to keep the computational complexity low. The architecture of the TransWeather model is shown below.

Some qualitative results obtained by the TransWeather model are shown below.

Applications of Image Dehazing
Image dehazing is an important task in Computer Vision due to its wide range of applications in the real world. Let us look at some of the most important applications of Image Dehazing next.
- Surveillance: Surveillance using images or videos (which are, essentially, a sequence of images) is vital for security. The effectiveness and accuracy of the visual surveillance system depend on the quality of visual inputs. Adverse weather conditions can render surveillance systems useless, thus making Image Dehazing an important operation in this area.
- Intelligent Transportation System: Foggy weather conditions affect the driver’s capabilities and significantly increase the risk of accidents and travel time due to limited visibility. Generally, takeoff and landing of airplanes become a very challenging task in a hazy environment too. With the advent of autonomous driving technology, Image Dehazing is an indispensable operation for auto-pilot cars or planes to function without problems.
- Underwater Image Enhancement: Underwater imaging often suffers poor visibility and color distortions. The poor visibility is produced by the haze effect due to the scattering of light by water particles multiple times. Color distortion is due to the attenuation of light and makes an image bluish. Therefore, an underwater vision system that is prevalent in marine biology research requires an Image Dehazing algorithm as a preprocessing so that humans can see the underwater objects. For example, this paper specifically deals with the problem of underwater image dehazing, the results of which are shown below.
- Remote Sensing: In remote sensing, images are captured to obtain information about objects or areas. These images are usually taken from satellites or aircraft. Due to the high difference in distance between the camera and the scene, the haze effect is introduced in the captured scene. Therefore, this application also demands image dehazing as a preprocessing tool to improve the visual quality of an image before analysis.


Conclusion
Image Dehazing is a critical task in Computer Vision due to its applications in areas like security and autonomous driving, where clean dehazed images are necessary for further information processing. Several deep learning models have been proposed over the years to tackle this problem, most of which have used fully supervised Learning. CNN-based architectures were the go-to method until recently transformer models obtained much better performance.
Recent research in the domain focuses on reducing the requirement for supervision (labeled data) in Image Dehazing. Although natural images are degraded using a mathematical function to mimic hazy images, it is still not an accurate representation. Thus, to reliably remove haze from images, original hazy images are required along with their dehazed counterparts for supervised Learning. Methods like Self-Supervised Learning and Zero-Shot Learning alleviate this requirement completely and thus have become the subject of recent research.











