
As many readers here will know, Paperspace makes it easy to access GPU compute power either directly with virtual machines on Paperspace Core, or via Notebooks, Workflows, and Deployments on Paperspace Gradient.
An obvious extension to enabling access to single GPUs is to scale up to multiple GPUs on one machine, and to multiple machines.
Here, we show how the first of those, multi-GPU on one machine, works on Gradient by running distributed training on TensorFlow using the TensorFlow distribution strategies. We also show that both simple and custom training loops can be implemented.
A key point to note here is that no special setup was required to do this: a regular Gradient container, and a multi-GPU Notebook instance that is available to users are all that is needed.
TensorFlow Distribution Strategies
TensorFlow Distribution Strategies is their API that allows existing models to be distributed across multiple GPUs (multi-GPU) and multiple machines (multi-worker), by placing existing code inside a block that begins with with strategy.scope(): .
strategy indicates that we are using one of TensorFlow's current strategies to distribute our model:
- MirroredStrategy
- TPUStrategy
- MultiWorkerMirroredStrategy
- ParameterServerStrategy
- CentralStorageStrategy
Each of these represents a different way of distributing the hardware and the compute, and they have various advantages and disadvantages depending upon the problem to be solved.
Our primary focus here will be arguably the most commonly used and simplest one, MirroredStrategy. This allows model training on multiple GPUs on one machine, and the training is synchronous, meaning that all parts, such as gradients, are updated after each step.
Looking briefly at the others:
TPUStrategy is very similar, but only works for Google's tensor processing unit (TPU) hardware.
MultiWorkerMirroredStrategy generalizes MirroredStrategy to multiple machines, i.e., workers.
ParameterServerStrategy represents another method of distribution besides mirroring, where each part of the model that is on its own machine can have its own variables. This is asynchronous training. The values of the variables are coordinated on a central machine, the parameter server.
Finally, CentralStorageStrategy is similar, but places variables on the CPU rather than mirroring them.
The strategies are showcased on TensorFlow's site via a set of tutorials, supplied in a variety of formats. These include .ipynb Jupyter Notebooks, which we will run below.
Simple and complex models
TensorFlow models come in varying levels of complexity, and the levels can be categorized in several ways. In particular, aside from the distribution strategies, the tutorials on their site can be divided into
- Simple training loops
- Custom training loops
where a training loop is the process by which the model is trained. Custom training loops provide more general and fine-grained functionality, but take more code to implement than simple training loops. Real problems often have some requirement that means a custom loop is needed.
For multi-GPU, however, using a custom loop means the implementation is more complex than just enclosing existing single-GPU code in a with strategy.scope(): block. For example, model loss functions have to be defined differently when their components are coming from several jobs being run in parallel. Model forms that are not the straightforward case of supervised learning, such as GAN, reinforcement learning, etc., are also custom loops.
While we don't attempt to reproduce all the details here, we show that both simple and custom training loops work within Gradient, both on a single-GPU, and multi-GPU.
Running the TensorFlow Distribution Strategies on Gradient
Following the title of this post, here we focus on running multi-GPU on one machine, which corresponds to MirroredStrategy, as described above. We show both the simple and custom training loops.
Running MirroredStrategy
We demonstrate 2 .ipynb Jupyter notebooks from TensorFlow's distributed tutorials, slightly modified to run better on Gradient:
keras.ipynb, from the Distributed Training with Keras tutorialcustom_training.ipynb, from the Custom Training tutorial
Setup
To run on Gradient, we create a project, then start a new notebook instance, selecting the TensorFlow container, and a machine that has multi-GPU.
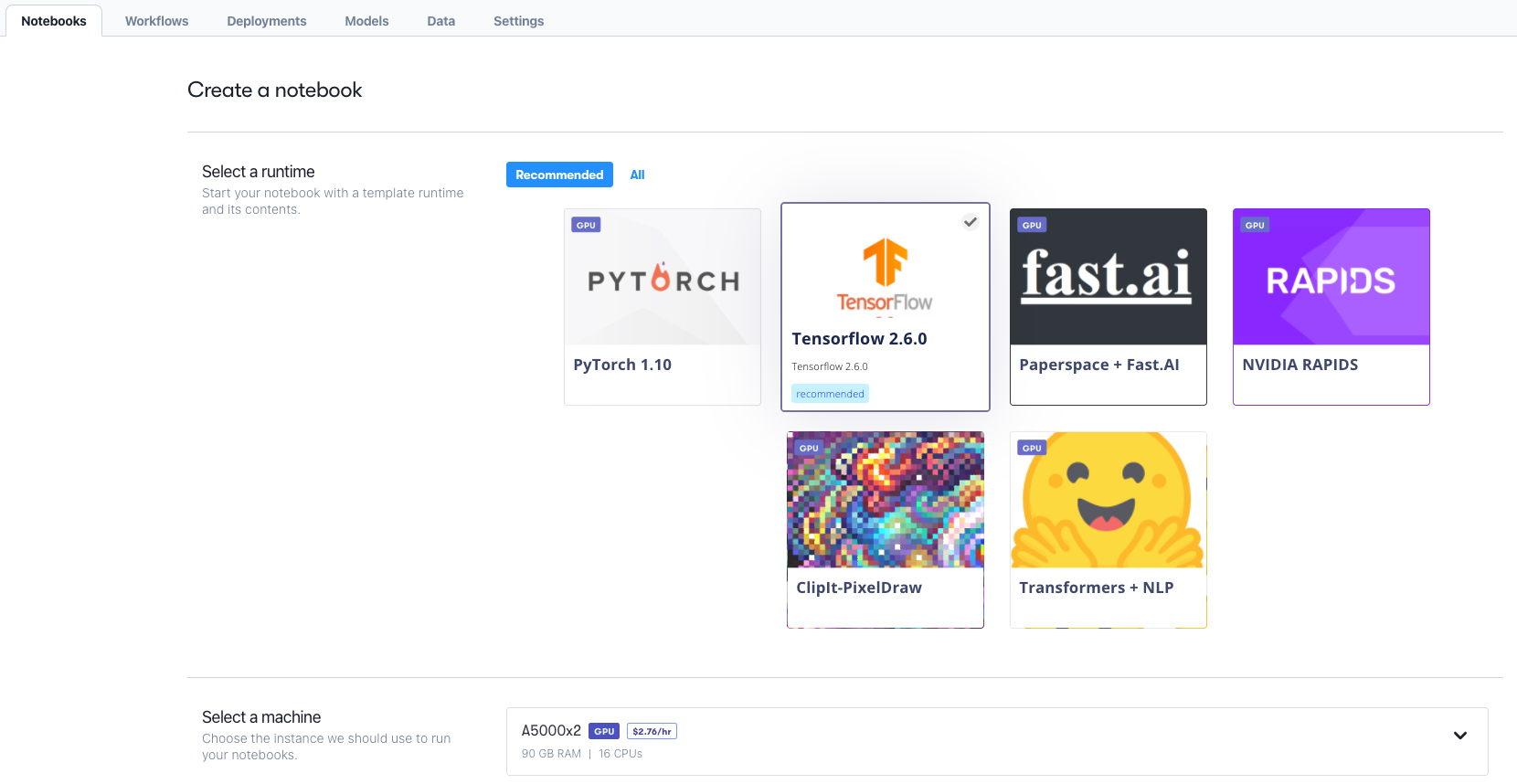
Here, we are using two Ampere A5000s. In the advanced options, we select the workspace to be our repo containing the three notebooks.
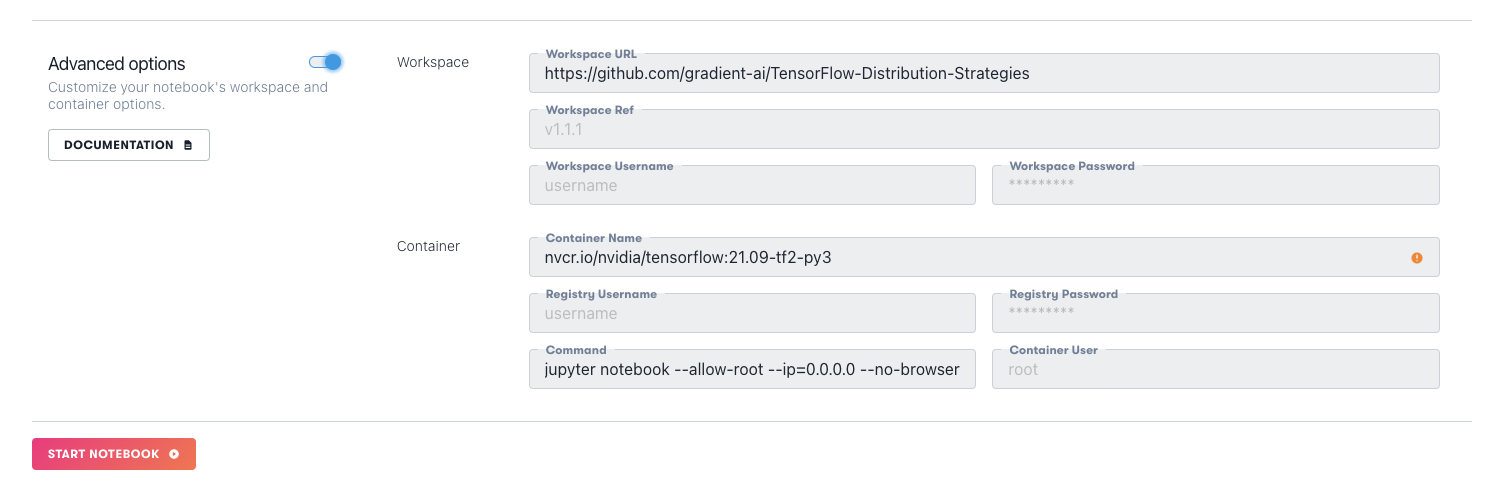
Our multi-GPU notebooks are then ready to run.
Bring this project to life: click to open keras.ipynb with Gradient!
keras.ipynb
This shows a simple model using TensorFlow's high-level Keras interface.
Using nvidia-smi and TensorFlow's own functionality, we see that both GPUs are present
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
# Output:
# Number of devices: 2The data used is the MNIST data from TensorFlow datasets.
The distribution strategy is defined using strategy = tf.distribute.MirroredStrategy().
The model is built in the usual format, but inside the block with strategy.scope():
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])The tutorial then shows callbacks, model training & evaluation, and saving to the SavedModel format.
Bring this project to life: click to open custom_training.ipynb in Gradient!
custom_training.ipynb
In this tutorial, the overall structure is similar, but now we use custom loops instead of the simple ones in keras.ipynb. It also uses the Fashion-MNIST dataset rather than the original one.
The loss function now has to be defined, because it is combining the calculated losses from the replicas across the multiple GPUs.
with strategy.scope():
# Set reduction to `none` so we can do the reduction afterwards and divide by
# global batch size.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction=tf.keras.losses.Reduction.NONE)
def compute_loss(labels, predictions):
per_example_loss = loss_object(labels, predictions)
return tf.nn.compute_average_loss(per_example_loss, global_batch_size=GLOBAL_BATCH_SIZE)Similarly, performance metrics such as loss and accuracy have to be calculated.
The tutorial then shows the training loop, checkpoints, and some alternative ways of iterating over a dataset. You can follow along with the rest of the tutorial notebooks here, or by creating a Gradient Notebook using the previous link as the Workspace URL for the notebook create page.
Gradient Removes Setup Overhead
As we have now seen, training models and performing other operations with them in a distributed setting can be more complex than using a single CPU or GPU. It is thus to our benefit that Gradient has removed the burden of setting up the GPUs and installing the ML software, allowing us to go straight to coding.
This opens up further uses, where, for example, users who didn't write the code but nevertheless want to use the models, can do so via their being in production, an application, or some other use case. The underlying distributed hardware and GPUs can continue to be run on Gradient.
Conclusions
We have shown that TensorFlow Distribution Strategies work on Gradient, including:
MirroredStrategyon single GPUMirroredStrategyon multi-GPU- Simple model training on both of these
- Custom training loops on both of these
In the future, when multi-node support is added to Gradient, it will be able to support MultiWorkerMirroredStrategy, ParameterServerStrategy, and CentralStorageStrategy, in addition to those covered in this blog post.
Next Steps
You can try these out for yourself by following along with the GitHub repository for this blog entry at https://github.com/gradient-ai/TensorFlow-Distribution-Strategies .
This contains copies of their two notebooks, modified slightly from the TensorFlow originals so that they work on Gradient, and as run above.
For more and detailed information on distribution strategies, see these notebooks, or TensorFlow's distribution strategies guide. The guide contains a notebook, distributed_training.ipynb, that will also run on Gradient, although it overlaps with some of the above.
After that, the use of TensorFlow distributed strategies and Gradient shown is very generic, so there is a wide range of potential projects that could be done.
Appendix: A note on MultiWorkerMirroredStrategy and ParameterServerStrategy
TensorFlow's tutorials show both of these strategies working via localhost on one machine rather than requiring the user to have actual multiple machines. This means that they do, in fact, also run on Gradient as written. However, the normal usage of mirrored multi-workers and parameter servers would involve using multiple machines, or nodes. Since that is not currently supported we haven't attempted to show it in this blog entry.










