Implementation StyleGAN2 from scratch
In this article, we will make a clean, simple, and readable implementation of StyleGAN2 using PyTorch.
3 years ago
In this article, we will make a clean, simple, and readable implementation of StyleGAN2 using PyTorch.
This tutorial discusses fine-tuning the powerful MPT-7B model from MosaicML using Paperspace's powerful cloud GPUs!
In this article, we will make a clean, simple, and readable implementation of StyleGAN using PyTorch.
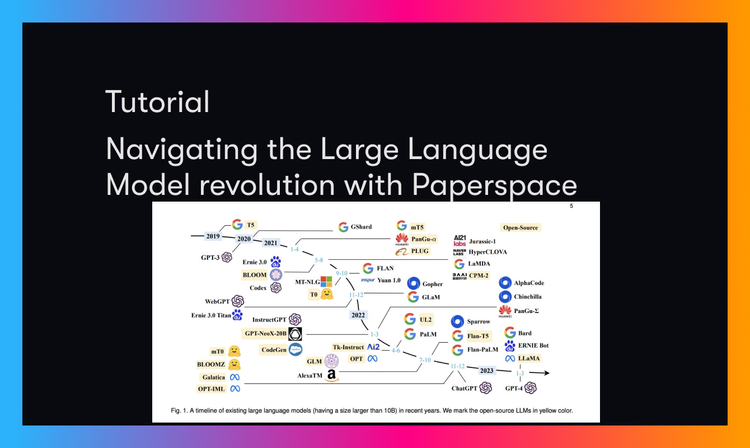
In this article, we attempt to navigate the rapidly expanding ecosystem of LLM's by identifying and explaining relevant key terms and upcoming models. We concluded by showing how to launch any HuggingFace Space, a popular host for LLMs, within Paperspace.
This article covers the Rodin diffusion model for creating 3D avatars from neyral radiance fields (NeRFs).
This is a review of the CausalML package, a Python package that provides a suite of uplift modeling and causal inference methods using machine learning algorithms based on recent research.
In this article, we take a deeper look at Neural Articulated Radiance Fields, and examine their potential for 3d modeling.
In this article, we continue our look at the theory behind recent works on transferring the capabilities of 2D diffusion models to create 3D-Aware Generative Diffusion models.
In this article, we will go through the StyleGAN paper to see how it works and understand it in depth.