Build a Transformer-based language Model Using Torchtext
In this tutorial, we show how to construct a fully trained transformer-based language model using TorchText in a Paperspace Notebook
3 years ago
In this tutorial, we show how to construct a fully trained transformer-based language model using TorchText in a Paperspace Notebook
In this review, we examine popular text summarization models, and compare and contrast their capabilities for use in our own work.
This review covers different methodologies for open-ended text generation
Follow this guide to create a conversational system with a pretrained LLM in Paperspace.
This tutorial shows how the LLaMA 2 model has improved upon the previous versions of LLaMa, and details how to run it using a Jupyter Notebook.
This tutorial discusses fine-tuning the powerful MPT-7B model from MosaicML using Paperspace's powerful cloud GPUs!
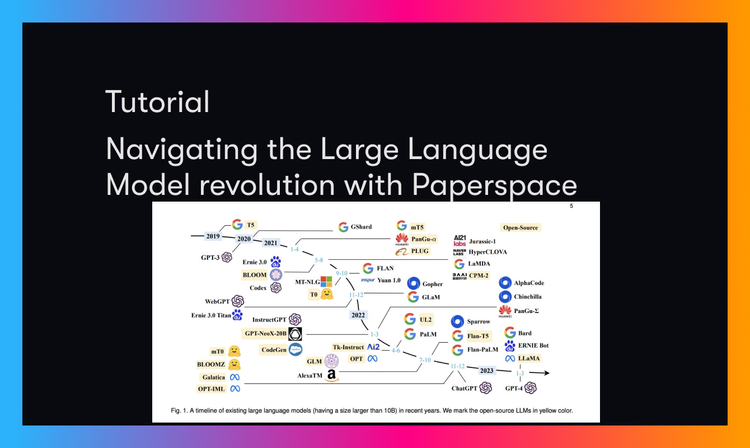
In this article, we attempt to navigate the rapidly expanding ecosystem of LLM's by identifying and explaining relevant key terms and upcoming models. We concluded by showing how to launch any HuggingFace Space, a popular host for LLMs, within Paperspace.
In this theory we cover the background theory behind a variety of methodologies for abstractive text summarization
In this article, we go over Neural Machine Translation with Bahdanau and Luong Attention, and demonstrate the value of the innovative model architecture.