
Real-time object detection has found modern applications in everything from autonomous vehicles and surveillance systems to augmented reality and robotics. The essence of real-time object detection lies in accurately identifying and classifying multiple objects within an image or a video frame in a fraction of a second.
Over the years, numerous algorithms have been developed to enhance the efficiency and accuracy of real-time object detection. The "You Only Look Once" (YOLO) series emerged as a prominent approach due to its speed and performance. The YOLO algorithm revolutionized object detection by framing it as a single regression problem, predicting bounding boxes and class probabilities directly from full images in one evaluation. This streamlined approach has made YOLO synonymous with real-time detection capabilities.
Researchers have recently focused on CNN-based object detectors for real-time detection, with YOLO models gaining popularity for their balance between performance and efficiency. The YOLO detection pipeline includes the model forward process and Non-maximum Suppression (NMS) post-processing, but both have limitations that result in suboptimal accuracy-latency trade-offs.
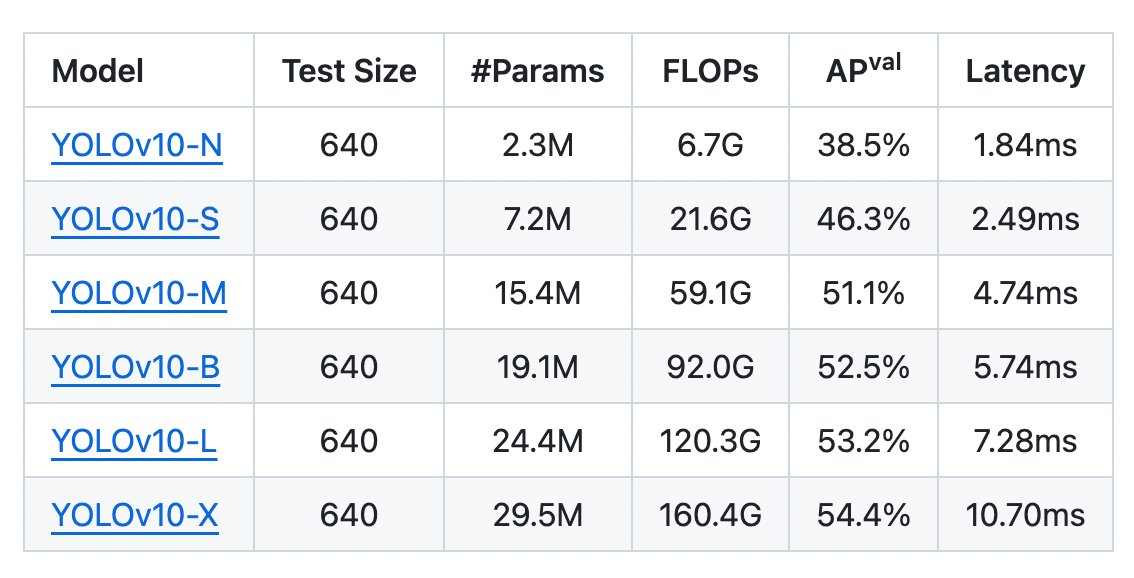
The recent addition to this YOLO series is YOLOv10-N / S / M / B / L / X, building on its predecessors, YOLOv10 integrates advanced techniques to improve detection accuracy, speed, and robustness in diverse environments. YOLOv10's enhancements make it a powerful tool for applications requiring immediate and reliable object recognition, pushing the boundaries of what is achievable in real-time detection. Experiments show that YOLOv10 significantly outperforms previous state-of-the-art models regarding computation-accuracy trade-offs across various model scales.
What is YOLOv10?
YOLO models typically use a one-to-many label assignment strategy during training, which implies that one ground-truth object corresponds to multiple positive samples. While this improves performance, non-maximum suppression (NMS) during inference is required to select the best prediction, which slows down inference and makes performance sensitive to NMS hyperparameters. This further prevents the YOLO models from achieving optimal end-to-end deployment.
As discussed in the YOLOv10 research paper, one possible solution is adopting end-to-end DETR architectures, like RT-DETR, which introduces efficient encoder and query selection techniques for real-time applications. However, DETRs' complexity can hinder the balance between accuracy and speed. Another approach is exploring end-to-end detection for CNN-based detectors using one-to-one assignment strategies to reduce redundant predictions, though they often add inference overhead or underperform.
Researchers have experimented with various backbone units (DarkNet, CSPNet, EfficientRep, ELAN) and neck components (PAN, BiC, GD, RepGFPN) to enhance feature extraction and fusion. Additionally, model scaling and re-parameterization techniques have been investigated. Despite these efforts, YOLO models still face computational redundancy and inefficiencies, leaving room for accuracy improvements.
The recent research paper addresses these challenges by enhancing post-processing and model architecture. It proposes a consistent dual assignments strategy for NMS-free YOLOs, eliminating the need for NMS during inference and improving efficiency. The research also includes an efficiency-accuracy-driven model design strategy, incorporating lightweight classification heads, spatial-channel decoupled downsampling, and rank-guided block design to reduce redundancy. For accuracy, the paper explores large-kernel convolution and an effective partial self-attention module.
YOLOV10 introduces an NMS-free training strategy for YOLO models using dual label assignments and a consistent matching metric, which helps to achieve high efficiency and competitive performance.
Advancements in YOLOv10
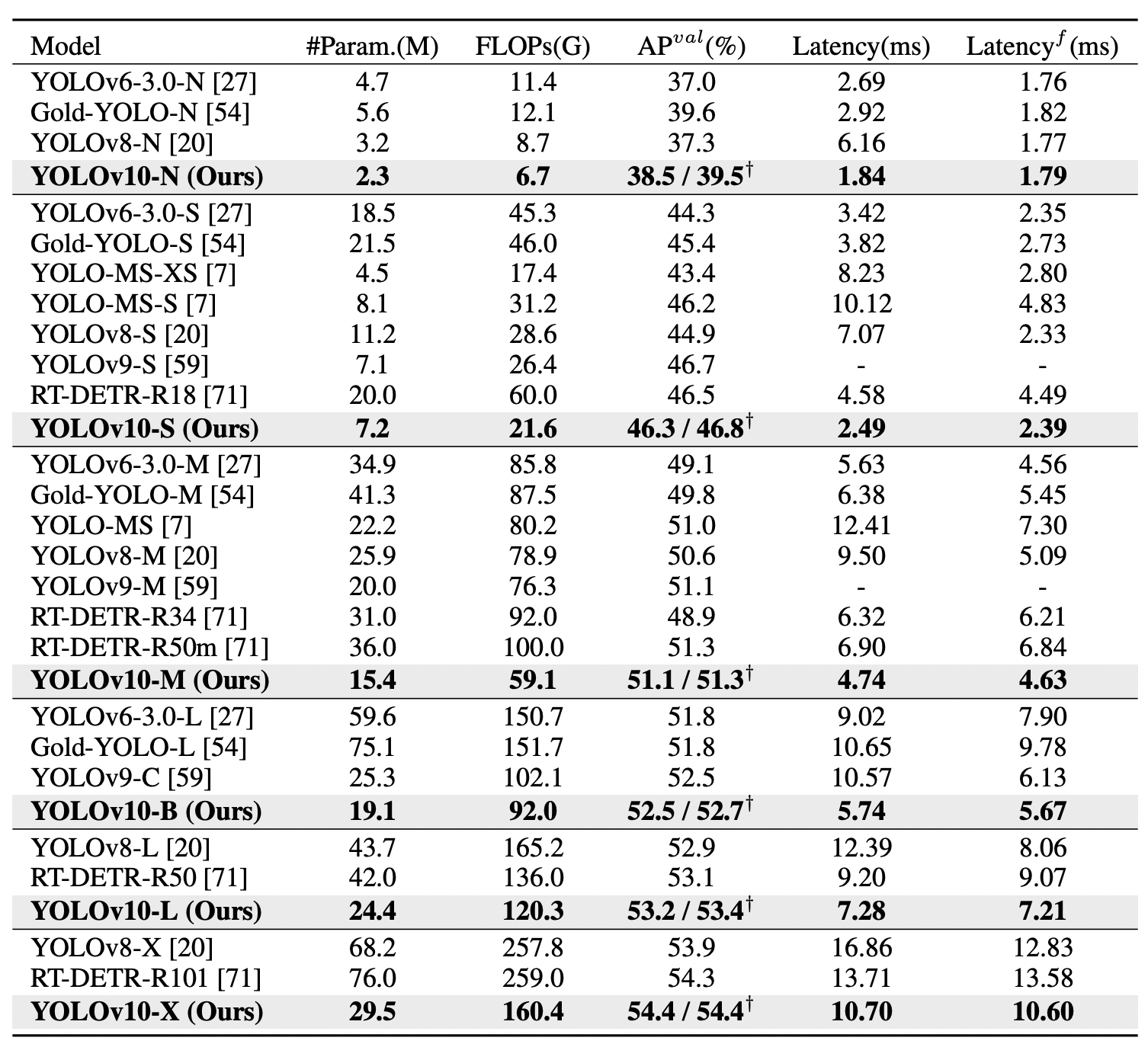
YOLOv10 (N/S/M/B/L/X) has successfully achieved significant performance improvements on COCO benchmarks. YOLOv10-S and X are notably faster than RT-DETR-R18 and R101, respectively, with similar performance. YOLOv10-B reduces latency by 46% compared to YOLOv9-C, maintaining the same performance. YOLOv10-L and X outperform YOLOv8-L and X with fewer parameters, and YOLOv10-M matches YOLOv9-M/MS performance with fewer parameters.
The six sizes of the YOLOv10 model:
Bring this project to life
The NMS-free training with consistent dual assignments cuts the end-to-end latency of YOLOv10-S by 4.63ms, maintaining a strong performance at 44.3% Average Precision or AP.
- The efficiency-driven model design reduces 11.8 million parameters and 20.8 Giga Floating Point Operations Per Second or GFLOPs, decreasing YOLOv10-M's latency by 0.65ms.
- The accuracy-driven model design also boosts AP by 1.8 for YOLOv10-S and 0.7 for YOLOv10-M, with minimal latency increases of just 0.18ms and 0.17ms, proving its effectiveness.
What are Dual Label Assignments in YOLOv10?
One-to-one matching in YOLO models assigns a single prediction to each ground truth, eliminating the need for NMS post-processing but resulting in weaker supervision and lower accuracy. To address this, dual label assignments are used which combine one-to-many and one-to-one strategies. An additional one-to-one head is introduced, identical in structure and optimization to the one-to-many branch, which is optimized jointly during training.
This allows the model to benefit from the rich supervision of one-to-many assignments while using the one-to-one head for efficient, end-to-end inference. The one-to-one matching uses top-one selection, matching Hungarian performance with less training time.
What is Consistent Matching Metric?
During the assignment of predictions to ground truth instances, both one-to-one and one-to-many approaches use a metric to measure how well a prediction matches an instance. This metric combines the classification score, the bounding box overlap (IoU), and whether the prediction’s anchor point is within the instance.
A consistent matching metric improves both the one-to-one and one-to-many matching processes, ensuring both branches optimize towards the same goal. This dual approach allows for richer supervisory signals from the one-to-many branch while maintaining efficient inference from the one-to-one branch.
The consistent matching metric ensures that the best positive sample (the prediction that best matches the instance) is the same for both the one-to-one and one-to-many branches. This is achieved by making the parameters (α and β) that control the balance between classification and localization tasks proportional between the two branches.
- Metric Formula:
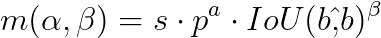
- ( p ) is the classification score
- ( beta and beta hat) are the predicted and ground truth bounding boxes
- ( s ) is the Spatial prior
- ( alpha ) and ( beta ) are the hyperparameters for balancing classification and localization
By setting the one-to-one parameters proportional to the one-to-many parameters
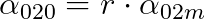
and
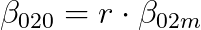
The matching metric aligns both branches to identify the same best positive samples. This alignment helps reduce the supervision gap and improve performance.
This consistent matching metric ensures that the predictions selected by the one-to-one branch are highly in line with the top predictions of the one-to-many branch, resulting in more effective optimization. Thus, this metric demonstrates improved supervision and better model performance.
Model Architecture
YOLOv10 consists of the components below, which are the key factors for model designs and help to achieve efficiency and accuracy.
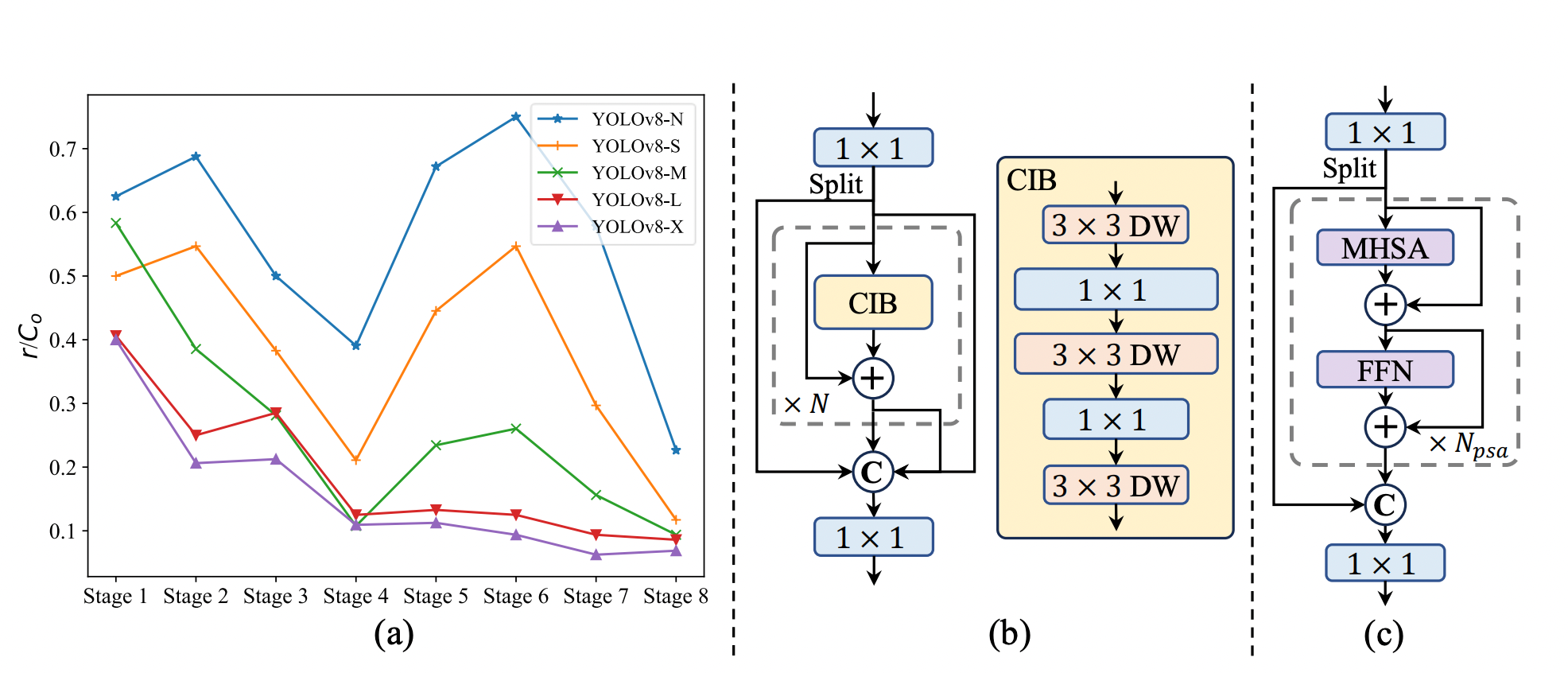
- Lightweight classification head: A lightweight classification head architecture comprises two depthwise separable convolutions (3×3) followed by a 1×1 convolution. This reduces computational demand and makes the model faster and more efficient, particularly beneficial for real-time applications and deployment on devices with limited resources.
- Spatial-channel decoupled downsampling: In YOLO models, downsampling (reducing the size of the image while increasing the number of channels) is usually done using 3×3 standard convolutions with a stride of 2. This process is computationally expensive and requires a lot of parameters.
To make this process more efficient, Spatial-channel decoupled downsampling is proposed and includes two steps:
- Pointwise Convolution: This step adjusts the number of channels without changing the image size.
- Depthwise Convolution: This step reduces the image size (downsampling) without significantly increasing the number of computations or parameters.
Decoupling these operations significantly reduces the computational cost and the number of parameters needed. This approach retains more information during downsampling, leading to better performance with lower latency.
- Rank-guided block design: The rank-guided block allocation strategy optimizes efficiency while maintaining performance. Stages are sorted by intrinsic rank, and the basic block in the most redundant stage is replaced with the CIB. This process continues until a performance drop is detected. This adaptive approach ensures efficient block designs across stages and model scales, achieving higher efficiency without compromising performance. Further algorithm details are provided in the appendix.
- Large-kernel convolution: The approach leverages large-kernel depthwise convolutions selectively in deeper stages to enhance model capability while avoiding issues with shallow feature contamination and increased latency. The use of structural reparameterization ensures better optimization during training without affecting inference efficiency. Additionally, large-kernel convolutions are adapted based on model size, optimizing performance and efficiency.
- Partial self-attention (PSA): The Partial Self-Attention (PSA) module efficiently integrates self-attention into YOLO models. By selectively applying self-attention to only part of the feature map and optimizing the attention mechanism, PSA enhances the model's global representation learning with minimal computational cost. This approach ensures improved performance without the excessive overhead typical of full self-attention mechanisms.
Comparison with SOTA Models
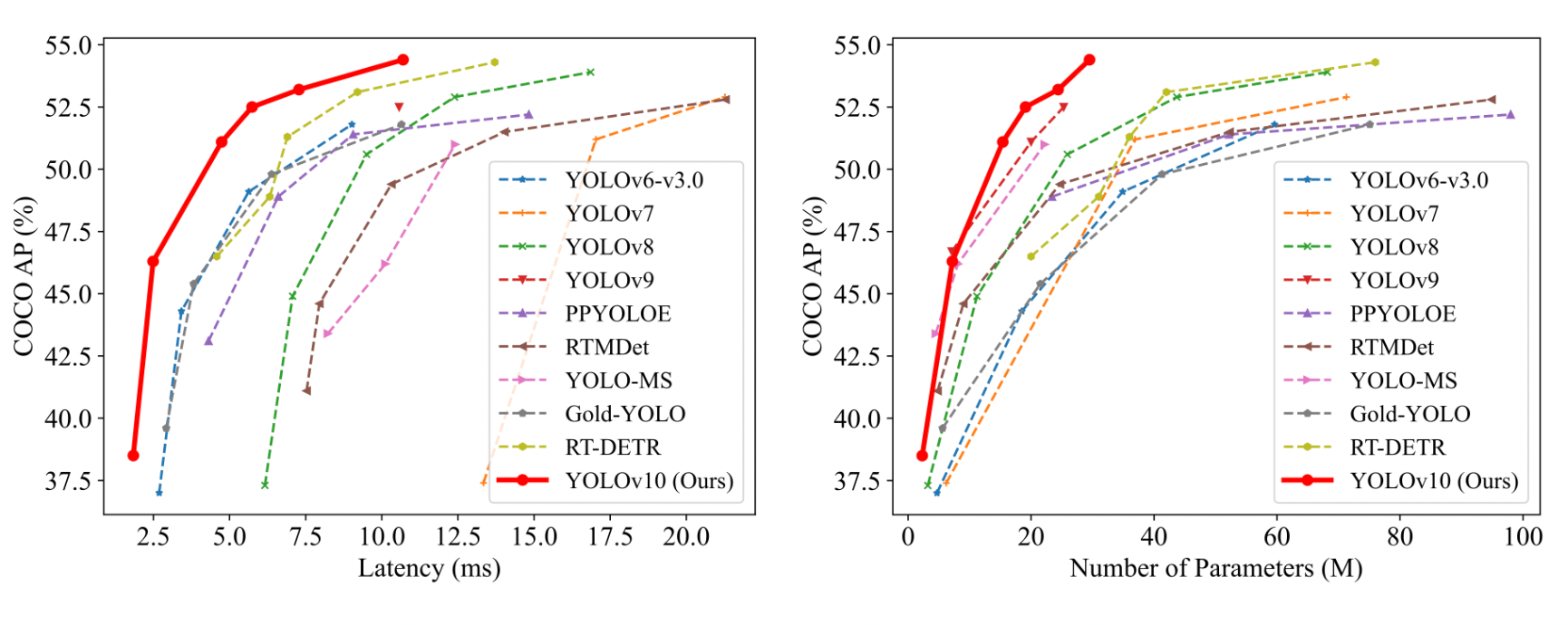
YOLOv10 successfully achieves state-of-the-art performance and end-to-end latency across various model scales. Compared to the baseline YOLOv8 models, YOLOv10 significantly improves Average Precision (AP) and efficiency. Specifically, YOLOv10 variants (N/S/M/L/X) achieve 1.2% to 1.4% AP improvements, with 28% to 57% fewer parameters, 23% to 38% fewer computations, and 37% to 70% lower latencies.
When compared to other YOLO models, YOLOv10 demonstrates superior trade-offs between accuracy and computational cost. YOLOv10-N and S outperform YOLOv6-3.0-N and S by 1.5 and 2.0 AP, respectively, with significantly fewer parameters and computations. YOLOv10-B and M reduce latency by 46% and 62%, respectively, compared to YOLOv9-C and YOLO-MS while maintaining or improving performance. YOLOv10-L surpasses Gold-YOLO-L with 68% fewer parameters, 32% lower latency, and a 1.4% AP improvement.
Additionally, YOLOv10 significantly outperforms RT-DETR in both performance and latency. YOLOv10-S and X are 1.8× and 1.3× faster than RT-DETR-R18 and R101, respectively, with similar performance.
These results highlight YOLOv10's superiority as a real-time end-to-end detector, demonstrating state-of-the-art performance and efficiency across different model scales. This effectiveness is further validated when using the original one-to-many training approach, confirming the impact of our architectural designs.
Paperspace Demo
Bring this project to life
To run YOLOv10 using Paperspace, we will first clone the repo and install the necessary packages.
!pip install -q git+https://github.com/THU-MIG/yolov10.gitCurrently, YOLOv10 does not have its own PyPI package. Therefore, we need to install the code from the source.
But before we start, let us verify the GPU we are using.
!nvidia-smi
Next, install the necessary libraries,
!pip install -r requirements.txt
!pip install -e .
These installations are necessary to ensure that the model has all the necessary tools and libraries to function correctly.
!wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10s.pt
When we run this command, wget will access the URL provided, download the pre-trained weights of the YOLOv10 small model yolov10s.pt, and save it in the current directory.
Once done we will run the app.py file to generate the url.
python app.pyObject detection tasks using YOLOv10
Inference on Images
YOLOv10 provides weight files pre-trained on the COCO dataset in various sizes. First we will download the weights.
!mkdir -p {HOME}/weights
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10n.pt
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10s.pt
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10m.pt
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10b.pt
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10x.pt
!wget -P {HOME}/weights -q https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10l.pt
!ls -lh {HOME}/weightsNext lines of code will use the YOLO model to process the input image dog.jpeg, detect the objects within it based on the model's training, and save the output image with detected objects highlighted. The results will be stored in the specified directory.
%cd {HOME}
!yolo task=detect mode=predict conf=0.25 save=True \
model={HOME}/weights/yolov10n.pt \
source={HOME}/data/dog.jpeg
import cv2
import supervision as sv
from ultralytics import YOLOv10
model = YOLOv10(f'{HOME}/weights/yolov10n.pt')
image = cv2.imread(f'{HOME}/data/dog.jpeg')
results = model(image)[0]
detections = sv.Detections.from_ultralytics(results)
bounding_box_annotator = sv.BoundingBoxAnnotator()
label_annotator = sv.LabelAnnotator()
annotated_image = bounding_box_annotator.annotate(
scene=image, detections=detections)
annotated_image = label_annotator.annotate(
scene=annotated_image, detections=detections)
sv.plot_image(annotated_image)
0: 640x384 1 person, 1 dog, 8.3ms
Speed: 1.8ms preprocess, 8.3ms inference, 0.9ms postprocess per image at shape (1, 3, 640, 384)
This cell runs inference using the YOLOv10 model on an input image, processes the results to extract detections, and annotates the image with bounding boxes and labels using the supervision library to display the results.
Conclusion
In this blog, we discussed about YOLOv10, a new member in the YOLO series. YOLOv10 has adapted advancement in both post-processing and model architecture of YOLOs for object detection. The major approach includes NMS-free training with consistent dual assignments for more efficient detection. These improvements result in YOLOv10, a real-time object detector that outperforms other advanced detectors in both performance and latency.
We hope you enjoyed the article! Keep an eye out for part 2 of our blog, where we'll be comparing YOLOv10 with other YOLO models.









